【ui自动化】
UI自动化测试框架介绍
T&T
config
configs.py 配置信息
data-driven
测试用的excel 数据驱动测试用例及其他数据
model
通用操作类
page_object
基类及测试页面类,控件识别在测试页面中,所有页面继承page类。
report
报表文件 html
TestCase
页面UI测试用例,测试用例与页面元素进行分离,便于维护;
所有测试用例继承 myunit.MyTest 类
run_all_test.py
所有测试用例一起执行总文件
1、怎么获取新的浏览器窗口内容,用什么方法
1、获取当前窗口句柄
driver.current_window_handle
2、获取所有句柄
driver.window_handles
3、切换窗口
driver.switch_to.window(handle)
2、页面元素等待有哪几种方法;显示等待和隐式等待区别在于,方法名叫什么
显示等待:使webdriver等待某个条件成立时继续执行,否则在达到最大时长时抛弃超时异常
webdriverwait类是由webdriver提供的等待方法。
element=webdriverwait(driver,5,0.5).until(EC.presence_of_element_located(By.id,'KW'))
webdriverwait(driver,timeout,poll_frequency=0.5,ignored_exceptions)
driver:浏览器驱动
timeout:最长超时时间,默认以秒为单位
poll_frequency:检测的间隔(步长)时间,默认为0.5
ignored _exceptions:超时后的异常信息,默认情况下抛NosuchElementException异常。
webdeiverwait一般由until或until_not() 方法配合使用。
until(method,message='')
调用该方法提供的驱动程序作为一个参数,直到返回True
until_not(method,message="")
调用该方法提供的驱动程序作为一个参数,直到返回False
隐式等待:通过一定的时长等待页面上某个元素加载完成。如果超出了设置的时长元素还没有被加载,则抛出Nosuchexception异常。
webdriver提供implicitly_wait()方法来实现隐式等待,默认设置为0
driver.implicitly_wait(10)
默认以秒为单位,10秒并不是固定等待时长,它并部影响脚本的运行速度,其次它不是针对页面上某一个元素进行等待,
当脚本执行到某个元素定位时,如果元素可以定位,则继续执行,如果元素定位不到,则它将以轮询的方式不断的去判断元素是否定位到。
假设在第6秒定位到元素,则继续执行,若直到10秒都还没有定位到元素,则抛出异常。
sleep休眠方法
固定时间休眠。sleep()方法是python的time模块提供的
3、有撒好的方法,来维护ui自动化脚本。
4、获取元素的方法element和elements的区别在于。
