卷积神经网络:Convolutional Neural Networks
神经网络基础上的改进版本。
用途
主要用于 计算机视觉领域,如 检测、追踪、分类、检索、分割;医学任务:细胞检测,人体透视图,对动态图进行识别等;无人驾驶。
检索:输入一张图像,判断是什么,返回有相似度的其他图片。
如上传 梅花,返回其他梅花图片;淘宝找同款。

超分辨率重构:让神经网络学习,怎么样让图片更清晰。

传统神经网络 特征提取的问题:
中间矩阵比较大。
和传统神经网络的区别

直观来看,更立体。
传统神经网络 NN 输入 784个特征;
CNN 输入 28 * 28 * 1 ,三维的长方体矩阵。不会把数据拉成向量,而是直接对图像数据进行特征提取。
CNN 还有 深度 的概念。
整体架构
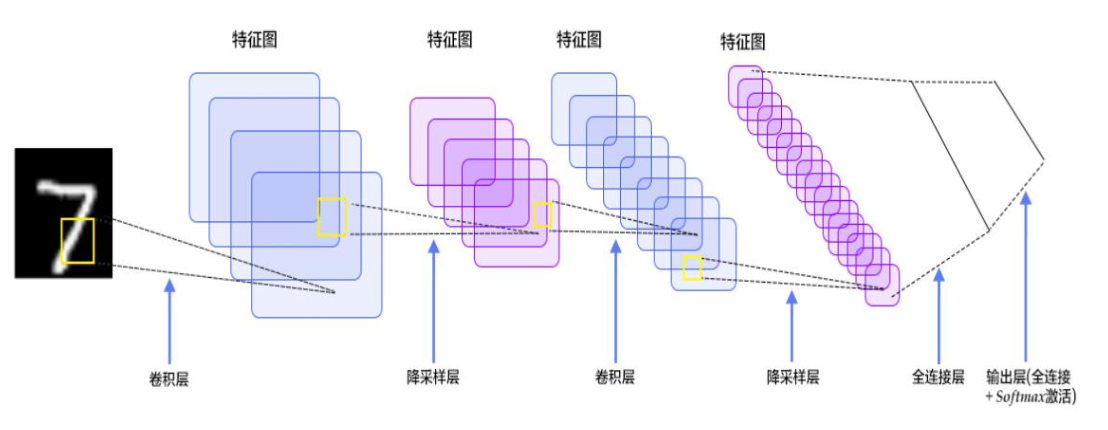
- 数据输入层 Input layer
- 卷积计算层 CONV layer:提取特征
- ReLU激励层 ReLU layer
- 池化层 Pooling layer:压缩特征
- 全连接层 FC layer
卷积

对于 RGB 彩色图片,一般会单独对每个通道单独做卷积,然后再加到一起
卷积层的输出宽度、深度
- 输出深度由过滤器个数决定
- 输出宽度
以输入的体积为例 H1 * W1 * D1
四个超参数
- K: Filter 数量
- F:Filter 大小
- S:步长
- P:零填充的大小
输出的体积是 $ H2 * W2 * D2 ( )H2 = (H1 - F + 2P)/S + 1 ( )W2 = (H1 - F + 2P)/S + 1 ( )D2 = K$
堆叠的卷积层

