什么是机器学习?
传统计算机任务:编写规则,让计算机去执行
机器学习:让计算机去学习,自定义规则
传统任务遇到的问题:
1、对于很多问题,规则难以制定;
2、规则在不断变化。
人工智能、机器学习、深度学习
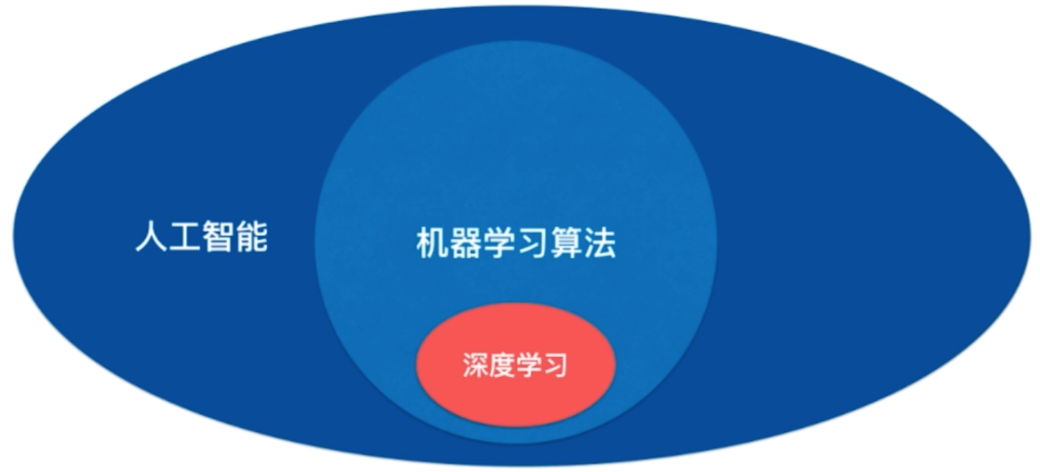
机器学习是AI 的一种方法;
AI 还有其他解决方法,如:
- 以搜索为基础的算法(传统的搜索策略,如深蓝的人机大战;梯度下降,也是搜索算法)。
- 以符号主义为代表的 通过推导逻辑 来形成的算法
...
问题
- 如何评价算法的好坏?
- 如何解决过拟合和欠拟合?
- 如何调节算法的参数?
- 如何验证算法的正确性?
机器学习 处理步骤
- 数据准备阶段
- 原始数据
- 特征提取
- label feature
- 训练数据
- 验证数据
- 测试数据
- 训练阶段
- 训练
- 算法:生成适合场景的训练模型
- 评估:将验证数据拿到模型中评估
- 评估方式:分类数据和连续型数据;如果模型不好,则再次训练;如果模型好,则放到测试阶段。
- 测试阶段
- 预测
数据预处理
-
数值、字符串
-
缺失值
-
异常值
-
极端比例
- 下采样
- 过采样
- SMOTE
-
相似特征 : 去除冗余
-
平滑处理
- 拉普拉斯平滑
-
特征转化成数字,就会有等级之分;应该转化为 one-hot
-
降维
- PCA 主成分分析法
- KernalPCA 核机制主成分分析
- LDA 线性判别分析
- NMF 非负矩阵分解法;处理矩阵。
- TSVD 截断奇异值分解法;处理稀疏矩阵。
-
模型正则化
-
贝叶斯算法
机器学习算法
-
kNN
- 评估:分类准确度 accuracy
-
线性回归
- 种类:普通线性回归、多元线性回归
- 减少方差:正则化惩罚项(岭回归、锁套回归)
- 评估:均方根误差 RMSE、平方绝对误差 MAE
-
逻辑回归(解决分类问题)
-
决策树
- 标准:熵,信息增益
- ID3, C4.5
-
随机森林
-
集成学习:Bagging、Boosting、Stacking
全概率公式,贝叶斯公式 - 拉普拉斯平滑
- 卡方检验
- 事件概率、联合概率、条件概率
-
SVM 支持向量机
-
聚类
-
神经网络
模型学习
模型调整
模型评定标准
如何评价算法好坏?
