github地址:https://github.com/Fleurrr/personal-project/tree/master/Cplusplus/031602317
1.PSP表格

2.解题思路描述
看到题目,首先罗列出了题目要求我们实现的几个功能。
1.文本读入功能:输入文件名以命令行参数传入。这个功能很容易实现,利用fopen、fgetc等函数可以做到文本按字符读入。
2.字符统计功能:因为我在文本读入时选择的是按字符读入,只需统计读入字符总数即可完成这个功能。
3.行数统计功能:当读入字符为换行符或者是回车符时,统计值加一即 可完成这个功能。
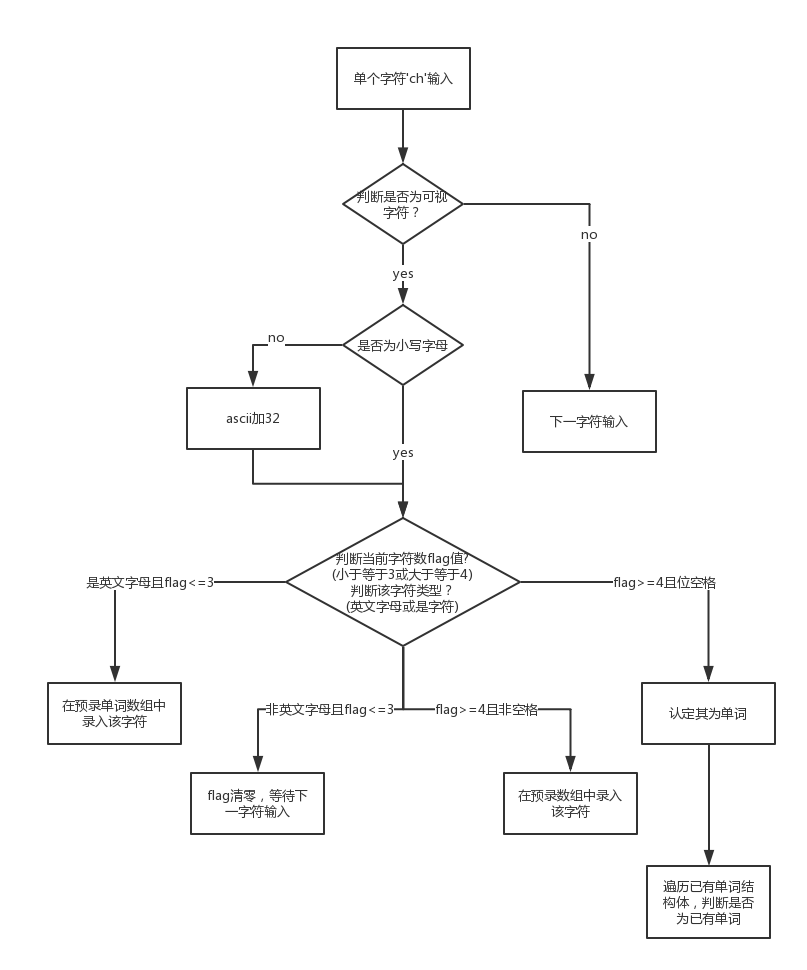
4.单词统计功能:本人没有很强大的代码技巧,又因为在读入文本时已经确定了是按字符读入,所以在单词统计上用了比较死的方法,所以后来和同学交流的过程中发现他们是按行读入并且使用了正则表达式就觉得自己的代码很low。不管怎样,还是得阐述一下自己真实的思路:首先定义单词结构体,包含单词名、词频、单词长,单词统计功能按题意应分为以下两块,1.识别其为新单词并添加其为新单词,2.识别其为已有单词并使该单词词频自增。识别单词比较容易,在两个分隔符中满足前四个字符为英文字母即可,识别其是否为已有单词则需要遍历已有单词结构体。
5.单词按序输出功能:依然需要遍历结构体,词频高的单词优先输出,词频相同的话按位比较ascii码值,ascii码值小的优先输出,ascii码按位相同的话长度小的优先输出。
6.文本输出功能:利用fprint函数即可实现。
3.设计实现过程
- Words:单词结构体,一个单词结构体中包含单词自身、单词词频、单词长度
- charcounter( ):用于统计文本中的字符数
- linecounter( ):用于统计文本中的行数
- wordcounter( ):用于统计文本中的有效单词数
- printer( ):用于输出题目要求的数据
这些函数都是用来被main.cpp调用,用于实现对文本的各种统计操作,因此它们是调用与被调用关系
我展示一下最主要的wordcounter函数的流程图
单元测试部分
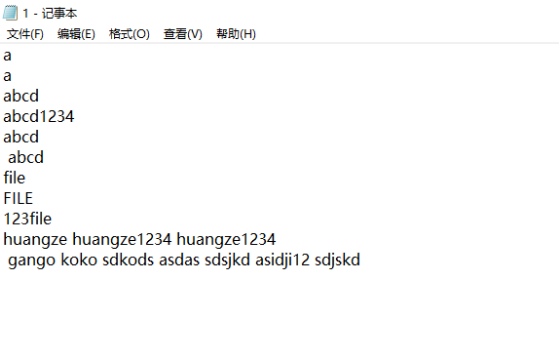
我选择了一些比较具有代表性的单词并将它们加在同一个文本中进行测试,包括:1.数字字母混合 2.单个字符 3.单个重复字符 4.'123FILE'类型的单词(会输出file)5.重复出现相同单词 6.重复出现错误单词 7.大写单词 8.相同部分ascii码相同但是长短不同的对比单词 9.单字符一行 10.多字符一行 等
测试结果如下:
