摘抄:https://www.cnblogs.com/rdst/p/4727063.html
1、case...end (具体的值)
case后面有值,相当于c#中的switch case
注意:case后必须有条件,并且when后面必须是值不能为条件。

-----------------case--end---语法结构---------------------
select name , --注意逗号
case level --case后跟条件
when 1 then '骨灰'
when 2 then '大虾'
when 3 then'菜鸟'
end as'头衔'
from [user]
2、case...end (范围)
case 后面无值,相当于c#中的if...else if...else....
注意:case后不根条件
------------------case---end--------------------------------
select studentId,
case
when english between 80 and 90 then '优'
when english between 60 and 79 then '良'
else '差'
end
from Score
------------------case---end--------------------------------
select studentId,
case
when english >=80 then '优'
when english >=60 then '良'
else '差'
end
from Score
-----------------------------------------------------
select *,
case
when english>=60 and math >=60 then '及格'
else '不及格'
end
from Score
3、if...eles
IF(条件表达式)
BEGIN --相当于C#里的{
语句1
……
END --相当于C#里的}
ELSE
BEGIN
语句1
……
END
--计算平均分数并输出,如果平均分数超过分输出成绩最高的三个学生的成绩,否则输出后三名的学生
declare @avg int --定义变量
select @avg= AVG(english) from Score --为变量赋值
select '平均成绩'+CONVERT(varchar,@avg) --打印变量的值
if @avg<60
begin
select '前三名'
select top 3 * from Score order by english desc
end
else
begin
select '后三名'
select top 3 * from Score order by english
end
4、while循环
WHILE(条件表达式)
BEGIN --相当于C#里的{
语句
……
BREAK
END --相当于C#里的}
--如果不及格的人超过半数(考试题出难了),则给每个人增加分
select * from Score
declare @conut int,@failcount int,@i int=0 --定义变量
select @conut =COUNT(*) from Score --统计总人数
select @failcount =COUNT(*) from Score where english<100 --统计未及格的人数
while (@failcount>@conut/2)
begin
update Score set english=english+1
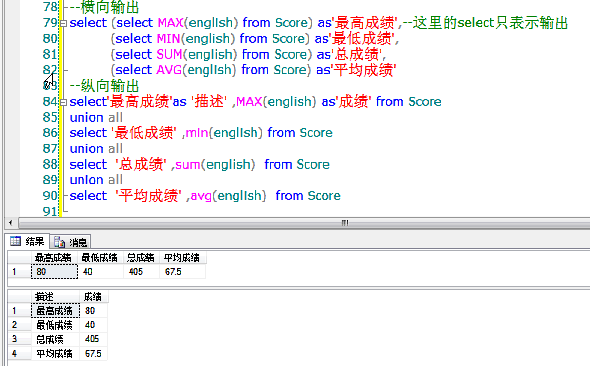
select @failcount=COUNT(*) from Score where english<100
set @i=@i+1
end
select @i
update Score set english=100 where english >100
5、索引
使用索引能提高查询效率,但是索引也是占据空间的,而且添加、更新、删除数据的时候也需要同步更新索引,因此会降低Insert、Update、Delete的速度。只在经常检索的字段上(Where)创建索引。
1)聚集索引:索引目录中的和目录中对应的数据都是有顺序的。
2)非聚集索引:索引目录有顺序但存储的数据是没有顺序的。
--创建非聚集索引
CREATE NONCLUSTERED INDEX [IX_Student_sNo] ON student
(
[sNo] ASC
)
6、子查询
将一个查询语句做为一个结果集供其他SQL语句使用,就像使用普通的表一样,被当作结果集的查询语句被称为子查询。所有可以使用表的地方几乎都可以使用子查询来代替。
select * from (select * from student where sAge<30) as t --被查询的子表必须有别名 where t.sSex ='男' --对子表中的列筛选
转换为两位小数:CONVERT(numeric(10,2), AVG(english))
只有返回且仅返回一行、一列数据的子查询才能当成单值子查询。
select '平均成绩', (select AVG(english) from Score) --可以成功执行
select '姓名', (select sName from student) --错误,因为‘姓名’只有一行,而子表中姓名有多行
select * from student where sClassId in(select cid from Class where cName IN('高一一班','高二一班')) --子查询有多值时使用in
7、分页
--分页1 select top 3 * from student where [sId] not in (select top (3*(4-1)) [sid] from student)--4表示页数 select *, row_number() over(order by [sage] desc ) from student-- row_number() over (order by..)获取行号 --分页2 select * from (select *, row_number() over(order by [sid] desc ) as num from student)as t where num between (Y-1)*T+1 and Y*T order by [sid] desc
--分页3
select * from (select ROW_NUMBER() over( order by [UnitPrice] asc) as num,* from [Books] where [publisherid]=1 )as t where t.num between 1 and 20 --要查询的开始条数和结束条数
8、连接
select sName,sAge,
case
when english <60 then '不及格'
when english IS null then '缺考'
else CONVERT(nvarchar, english)
end as'英语成绩'
from student as s
left join Score as c on s.sid =c.sid
内连接 inner join...on...