- 回归 : accuracy, F
- 距离
- 二分类问题: AUC(ROC)
- rmse
相关性
两个连续线性相关
- 线性相关关系
- 非线性相关关系
- 周期性的 非线性相关关系
- 无明显的相关关系
- 正向线性关系
- 负向线性关系
- 无关系
相关性分析方法
- 皮尔逊
- 斯皮尔曼(有序变量)
其他专业领域
- 视觉
- 自然语言处理
- 时间序列分析
- 推荐系统
- 协同过滤
- 隐语义模型
概念
数据集、样本、特征
- 通常将手中的数据称为
数据集(data set); - 数据集可以写作表格的形式;通常一行数据可以称为一个
样本(sample); - 最后一列称为
标记(label),写作 (y); - 除最后一列,每一列表达样本的一个
特征(feature);
表示:
- 第 i 个样本 写作 (X^{(i)})
- 第 i 个样本的第j个特征值 写作 (X_j^{(i)})
- 第 i 个样本的标记 写作 (y^{(i)})
一般用大写字母表示矩阵,小写字母表示向量
特征向量 (X^{(i)}) 一般记为列向量,如:
特征矩阵是列向量转置的集合:
分类
特征空间(feature space)
每一个样本的特征组合,都是一个特征向量;
如果使用两个特征,可以表示为二维空间(平面)中,使用一个点表示这个样本。如果是n个特征,就是n维空间中的点。
分类任务的本质,就是切分特征空间;

机器学习中,有些特征没有语义,或非常抽象、朴素。
给机器的数据的怎样的,将很大程度决定结果的准确性和可靠性。这个方面有专门的领域研究:特征工程。
分类任务的类型
-
二分类(最常用)
如:猫狗分类;是、否垃圾邮件;投资是否有风险等。 -
多分类
如:手写数字识别、图像识别、风险评级等;
一些算法只支持完成二分类任务;但多分类任务可以转换成二分类任务。而且转换的方式有很多种。 -
多标签分类(前沿)
把一张图片分到多个类别中;

回归
分类问题中的标签是一个类别;回归中的标签是一个连续数字的值;
有一些算法只能解决回归问题;
有一些算法只能解决分类问题;
有一些算法既能解决回归问题,又能解决分类问题;
一些情况下,回归任务可以简化成分类任务;
分类 和 回归是从机器学习解决的问题来分类,而非机器学习算法本身来分类的。
机器学习算法类型(监督 & 非监督)
-
监督学习(最常用):有特征值,有目标值
主要处理:分类,回归。 -
非监督学习:有特征值,没有目标值;常用来辅助监督学习;
应用如:聚类、数据降维(特征提取,特征压缩)、异常检测等。 -
半监督学习:一部分有标记,另一部分没有
这种在生活中更常见;如各种原因产生的标记缺失。
通常先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。 -
增强学习
根据周围的环境来采取行动,行动之后收到反馈(奖赏或惩罚)来改进行为模式。
如:alphaGo 围棋对战;无人驾驶,强人工智能机器人。
监督学习和半监督学习是增强学习的基础。
机器学习其他分类
在线学习 & 批量学习
批量学习 Batch Learning,也叫做 离线学习(Offline Learning)
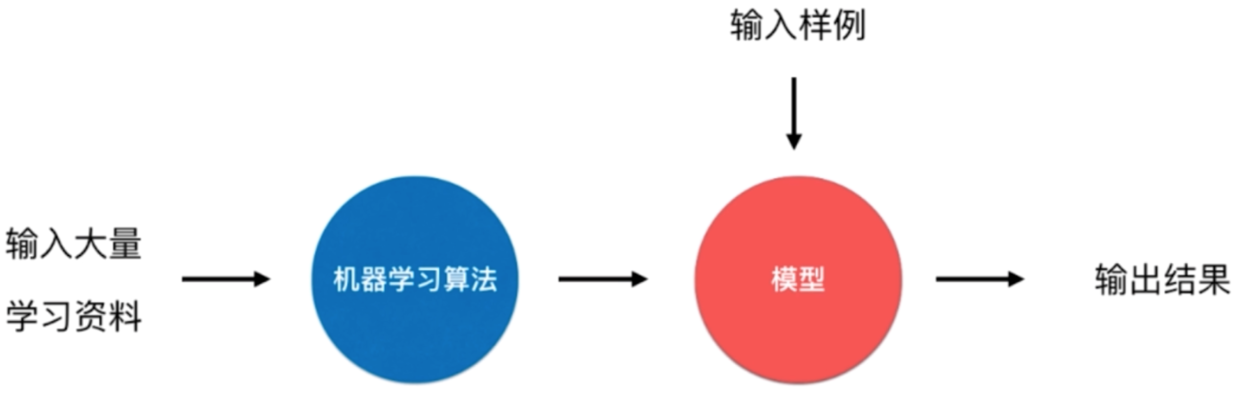
优点:简单
问题:如何适应环境变化?
