参考:https://www.cnblogs.com/wuzhenzhao/p/11101555.html
XML 映射文件
本文参考mybatis中文官网进行学习总结:http://www.mybatis.org/mybatis-3/zh/sqlmap-xml.html
MyBatis 的真正强大在于它的映射语句,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 为聚焦于 SQL 而构建,以尽可能地为你减少麻烦。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
- cache – 对给定命名空间的缓存配置。
- cache-ref – 对其他命名空间缓存配置的引用。
- resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
select
查询语句是 MyBatis 中最常用的元素之一,光能把数据存到数据库中价值并不大,只有还能重新取出来才有用,多数应用也都是查询比修改要频繁。对每个插入、更新或删除操作,通常间隔多个查询操作。这是 MyBatis 的基本原则之一,也是将焦点和努力放在查询和结果映射的原因。简单查询的 select 元素是非常简单的。比如:

<resultMap id="BaseResultMap" type="blog">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<result column="author_id" property="authorId" jdbcType="INTEGER"/>
</resultMap>
<!--****************************************************************************************-->
<!--简单查询-->
<select id="selectBlogById" resultMap="BaseResultMap" statementType="PREPARED" useCache="false">
select * from blog where bid = #{bid}
</select>
#{bid} 这就告诉 MyBatis 创建一个预处理语句(PreparedStatement)参数,在 JDBC 中,这样的一个参数在 SQL 中会由一个“?”来标识,并被传递到一个新的预处理语句中,就像这样:
// 近似的 JDBC 代码,非 MyBatis 代码...
String selectBlogById= "SELECT * FROM BLOG WHERE BID=?";
PreparedStatement ps = conn.prepareStatement(selectBlogById);
ps.setInt(1,bid);
当然,使用 JDBC 意味着需要更多的代码来提取结果并将它们映射到对象实例中,而这就是 MyBatis 节省你时间的地方。select 元素允许你配置很多属性来配置每条语句的作用细节。
<select id="selectPerson" parameterType="int" parameterMap="deprecated" resultType="hashmap" resultMap="personResultMap" flushCache="false" useCache="true" timeout="10" fetchSize="256" statementType="PREPARED" resultSetType="FORWARD_ONLY">
相关属性描述:
| 属性 | 描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数,默认值为未设置(unset)。 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。可以使用 resultType 或 resultMap,但不能同时使用。 |
| resultMap | 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂映射的情形都能迎刃而解。可以使用 resultMap 或 resultType,但不能同时使用。 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。 |
| useCache | 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动)。 |
| fetchSize | 这是一个给驱动的提示,尝试让驱动程序每次批量返回的结果行数和这个设置值相等。 默认值为未设置(unset)(依赖驱动)。 |
| statementType | STATEMENT,PREPARED 或 CALLABLE 中的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖驱动)。 |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
| resultOrdered | 这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。 这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。 |
| resultSets | 这个设置仅对多结果集的情况适用。它将列出语句执行后返回的结果集并给每个结果集一个名称,名称是逗号分隔的。 |
insert, update 和 delete:
数据变更语句 insert,update 和 delete 的实现非常接近:
<insert id="insertAuthor" parameterType="domain.blog.Author" flushCache="true" statementType="PREPARED" keyProperty="" keyColumn="" useGeneratedKeys="" timeout="20"> <update id="updateAuthor" parameterType="domain.blog.Author" flushCache="true" statementType="PREPARED" timeout="20"> <delete id="deleteAuthor" parameterType="domain.blog.Author" flushCache="true" statementType="PREPARED" timeout="20">
相关属性描述:
| 属性 | 描述 |
|---|---|
| id | 命名空间中的唯一标识符,可被用来代表这条语句。 |
| parameterType | 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器推断出具体传入语句的参数,默认值为未设置(unset)。 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:true(对于 insert、update 和 delete 语句)。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动)。 |
| statementType | STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| useGeneratedKeys | (仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 |