查询满足on后面条件的数据
外连接
左连接
left join...on...
先查出左表中的所有数据
再使用on后面的条件对数据过滤
右连接
right join...on...
先查出右表中的所有数据
再使用on后面的条件对数据过滤
全连接
full join ...on...
(*)交叉连接
cross join 没有on
第一个表的每一行和后面表的每一行进行连接
没有条件。是其它连接的基础
9.视图
优点:
- 筛选表中的行
- 防止未经许可的用户访问敏感数据
- 降低数据库的复杂程度
创建视图
create view v_Demo as select ......
10、局部变量
---------------------------------局部变量-------------------------- --声明变量:使用declare关键字,并且变量名已@开头,@直接连接变量名,中间没有空格。必须指明变量的类型,同时还可以声明多个不同类型的变量。 declare @name nvarchar(30) ,@age int --变量赋值: --1、使用set 给变量赋值,只能给一个变量赋值 set @age=18 set @name ='Tianjia' select @age,@name --输出变量的值 --2、使用select 可以同时为多个变量赋值 select @age=19,@name='Laoniu' --3、在查询语句中为变量赋值 declare @sum int =18 --为变量赋初值 select @sum= SUM(english) from Score --查询语句中赋值 select @sum --输出变量值 --4、变量作为条件使用 declare @sname nvarchar(10)='张三' declare @sage int select @sage=sage from student where sName=@sname select @sage --5、使用print输出变量值,一次只能输出一个变量的值,输出为文本形式 print @sage
11、全局变量
--------------------------全局变量(系统变量)---------------------------------- select * from student0 select @@error --最后一个T-SQL错误的错误号 select @@max_connections--获取创建的同时连接的最大数目 select @@identity --返回最近一次插入的编号
12、事务
事务:同生共死
指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)--也就是由多个sql语句组成,必须作为一个整体执行
这些sql语句作为一个整体一起向系统提交,要么都执行、要么都不执行
语法步骤:
- 开始事务:BEGIN TRANSACTION
- 事务提交:COMMIT TRANSACTION
- 事务回滚:ROLLBACK TRANSACTION
判断某条语句执行是否出错:
全局变量@@ERROR;
@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计;
---------------------------模拟转账---------------------------- declare @sumError int=0 --声明变量 begin tran update bank set balance=balance-1000 where cId='0001' set @sumError=@sumError+@@error update bank set balance=balance+1000 where cId='0002' set @sumError=@sumError+@@error if (@sumError=0) commit tran --提交成功,提交事务 else rollback tran --提交失败,回滚事务
13、存储过程
存储过程---就像数据库中运行方法(函数)
和C#里的方法一样,由存储过程名/存储过程参数组成/可以有返回结果。
前面学的if else/while/变量/insert/select 等,都可以在存储过程中使用
优点:
- 执行速度更快 - 在数据库中保存的存储过程语句都是编译过的
- 允许模块化程序设计 - 类似方法的复用
- 提高系统安全性 - 防止SQL注入
- 减少网络流通量 - 只要传输 存储过程的名称
系统存储过程
由系统定义,存放在master数据库中
名称以“sp_”开头或”xp_”开头
创建存储过程:
定义存储过程的语法
CREATE PROC[EDURE] 存储过程名
@参数1 数据类型 = 默认值 OUTPUT,
@参数n 数据类型 = 默认值 OUTPUT
AS
SQL语句
参数说明:
参数可选
参数分为输入参数、输出参数
输入参数允许有默认值
EXEC 过程名 [参数]
----------------------例--------------------------
if exists (select * from sys.objects where name='usp_GroupMainlist1')
drop proc usp_GroupMainlist1
go
create proc usp_GroupMainlist1
@pageIndex int, --页数
@pageSize int, --条数
@pageCount int output--输出共多少页
as
declare @count int --共多少条数据
select @count =count(*) from [mainlist] --获取此表的总条数
set @pageCount=ceiling(@count*1.0/@pageSize)
select * from
(select *,row_number() over(order by [date of booking] desc) as 'num' from [mainlist]) as t
where num between(@pageSize*(@pageIndex-1)+1) and @pageSize*@pageIndex
order by [date of booking] desc
-------------------------------------------------------------------------------------------