解决方案:定时重新批量学习;
缺点:每次重新学习,运算量太大;在某些变化快的情况下(如 股市),不可能学习,
在线学习 Online Learning
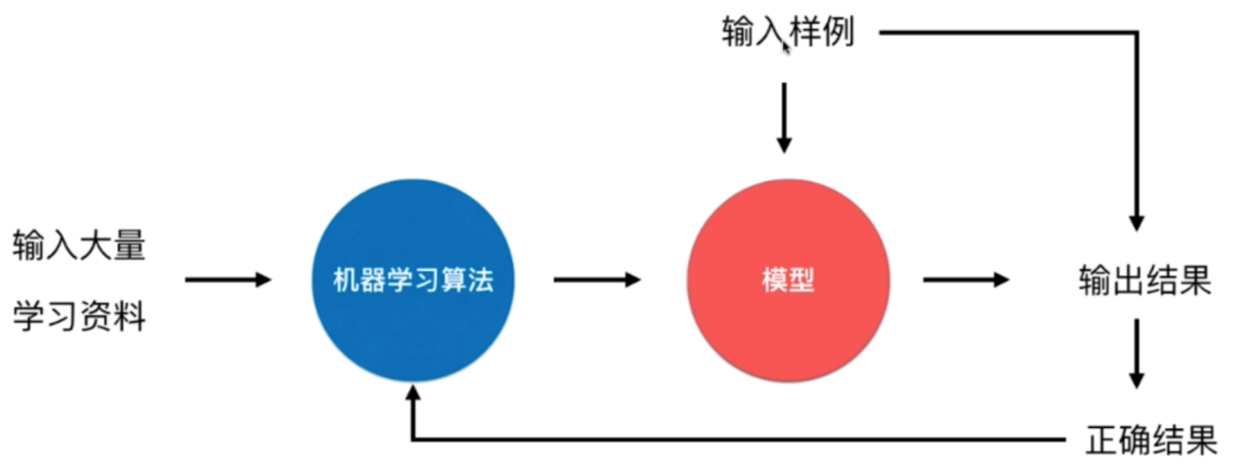
新的样例还会不断改善算法;
优点:即时反应新的环境变化;
问题:新的数据带来不好的变化;
解决方案:加强对数据的监控。
其它:也适用于数据量巨大,无法完成批量学习的环境(将数据分解成小批来喂)
参数学习 & 非参数学习
参数学习 Parametric Learning
如使用函数 (f(x) = a*x + b) 来描述一组数据,找到适合的参数 a 和 b 了,就不再需要原来的数据集,就可以预测数据。
非参数学习 Nonparametric Learning
非参数不等于没有参数,只是不对模型进行过多假设;
过拟合 & 欠拟合
过拟合:十分适配当前的场景;换了场景就不适合了。没有广泛性。
当前场景准确率越高,不代表就越好。所以需要测试阶段来验证和评估,得到 bestmodel,来拿到真实场景进行预测。
解决方法:区分 训练集 和 测试集
训练集、测试集、验证集
正则化惩罚项
损失函数
找一个误差公式,计算模型与数据的差;
对于现象回归模型而言,将点到线
特征压缩:尽量少的损失信息的情况下,将高维的特征向量,压缩成低维的特征向量。这样可以大幅提高机器学习运行效率,不影响准确率。
降维的其他意义:方便可视化。
判断机器学习算法的性能
训练数据 & 测试数据
如果拿所有原始数据来训练,存在的问题:
- 模型很差无法调整;
- 真实环境难以拿到真实 label;
所以将数据区分为 训练数据 和 测试数据(train test split);
将训练数据来训练模型;然后用测试数据测试模型;
使用这种方式也存在问题;
使得误差值最小
正规函数
机器如何学习
- 数据
- 怎么样学:目标函数;什么样的参数最符合目标。
- loss 损失函数
目标函数,希望误差项越小越好,接近于0。
机器学习的哲学问题
数据 还是 算法 重要?