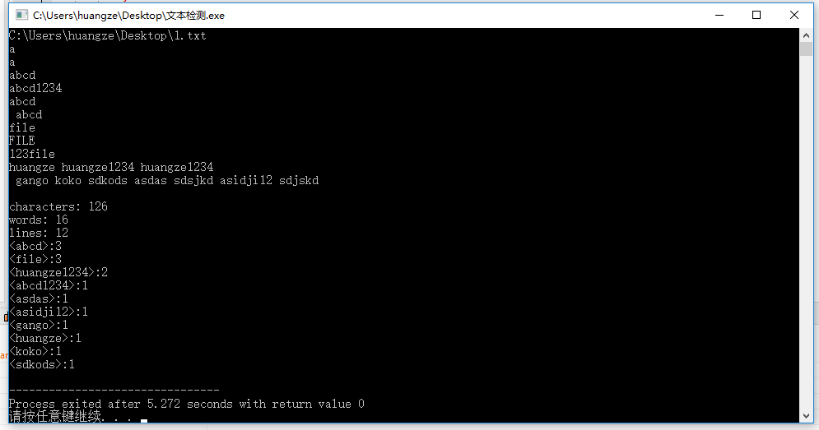
4.性能分析
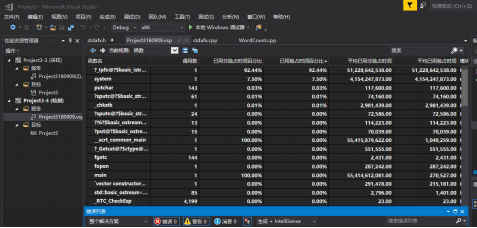
由VS 2017的性能分析工具自动生成了以下性能分析图

这是消耗最大的函数
5.代码说明
这里只展示了关键部分的代码段
1.文本输入代码
cout << "请输入文本的路径" << endl;
cin >> filename;
if ((fp = fopen(filename, "r")) == NULL)
{
cout << "路径输入错误" << endl;
exit(0);
}
ch = fgetc(fp);//按字符读取并分析
2.是否为合理单词的判断与新单词的添加(这是未经封装的版本,但是思路是一样的)
while (ch != EOF)
{
if (ch >= ' '&&ch <= '~')
{
if(ch>=65&&ch<=90)
{
ch=ch+32;//大写字母变为小写字母
}
if(ch>=87&&ch<=122&&flag<=3)
{
flag++;
testword[flag]=ch;//该字符可能会组成一个合理单词,录入
}
if((ch<87||ch>122)&&flag<=3)
{
flag=0;//疑似合理单词的前四位出现非字母,删除
}
if(flag>=4&&ch!=' ')
{
flag++;
testword[flag]=ch;//已确定为单词,因此之后任意字符均接纳
}
if(flag>=4&&ch==' ')
{
words++;//出现分隔符,该单词结束,单词数加一
for(i=1;i<=kind;i++)
{
for(j=1;j<=flag;j++)
{
if(testword[j]!=type[i].wordtype[j])//遍历单词结构体
{
i++;
j=1;
break;
}
if(j==flag)
{
type[i].frequency++;//为已有单词,该单词词频加一
i=kind;
temp=1;
break;
}
}
}
if(temp==0)
{
kind++;//单词种类数自增
for(k=1;k<=flag;k++)
{
type[kind].wordtype[k]=testword[k];//非已有单词,添加为新单词
}
type[kind].lenth=flag;
type[kind].frequency++;
}
flag=0;
temp=0;//各计数器清零
}
}
3.统计文件中各单词的出现次数
int tra = 0;
int max = 0;
int len = 100000;
int p = 0;