--调用
declare @page int
exec usp_GroupMainlist1 1,100,@page output
select @page
14、常用函数
1)ISNULL(expression,value) 如果expression不为null返回expression表达式的值,否则返回value的值
2)聚合函数
avg() -- 平均值 统计时注意null不会被统计,需要加上isnull(列名,0) sum() -- 求和 count() -- 求行数 min() -- 求最小值 max() -- 求最大值
3)字符串操作函数
LEN() --计算字符串长度
LOWER() --转小写
UPPER () --大写
LTRIM() --字符串左侧的空格去掉
RTRIM () --字符串右侧的空格去掉
LTRIM(RTRIM(' bb '))
LEFT()、RIGHT() -- 截取取字符串
SUBSTRING(string,start_position,length)
-- 参数string为主字符串,start_position为子字符串在主字符串中的起始位置(从1开始),length为子字符串的最大长度。
SELECT SUBSTRING('abcdef111',2,3)
REPLACE(string,oldstr,newstr)
Convert(decimal(18,2),num)--保留两位小数
4)日期相关函数
GETDATE() --取得当前日期时间 DATEADD (datepart , number, date )--计算增加以后的日期。参数date为待计算的日期;参数number为增量;参数datepart为计量单位,可选值见备注。DATEADD(DAY, 3,date)为计算日期date的3天后的日期,而DATEADD(MONTH ,-8,date)为计算日期date的8个月之前的日期 DATEDIFF ( datepart , startdate , enddate ) --计算两个日期之间的差额。 datepart 为计量单位,可取值参考DateAdd。 -- 获取日期的某一部分 : DATEPART (datepart,date)--返回一个日期的特定部分 整数 DATENAME(datepart,date)--返回日期中指定部分 字符串 YEAR() MONTH() DAY()
15、sql语句执行顺序
5>…Select 5-1>选择列,5-2>distinct,5-3>top 1>…From 表 2>…Where 条件 3>…Group by 列 4>…Having 筛选条件 6>…Order by 列
---------------------以下是根据园友建议后续补充的,部分为项目中的实际代码(没时间写整理直接贴源码)---------------------------
16、分组查询group by...having
对group by分组后的数据进行过滤在分组查询中,查询的列名必须出现在group by后或者在聚合函数中
--查询平均工资大于两千块钱的部门
select department_id,avg(wages)
from employee
where department_id is not null
group by department_id
having avg(wages)>2000
17、临时表[转]
方法一:
create table #临时表名(字段1 约束条件,
字段2 约束条件,
.....)
create table ##临时表名(字段1 约束条件,
字段2 约束条件,
.....)
方法二:
select * into #临时表名 from 你的表;
select * into ##临时表名 from 你的表;
注:以上的#代表局部临时表,##代表全局临时表
drop table #Tmp --删除临时表#Tmp
create table #Tmp --创建临时表#Tmp
(
ID int IDENTITY (1,1) not null, --创建列ID,并且每次新增一条记录就会加1
WokNo varchar(50),
primary key (ID) --定义ID为临时表#Tmp的主键
);
Select * from #Tmp --查询临时表的数据
truncate table #Tmp --清空临时表的所有数据和约束
详细说明:http://www.cnblogs.com/Hdsome/archive/2008/12/10/1351504.html
18、表值函数
Create FUNCTION [dbo].[GetUPR]
(
@upr varchar(2) --传入函数中的参数
)
RETURNS @tab TABLE
(
UPR varchar(2) --返回表的字段,这里只有一个字段
)
AS
BEGIN
if(@upr='0')
begin
insert @tab
select 'U'
union select 'P'
union select 'R'
end
else
begin
insert @tab
select @upr
end
RETURN ;
END
19、标量值函数
-- =============================================
-- 根据订单号获取销售员1的邮箱
-- =============================================
Create FUNCTION [dbo].[GetSalManAEmailByOrderNo]
(
@orderNo varchar(16)
)
RETURNS varchar(128)
AS
BEGIN
declare @salManAEmail varchar(128)
select @salManAEmail=EMailA from UserDB.dbo.EmployeeInfo where EmployeeID in
(
select EmployeeInfoID from SalesManInfo where SalesManCode in
(
select SalesManA from OrderInfo where SalesOrder=@orderNo
)
)
RETURN ( @salManAEmail)
END
20、触发器[转]
触发器定义
- 触发器是一种特殊类型的存储过程,它不能被显式地调用,而是在往表中插入记录﹑更新记录或者删除记录时被自动地激活,可以理解为对数据库的某个表进行操作时会自动执行的存储过程,触发器可以指定其被调用的条件,只要满足条件,触发器就会被调用