AlphaGo Zero 以算法为主;
奥卡姆剃刀原则:简单就是好的;机器学习领域,什么叫简单?
没有免费的午餐定理:任意两个算法,他们的期望性能是相同的。期望即平均值,但每个算法在特定领域特定问题 有优劣。没有一种算法绝对好于另一种。在面对一个具体的问题的时候,有必要尝试使用多种算法进行对比试验。
机器学习相关概念
数据挖掘(Data Mining)
数据挖掘=机器学习+数据库。数据挖掘是在大型数据存储库中,自动地发现有用信息的过程。
自然语言处理 (Natural Language Process)
自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
模式识别(Pattern Recognition)
模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。
统计学习(Statistical Learning)
统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉(Computer Vision)
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别(Speech Recognition)
语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
计算机图形学、数字图像处理、计算机视觉
- 计算机视觉( Computer Vision,简称 CV),是让计算机“看懂”人类看到的世界,输入是图像,输出是图像中的关键信息;
图片 -> dog or cat?
图片 -> [xyz xyz xyz ... xyz] - 计算机图形学(Computer Graphics,简称 CG),是让计算机“描述”人类看到的世界,输入是三维模型和场景描述,输出是渲染图像;
[xyz xyz xyz ... xyz] -> 图片 - 数字图像处理(Digital Image Processing,简称 DIP),输入的是图像,输出的也是图像。Photoshop 中对一副图像应用滤镜就是典型的一种图像处理。常见操作有模糊、灰度化、增强对比度等。
图片 -> ps后的图片
再说联系
- CG 中也会用到 DIP,现今的三维游戏为了增加表现力都会叠加全屏的后期特效,原理就是 DIP,只是将计算量放在了显卡端。通常的做法是绘制一个全屏的矩形,在 Pixel Shader 中进行图像处理。
- CV 大量依赖 DIP 来打杂活,比如对需要识别的照片进行预处理,增强对比度、去除噪点。
- 最后还要提到今年的热点——增强现实(AR),它既需要 CG,又需要 CV,当然也不会漏掉 DIP。它用 DIP 进行预处理,用 CV 进行跟踪物体的识别与姿态获取,用 CG 进行虚拟三维物体的叠加。
面试——把自己嫁出去
面试官面的是什么
我个人的经验一次正规的面试包括几个部分:
- 基础能力:数据结构与算法通过做一些智商题、ACM,一般笔试题会从leetcode找。基础能力除了基本的数据结构与算法外,经常还会考察求职者对一门编程语言的掌握程度。
- 工作经历:在哪些公司工作过,做过哪些项目,能不能把做过的东西很清晰的很系统的讲出来。(注:哪怕不是自己做过的东西,求职者能很好的讲出来,面试官也会给加分)
- 沟通能力:性格是否比较好,是否能愉快的沟通,是不是能融入团队。其实有时就是看颜值,通俗说能否看对眼。哪怕能力不怎么好,但是面试官司觉得人不错,工作能干得了,值得培养也没问题。
书籍
-
《机器学习》作者: 周志华
《https://book.douban.com/subject/26708119/》 -
《机器学习算法原理与编程实践》 作者: 郑捷
https://book.douban.com/subject/26667987/
教程资源等
-
吴恩达(Andrew Ng):机器学习
https://www.coursera.org/learn/machine-learning -
apachecn:AI Learning
https://apachecn.gitee.io/ailearning/#/docs/ml/1 -
刘宇波:机器学习
https://github.com/liuyubobobo/Play-with-Machine-Learning-Algorithms -
paperwithcode
https://www.paperswithcode.com -
arxiv
https://arxiv.org -
sci-hub