| keyProperty | (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认值:未设置(unset)。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyColumn | (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望使用多个生成的列,也可以设置为逗号分隔的属性名称列表。 |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
下面就是 insert,update 和 delete 语句的示例:
<insert id="insertAuthor">
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
</insert>
<update id="updateAuthor">
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
</update>
<delete id="deleteAuthor">
delete from Author where id = #{id}
</delete>
如前所述,插入语句的配置规则更加丰富,在插入语句里面有一些额外的属性和子元素用来处理主键的生成,而且有多种生成方式。首先,如果你的数据库支持自动生成主键的字段(比如 MySQL 和 SQL Server),那么你可以设置 useGeneratedKeys=”true”,然后再把 keyProperty 设置到目标属性上就 OK 了。如果你的数据库还支持多行插入, 你也可以传入一个 Blog数组或集合,并返回自动生成的主键。
<!--批量插入-->
<insert id="insertBlogs" useGeneratedKeys="true"
keyProperty="bid">
insert into blog (name, author_id) values
<foreach item="item" collection="list" separator=",">
(#{item.name}, #{item.authorId})
</foreach>
</insert>
sql
这个元素可以被用来定义可重用的 SQL 代码段,这些 SQL 代码可以被包含在其他语句中。它可以(在加载的时候)被静态地设置参数。 在不同的包含语句中可以设置不同的值到参数占位符上。mybatis中sql标签与include标签进行配合,灵活的查询需要的数据。
<sql id="ref">
bid,name,authorId
</sql>
<select id="selectbyId" resultMap="BaseResultMap">
select
<include refid="ref"/>
from
blog where bid = #{bid}
</select>
sql标签中id属性对应include标签中的refid属性。通过include标签将sql片段和原sql片段进行拼接成一个完成的sql语句进行执行。include标签中还可以用property标签,用以指定自定义属性。
<select id="selectbyId" resultMap="BaseResultMap">
select
<include refid="ref">
<property name="abc" value="bid"/>
</include>
from
blog where bid = #{bid}
</select>
此时,可以在sql标签中取出对应设置的自定义属性中的值,例如接上代码例子:
<sql id="ref">
${abc},name,authorId
</sql>
<select id="selectbyId" resultMap="BaseResultMap">
select
<include refid="ref">
<property name="abc" value="bid"/>
</include>
from
blog where bid = #{bid}
</select>
在sql标签中通过${}取出对应include标签中设置的属性值。
关联(association)元素处理“有一个”类型的关系。 比如,在我们的示例中,一个博客有一个用户。关联结果映射和其它类型的映射工作方式差不多。 你需要指定目标属性名以及属性的javaType(很多时候 MyBatis 可以自己推断出来),在必要的情况下你还可以设置 JDBC 类型,如果你想覆盖获取结果值的过程,还可以设置类型处理器。关联的不同之处是,你需要告诉 MyBatis 如何加载关联。MyBatis 有两种不同的方式加载关联:
- 嵌套 Select 查询:通过执行另外一个 SQL 映射语句来加载期望的复杂类型。
- 嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集。
关联的嵌套 Select 查询
<!-- 另一种联合查询(一对一)的实现,但是这种方式有“N+1”的问题 -->
<resultMap id="BlogWithAuthorQueryMap" type="com.wuzz.demo.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<association property="author" javaType="com.wuzz.demo.entity.Author"
column="author_id" select="selectAuthor"/>
</resultMap>
<!-- 嵌套查询 -->
<select id="selectAuthor" parameterType="int" resultType="com.wuzz.demo.entity.Author">
select author_id authorId, author_name authorName
from author where author_id = #{authorId}
</select>
<!-- 根据文章查询作者,一对一,嵌套查询,存在N+1问题,可通过开启延迟加载解决 -->
<select id="selectBlogWithAuthorQuery" resultMap="BlogWithAuthorQueryMap" >
select b.bid, b.name, b.author_id, a.author_id , a.author_name
from blog b
left join author a
on b.author_id=a.author_id
where b.bid = #{bid, jdbcType=INTEGER}
</select>
就是这么简单。我们有两个 select 查询语句:一个用来加载博客(Blog),另外一个用来加载作者(Author),而且博客的结果映射描述了应该使用 selectAuthor 语句加载它的 author 属性。其它所有的属性将会被自动加载,只要它们的列名和属性名相匹配。这种方式虽然很简单,但在大型数据集或大型数据表上表现不佳。这个问题被称为“N+1 查询问题”。 概括地讲,N+1 查询问题是这样子的:
- 你执行了一个单独的 SQL 语句来获取结果的一个列表(就是“+1”)。
- 对列表返回的每条记录,你执行一个 select 查询语句来为每条记录加载详细信息(就是“N”)。