触发器条件
- insert
- update
- delete
何时触发
- instead of :在sql语句执行前触发
- after: sql语句执行完成后再触发
CREATE TRIGGER trigger_name
ON {table_name | view_name}
{FOR | After | Instead of } [ insert, update,delete ]
AS
sql_statement
create trigger Tri_DeleteUser on User after delete as delete from XXX.dbo.UserAccount where guid = (select guid from deleted)
21、游标
游标的使用分为5步:
1、声明游标
2、打开游标
3、读取游标中的数据
4、关闭游标
5、释放游标
游标是SQL Server的一种数据访问机制,它允许用户访问单独的数据行。用户可以对每一行进行单独的处理,从而降低系统开销和潜在的阻隔情况,用户也可以使用这些数据生成的SQL代码并立即执行或输出。
1.游标的概念
游标是一种处理数据的方法,主要用于存储过程,触发器和 T_SQL脚本中,它们使结果集的内容可用于其它T_SQL语句。在查看或处理结果集中向前或向后浏览数据的功能。类似与C语言中的指针,它可以指向结果集中的任意位置,当要对结果集进行逐条单独处理时,必须声明一个指向该结果集中的游标变量。
SQL Server 中的数据操作结果都是面向集合的,并没有一种描述表中单一记录的表达形式,除非使用WHERE子句限定查询结果,使用游标可以提供这种功能,并且游标的使用和操作过程更加灵活、高效。
create proc [dbo].[游标存储] as begin declare cursor1 cursor for --创建一个游标叫cursor1 SELECT [seller_id] FROM [test].[dbo].[Sales] where [seller_id]=1 --将查询的结果给游标对象cursor1 open cursor1 --打开游标 declare @id int declare @ids int --定义参数 FETCH NEXT FROM cursor1 --读取结果集的下一条数据 INTO @id ; --这里的字段要和上面的游标对象一模一样 WHILE @@FETCH_STATUS=0 BEGIN --用于检测当前连接上的所有游标对象的状态 if @id>1 select @ids=99 else select @ids=0 UPDATE [Sales] SET buyer_id=@ids WHERE [seller_id]=@id; FETCH NEXT FROM cursor1 INTO @id END; CLOSE cursor1; --关闭游标 DEALLOCATE cursor1;--释放游标 --select @id select @@FETCH_STATUS --游标函数 返回针对链接当前打开的任何游标发出的上一条游标FETCH语句的状态 select @@CURSOR_ROWS --游标函数 上一个游标中的当前限定行的数目 select CURSOR_STATUS('local','cursor1')--游标函数 允许存储过程的调用方确定该存储过程是否已为给定的参数返回了游标和结果集 end
22、exists
EXISTS运算符是一个逻辑运算符,用于检查子查询是否返回任何行。 如果子查询返回一行或多行,则EXISTS运算符返回TRUE。在此语法中,子查询仅是SELECT语句。子查询返回行后,EXISTS运算符返回TRUE并立即停止处理。
请注意,即使子查询返回NULL值,EXISTS运算符也会计算为TRUE。
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
EXISTS 指定一个子查询,检测 行 的存在。
对于EXISTS,它采用的是二值逻辑(TRUE和FALSE),它只关心是否存在匹配行,而不考虑SELECT列表中指定的列,并且无须处理所有满足条件的行。可以将这种处理方式看做是一种“短路”,它能够提高处理效率。另外,由于EXISTS采用的是二值逻辑,因此相较于IN要更加安全,可以避免对NULL值得处理。
select * from TableIn where exists(select null)
等同于: select * from TableIn
select*from Sales s where exists (select*from Sales where seller_id=s.seller_id)
select*from Sales s where exists (select*from Sales where seller_id=1)
select*from Sales s where exists (select 1)
select*from Sales s where not exists (select 1)
select*from Sales s where not exists (select*from Sales where seller_id=113.12321)
23、删除数据重复项
1.没有主键id时
with DupsNumbered
as(
select seller_id,buyer_id,
row_number()over( partition by seller_id,buyer_id order by seller_id) as rn
from Sales
)
delete DupsNumbered where rn>1;
或者采用 select distinct *from Sales 存入到临时表 然后清空 Sales 然后再从临时表取数据 最后删除临时表
2.有主键时
Delete Test1 From
(Select Row_Number() Over(Partition By[Name]order By[ID]) As RowNumber,*From Test1)T
Where T.RowNumber >1
Delete from Test1 where ID not in ( select tt.dd from (select Name,MIN(ID) dd from Test1 group by Name) tt )