线程池
什么是线程池?
线程池,thread pool,是一种线程使用模式
为什么要使用线程池?
1:降低资源的消耗,降低线程的创建和销毁的资源消耗
2:提高响应速度,假设线程的创建时间为T1,执行时间为T2,销毁时间为T3,如果是自己创建线程必然会经历,这三个时间,那么如果创建+销毁>执行,就会有大量时间用在创建和销毁上,而不是在执行任务上,而线程池关注的就是调整T1和T3的时间,线程池可以免去T1和T3的时间
3:提高线程的可管理性
不如先来实现一个自己的线程池
思想:
1:为了优化T1和T3的时间,在使用前,线程必须在池中已经创建好了,并且可以保持住,既然要保存住,那么就需要一个容器
2:里面的线程如果是只能跑已经在内部写好的代码,那么就没有意义,所以它必须能接收外部的任务,运行这个任务
3:外部传入的任务数量大于线程的执行个数是,多余的任务如何处理?emmm,用个容器存起来,用阻塞队列吧,上一章刚写了
实现代码:
package com.xiangxue.ch6.mypool; import java.util.LinkedList; import java.util.List; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; /** * 类说明:自己线程池的实现 */ public class MyThreadPool2 { // 线程池中默认线程的个数为5 private static int WORK_NUM = 5; // 队列默认任务个数为100 private static int TASK_COUNT = 100; // 工作线程组 private WorkThread[] workThreads; // 任务队列,作为一个缓冲 private final BlockingQueue<Runnable> taskQueue; private final int worker_num;//用户在构造这个池,希望的启动的线程数 // 创建具有默认线程个数的线程池 public MyThreadPool2() { this(WORK_NUM, TASK_COUNT); } // 创建线程池,worker_num为线程池中工作线程的个数 public MyThreadPool2(int worker_num, int taskCount) { if (worker_num <= 0) worker_num = WORK_NUM; if (taskCount <= 0) taskCount = TASK_COUNT; this.worker_num = worker_num; taskQueue = new ArrayBlockingQueue<>(taskCount); workThreads = new WorkThread[worker_num]; for (int i = 0; i < worker_num; i++) { workThreads[i] = new WorkThread(); workThreads[i].start(); } Runtime.getRuntime().availableProcessors(); } // 执行任务,其实只是把任务加入任务队列,什么时候执行有线程池管理器决定 public void execute(Runnable task) { try { taskQueue.put(task); } catch (InterruptedException e) { e.printStackTrace(); } } // 销毁线程池,该方法保证在所有任务都完成的情况下才销毁所有线程,否则等待任务完成才销毁 public void destroy() { // 工作线程停止工作,且置为null System.out.println("ready close pool....."); for (int i = 0; i < worker_num; i++) { workThreads[i].stopWorker(); workThreads[i] = null;//help gc } taskQueue.clear();// 清空任务队列 } // 覆盖toString方法,返回线程池信息:工作线程个数和已完成任务个数 @Override public String toString() { return "WorkThread number:" + worker_num + " wait task number:" + taskQueue.size(); } /** * 内部类,工作线程 */ private class WorkThread extends Thread { @Override public void run() { Runnable r = null; try { while (!isInterrupted()) { r = taskQueue.take(); if (r != null) { System.out.println(getId() + " ready exec :" + r); r.run(); } r = null;//help gc; } } catch (Exception e) { // TODO: handle exception } } public void stopWorker() { interrupt(); } } }
JDK中的线程池和工作机制
线程池的创建
ThreadPoolExecutor,jdk所有线程池实现的父类
各个参数的意义
int corePoolSize:线程池核心线程数,池内线程数 < corePoolSize,就会创建新线程, = corePoolSize 就会一直保存这个数量的线程,等以后有任务就会执行,多余的任务会保存在BlockingQueue中
int maximumPoolSize:线程池允许的最大线程数,如果阻塞队列也满了, < maximumPoolSize的时候就会再次创建新的线程,但是不会 > maximumPoolSize
long keepAliveTime:线程空闲下来的存活时间,这个数值,只有在线程池内的线程数量 > corePoolSize的时候才会有作用,它决定着 > corePoolSize数量的线程的空闲下来的存活时间
TimeUnit unit:存活时间单位
BlockingQueue<Runnable> workQueue:保存任务的阻塞队列
ThreadFactory threadFactory:创建线程的工厂,给新创建的线程赋予名字
RejectedExecutionHandler handler: 线程池的饱和策略,当线程池的最大允许数被沾满了,阻塞队列也沾满了,那么再放入任务如何处理
饱和策略:
AbortPolicy:直接抛出异常
CallerRunsPolicy:用调用者所在的线程执行任务
DiscardOldestPolicy:丢弃阻塞队列中最老的任务,也就是最靠前的任务
DiscardPolicy:当前任务直接丢弃
如果这个策略都不是你想要的,可以自己实现 RejectedExecutionHandler 接口,来完成自己的策略,比如写数据库,写日志,或者缓存到其他的里面,等以后再捡回来
注意:刚初始化的线程池当中是没有线程的,只有当往里面投递任务才会创建,如果想一行来就让里面的线程数等于corePoolSize可以调用prestartAllCoreThreads方法
提交任务
void execute(Runnable command):用于提交无返回的任务
Future<T> submit(Callable<T> task):用于提交带返回值的任务
关闭线程池
shutdown(),shutdownNow()