这个问题会导致成百上千的 SQL 语句被执行。有时候,我们不希望产生这样的后果。MyBatis 能够对这样的查询进行延迟加载,因此可以将大量语句同时运行的开销分散开来。mybatis.configuration.lazy-loading-enabled=true 可以开启延时加载 mybatis.configuration.aggressive-lazy-loading=true 可以指定哪些方法调用查询, 然而,如果你加载记录列表之后立刻就遍历列表以获取嵌套的数据,就会触发所有的延迟加载查询,性能可能会变得很糟糕。所以还有另外一种方法。
关联的嵌套结果映射
<!-- 根据文章查询作者,一对一查询的结果,嵌套查询 -->
<resultMap id="BlogWithAuthorResultMap" type="com.wuzz.demo.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<!-- 联合查询,将author的属性映射到ResultMap -->
<association property="author" javaType="com.wuzz.demo.entity.Author">
<id column="author_id" property="authorId"/>
<result column="author_name" property="authorName"/>
</association>
</resultMap>
<!-- 根据文章查询作者,一对一,嵌套结果,无N+1问题 -->
<select id="selectBlogWithAuthorResult" resultMap="BlogWithAuthorResultMap" >
select b.bid, b.name, b.author_id, a.author_id , a.author_name
from blog b,author a
where b.author_id=a.author_id and b.bid = #{bid, jdbcType=INTEGER}
</select>
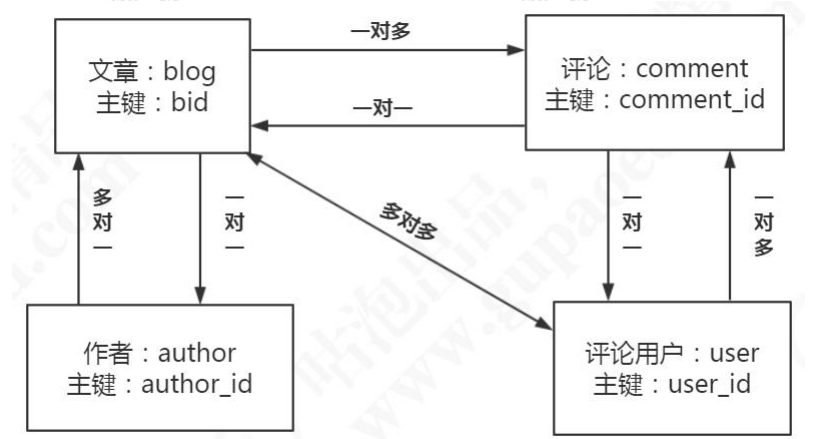
查询文章带评论的结果(一对多)映射:
<!-- 查询文章带评论的结果(一对多) -->
<resultMap id="BlogWithCommentMap" type="com.wuzz.demo.associate.BlogAndComment" extends="BaseResultMap" >
<collection property="comment" ofType="com.wuzz.demo.entity.Comment">
<id column="comment_id" property="commentId" />
<result column="content" property="content" />
<result column="bid" property="bid" />
</collection>
</resultMap>
<!-- 根据文章查询评论,一对多 -->
<select id="selectBlogWithCommentById" resultMap="BlogWithCommentMap" >
select b.bid, b.name, b.author_id , c.comment_id , c.content,c.bid
from blog b, comment c
where b.bid = c.bid
and b.bid = #{bid}
</select>
按作者查询文章评论的结果(多对多):
<!-- 按作者查询文章评论的结果(多对多) -->
<resultMap id="AuthorWithBlogMap" type="com.wuzz.demo.associate.AuthorAndBlog" >
<id column="author_id" property="authorId" jdbcType="INTEGER"/>
<result column="author_name" property="authorName" jdbcType="VARCHAR"/>
<collection property="blog" ofType="com.wuzz.demo.associate.BlogAndComment">
<id column="bid" property="bid" />
<result column="name" property="name" />
<result column="author_id" property="authorId" />
<collection property="comment" ofType="com.wuzz.demo.entity.Comment">
<id column="comment_id" property="commentId" />
<result column="content" property="content" />
<result column="bid" property="bid" />
</collection>
</collection>
</resultMap>
<!-- 根据作者文章评论,多对多 -->
<select id="selectAuthorWithBlog" resultMap="AuthorWithBlogMap" >
select b.bid, b.name, a.author_id , a.author_name , c.comment_id , c.content,c.bid
from blog b, author a, comment c
where b.author_id = a.author_id and b.bid = c.bid
</select>
动态 SQL
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。虽然在以前使用动态 SQL 并非一件易事,但正是 MyBatis 提供了可以被用在任意 SQL 映射语句中的强大的动态 SQL 语言得以改进这种情形。动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多元素需要花时间了解。MyBatis 3 大大精简了元素种类,现在只需学习原来一半的元素便可。MyBatis 采用功能强大的基于 OGNL 的表达式来淘汰其它大部分元素。
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
其中 choose再实际开发中应用的较少,我们这里就其他3个标签进行测试
<!--动态sql-->
<select id="selectBlogById2" resultMap="BaseResultMap" statementType="PREPARED" useCache="false"
parameterType="blog">
select * from blog
<trim prefix="WHERE" prefixOverrides="AND |OR ">
<if test="bid != null and bid !='' ">
bid = #{bid}
</if>
<if test="name != null and name !='' ">
AND name = #{name}
</if>
<if test="authorId != null and authorId != ''">
AND author_id = #{author_id}
</if>
</trim>
</select>
foreach:动态 SQL 的另外一个常用的操作需求是对一个集合进行遍历,通常是在构建 IN 条件语句的时候。比如:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
</foreach>
</select>