for (i = 1; i <= min(10, kind); i++)
{
for (j = 1; j <= kind; j++)
{
if (type[j].frequency == max)
{
for (k = 1; k <= min(type[j].lenth, len); k++)
{
if (type[j].wordtype[k] < type[tra].wordtype[k])
{
tra = j;
len = type[j].lenth;//ascii码小的先输出
break;
}
if (type[j].wordtype[k] > type[tra].wordtype[k])
{
break;
}
if (k == min(type[j].lenth, len))
{
if (type[j].lenth < len)
{
tra = j;
len = type[j].lenth;//ascii码相同则短的先输出
}
}
}
}
if (type[j].frequency > max)
{
max = type[j].frequency;
tra = j;//词频高的先输出
}
}//一步步遍历得到优先度最大的单词
cout << "<";
for (k = 1; k <= type[tra].lenth; k++)
{
if (k == 4)
{
continue;//因为在之前的调试中发现所有单词的第四个字符会重复一遍输出,因此干脆不输出第四个字符算是变相解决问题了
}
cout << type[tra].wordtype[k];
}
cout << ">:";
cout << type[tra].frequency << endl;
type[tra].frequency = 0;
len = 100000;
max =0 ;//滤去该优先度最大的单词
}
6.代码覆盖率
利用插件——OpenCppCoverage,我得到了我的代码的代码覆盖率,代码覆盖率都很理想但是不知为何没有显示出具体的百分比

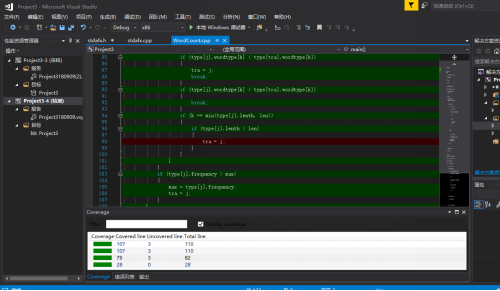
图1覆盖率低的原因是这段代码是检测地址输入有无错误的,然而给出的测试基本不会出现这个问题
图2覆盖率低是因为该情况在给出的样本中出现率极低
7.心得体会
其实这算是真正意义上的第一次作业,感到十分头疼,花了不少时间在代码上。但其实,让我更加头疼的是博客,我在博客上花的心思感觉甚至超过了代码。经过了这次作业,我认识到了自己距离一个真正的码农差的还很远。很多技术有待提高,比如这次作业我就用了比较笨拙的办法,甚至还可能有没有找到的bug,不管怎么说,下次更努力,继续加油!