shutdownNow(),设置线程池的状态,还会尝试停止正在运行或者暂停任务的线程
shutdown()设置线程池状态,只会中断所有没有执行任务的线程
工作机制
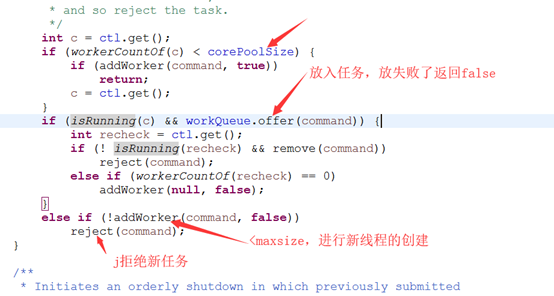
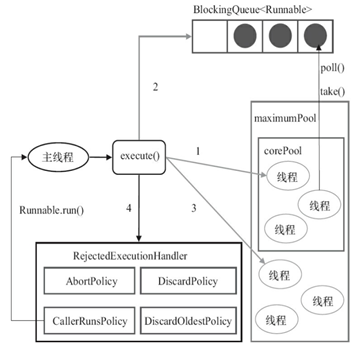
在加入任务的会后会先判断一下当前线程池中的核心线程数时候小于corePoolSize,如果小于,创建新的线程如果大于尝试放入阻塞队列中,如果场入失败,那么将尝试创建新的线程用于运行任务,如果创建新的线程也失败的话,那么将执行饱和策略
合理配置线程池
根据任务的性质来:计算密集型(CPU),IO密集型,混合型
计算密集型:
加密,大数分解,正则.....,线程数适当小一些,
最大推荐:机器的Cpu核心数+1,为什么要+1,防止页缺失
JAVA获取CPU核心数:
Runtime.getRuntime().availableProcessors();
IO密集型:
读取文件,数据库连接,网络通讯,线程数适当大一些
最大推荐:机器的CPU核心数*2
混合型:
尽量拆分,IO密集型远远大于计算密集型,拆分意义不大,IO密级型~计算密级型,拆分才有意义
注意:队列的选择上应该使用有界队列,无界队列可能会导致内存溢出,OOM
预定义的线程池:
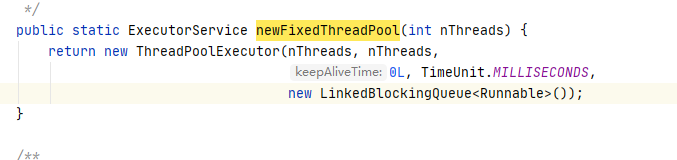
FixedThreadPool:
创建固定线程数量的,适用于负载较重的服务器,使用了LinkedBlockingQueue作为阻塞队列
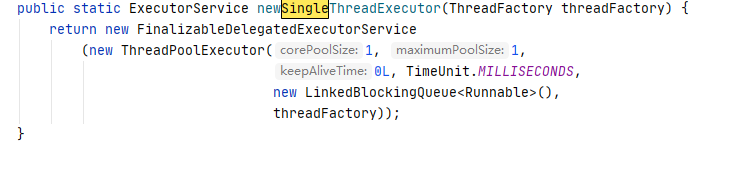
SingleThreadExecutor
创建单个线程,需要保证顺序执行任务,不会有多个线程活动,使用了LinkedBlockingQueue作为阻塞队列
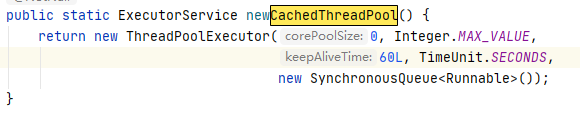
CachedThreadPool
会根据需要来创建新的线程,适用于执行很多很短期异步任务的程序,使用了SynchronousQueue作为阻塞队列
ScheduledThreadPool
需要定期执行周期任务,Timer不建议使用了。
newSingleThreadScheduledExecutor:只包含一个线程,只需要单个线程执行周期任务,保证顺序的执行各个任务
newScheduledThreadPool 可以包含多个线程的,线程执行周期任务,适度控制后台线程数量的时候
方法说明:
schedule:只执行一次,任务还可以延时执行
scheduleAtFixedRate:提交固定时间间隔的任务
scheduleWithFixedDelay:提交固定延时间隔执行的任务
两者的区别:
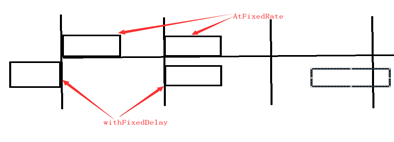
scheduleAtFixedRate任务超时:
规定60s执行一次,有任务执行了80S,下个任务马上开始执行
第一个任务 时长 80s,第二个任务20s,第三个任务 50s
第一个任务第0秒开始,第80S结束;
第二个任务第80s开始,在第100秒结束;
第三个任务第120s秒开始,170秒结束
第四个任务从180s开始
参加代码:ScheduleWorkerTime类,执行效果如图:
建议在提交给ScheduledThreadPoolExecutor的任务要住catch异常。
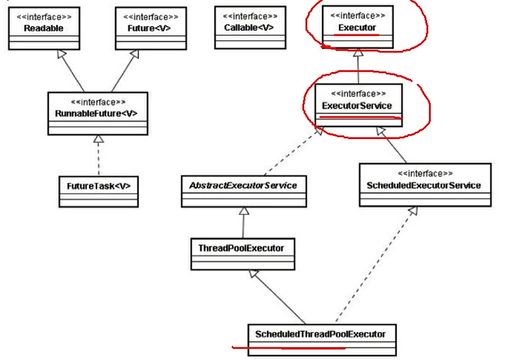
Executor框架图
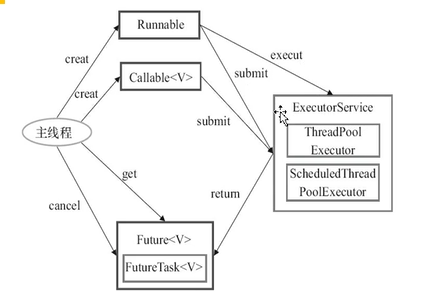
Executor框架基本使用流程
暂时并发编程就写到这里了,后面的并发安全,和JMM模型就先不写了,打算看看别的了
作者:彼岸舞
时间:2021�111
内容关于:并发编程
本文来源于网络,只做技术分享,一概不负任何责任