卷积层涉及参数
- 步长
- 核尺寸
- 边缘填充
- 卷积核个数
步长
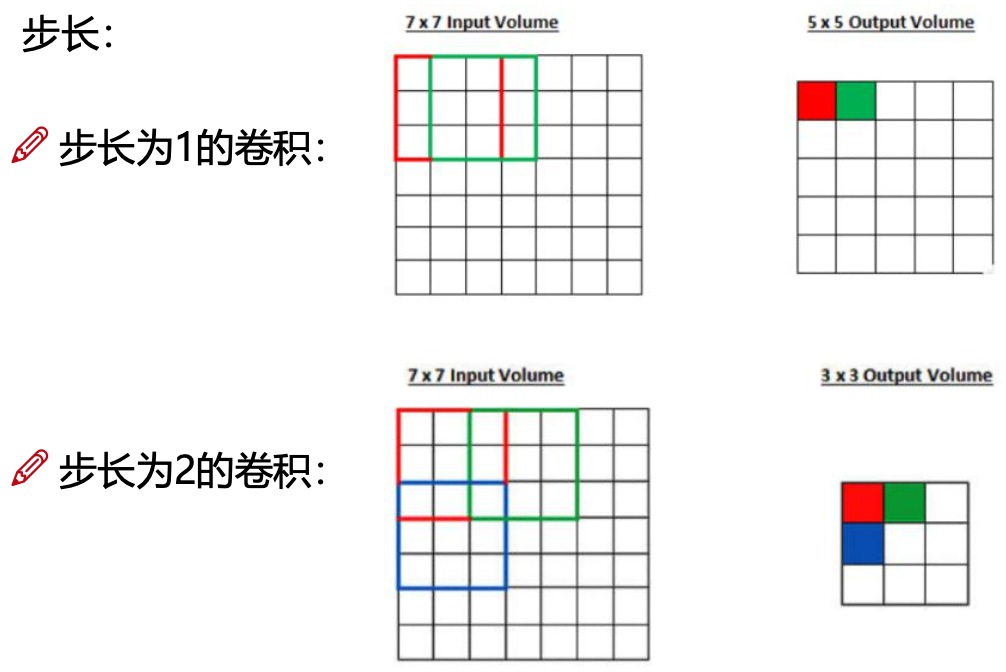
图片常用步长为 1,当然这样比较慢。
卷积核尺寸
最小为 3*3
边缘填充 pad
一般用 0 进行填充,只是扩充;如果填充1,会有影响。
所以也叫 zero-padding。
一般填 1 圈。
文本数据的填充:一般也会填充0。
卷积核个数
想要得到多少个特征图,就使用多少个卷积核个数。10、20、30、40 都行。
一般每个卷积核里面的数值都是不一样的。
卷积结果计算
长度:$ H_2 = frac{H_1 + 2P - F_h}{S} + 1$
宽度:$ W_2 = frac{W_1 + 2P - F_w}{S} + 1$
- $W_1,H_1 $ 表示输入的宽度、长度;
- $W_2,H_2 $ 表示输出特征图的宽度、长度;
- F:卷积核长和宽的大小;
- S:滑动窗口的步长;
- P:边界填充(加几圈0)
如果输入数据是 32323 的图像,用10个 553的filter来进行卷积操作,指定步长为1,边界填充为2,最终输入的规模为?
(32-5+22)/1 + 1 = 32,所以输出规模为3232*10,经过卷积操作后也可以保持特征图长度、宽度不变。
卷积参数的共享
对于不同区域,卷积核内的值一般也应该不同,效果更好。但如果每个都做卷积,数据太多。所以使用卷积共享理念。
参数比全连接的方式少得多。
池化层
卷积的时候会尽可能多的提取特征,但不是所有特征都是有效的,这时就会用池化层来做有选择性的压缩(下采样)。
两种下采样方式:
- 最大值下采样 MAX POOLING
- 平均值下采样 AVE POOLING;没有 Max 效果好,现在用的比较少。
池化层没有涉及到任何矩阵的计算,只是筛选、压缩、过滤。


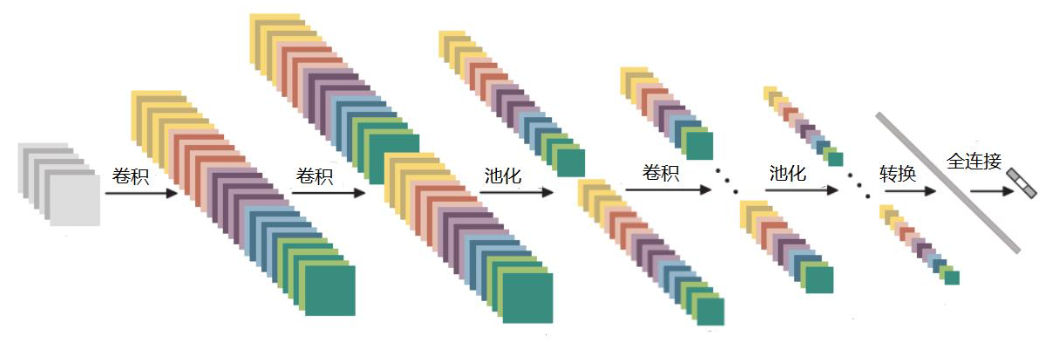
- 卷积层都和 RELU 搭配在一起
- 两次卷积一次池化
- 卷积和池化,只能做特征提取;要想得到结果,还是需要全连接层(FC);需要将原来的三维,转化为特征
向量。
如果将 323210 的图像转化为 5分类任务,全连接层的 W 尺寸为 (10240,5) - 全连接层 将 两层之间所有神经元都有权重连接;
- 带参数计算(权重、偏置,去反向传播更新数据)的才能称为一层;CONV 和 FC 带,RELU 和 POOL 不带参数计算。
所以上图为 7 层神经网络。
经典网络
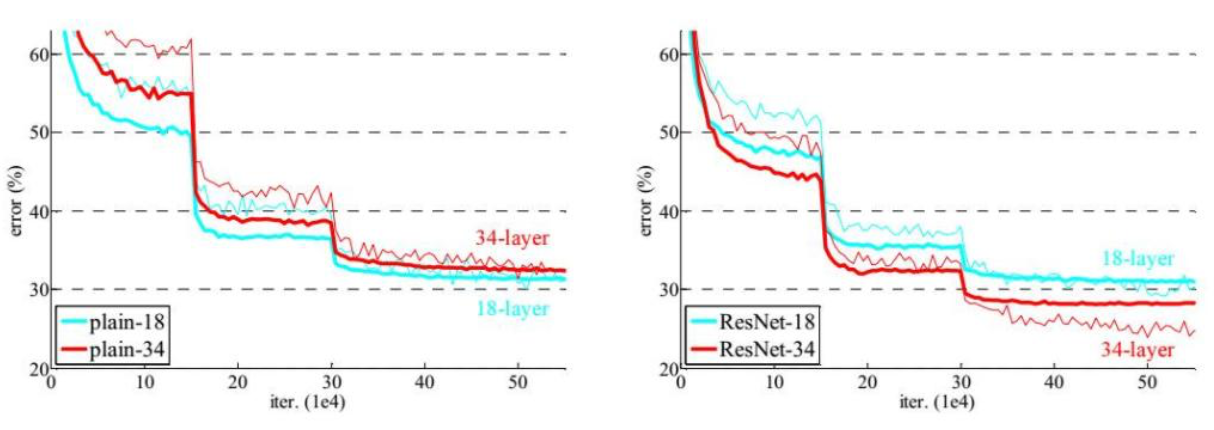
Alexnet 是12年夺冠的网络,已过时。
问题:卷积核 11*11,太大;pad 为 0;有8层。LRN 层没用。
Vgg 为14年时改进了的网络。
所有卷积大小均为 3*3;有16--19层网络;
特点:上一次卷积pool 损失的信息,会在下一次卷积的时候,用特征图的个数弥补长宽损失;
缺点:更深、卷积更细致;耗时比Alexnet 长;以天为单位。
深度学习并不是层数越多越好。
15年中国作者提出 Resnet(残差网络),同等映射,将效果不好的层 权重参数设置为0 来不使用;
比如 A--B--C,B的效果不好,直接让 A 连到C;
实现 既把层数堆叠起来,又不让差的层影响作用。
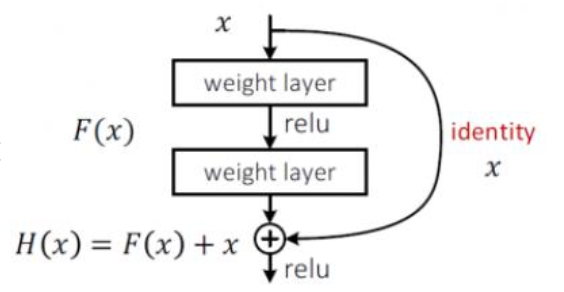
这样保底,至少学习完不会比原来差;所以 Resnet 目前是首选。
Resnet 可以看做特征提取,不建议当成分类网络。因为分类还是回归,取决于损失函数和最后的层怎么连的。
Resnet 是个很通用的网络。
感受野
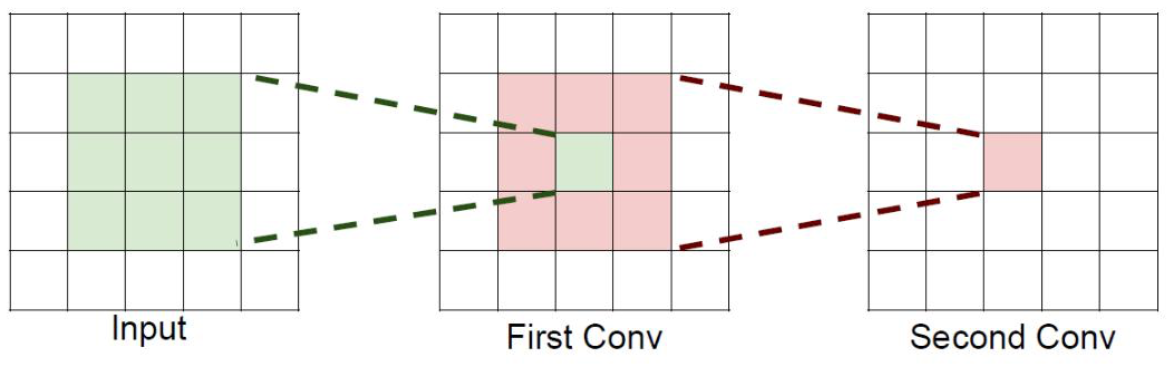
后一层可以看见前一层多少(前一层多少数据参与计算得到的)。
如 11 可以看到前一层的 33,33 可以看到前一层的 55;
问题:能不能用大核代替小核?
如果堆叠3个 (3*3)的卷积层, 并且保持滑动窗口步长为1,其感受野就是(7*7)的了,这跟一个使用(7*7)卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
假设输入大小都是 (H*W*C),并且都使用C个卷积核(得到C个特征图),可以来计算一下其各自所需参数:
(1个 7*7 卷积核所需参数 = C * (7 * 7 * C)= 49 C^2)
(3个 3*3 卷积核所需参数 = 3 * C * (3 * 3 * C)= 27 C^2)
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换(RELU)也随着增多,还不会增大权重参数个数,这就是VGG网络的基本出发点,用小的卷积核来完成体特征提取操作。
自动编码器