find_element 只会查找页面中符合条件的第一个节点,并返回
find_element
如果查找的目标在网页中只有一个,那么完全可以用find_element(),但如果有多个满足要求的节点,用find_element()就只能得到第一个节点了,所以查找多个节点时,应该使用find_elements()更好.
find_element()会返回一个WebElement节点对象,但是没找到会报错,而find_elements()不会,之后返回一个空列表
查找多个元素的时候:只能用find_elements(),返回一个列表,列表里的元素全是WebElement节点对象
【接口自动化】
1、jmeter 后置处理器有哪些组建
1、BeanShell PostProcessor
2、JDBC PostProcessor
3、jSON Extractor
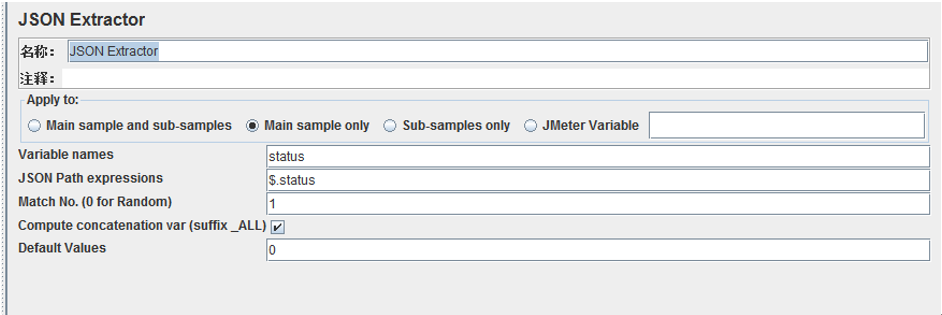
属性 描述 备注
Variable Names 变量名
JSON Path Expressions Json提取表达式
Match No. (0 for Random) 当提取有多个结果值时,选择需要的值保存到变量中,默认值为0
0:随机一个
-1:全部值,使用_N 方式保存(N从1开始),比如status_1,status_2…
X: 自然数,比如1,返回第X个值(如果X大于返回值的数量,结果会不能获取,最终返回设置的默认值)
Compute concatenation var 如果有匹配到多个值,选择此项,会将全部值保存到_ALL,并使用逗号分割每个值 注意Match No. (0 for Random)需要为-1才有效,不然只能匹配到一个值了
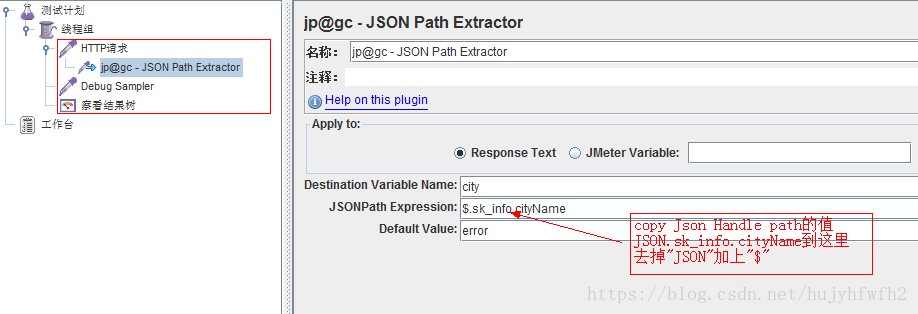
4、JSON Path Extractor
5、正则表达式提取器
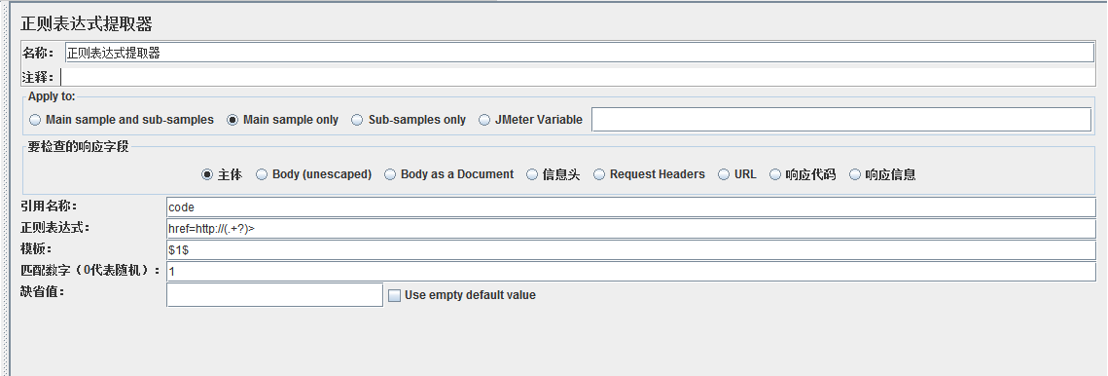 属性 描述 备注Apply to Sampler可能会产生子Sampler,这里需要选择从哪个Sampler中进行提取
属性 描述 备注Apply to Sampler可能会产生子Sampler,这里需要选择从哪个Sampler中进行提取
要检查的响应字段 指要从请求的哪部分内容中进行提取
主体:请求的响应数据
Body (unescaped):请求的响应数据,html代码不会被转义
Body as a Document:
信息头:指响应头
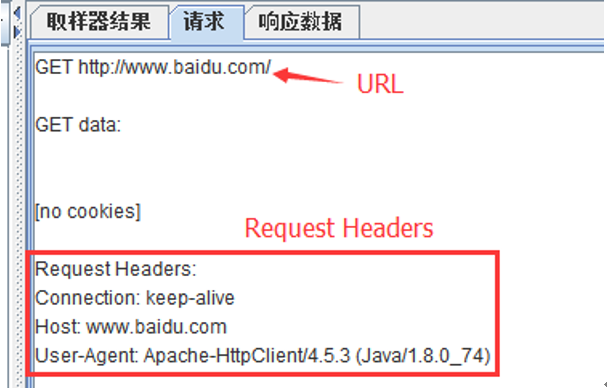
Request Headers:请求头
URL: 请求地址
响应代码:e.g 200 响应信息:e.g OK 感觉这些中文翻译有点绕。。可以从下面的注解截图中了解下
引用名称 用来保存提取结果的。同时还会生成一组变量,[引用名称]_g#:
[引用名称]_g:表达式提取的次数(指表达式中”()”的数量)
[引用名称]_g0:表达式匹配到的完整字符串
[引用名称]_g1:表达式中第1个“()”提取到的值
[引用名称]_g2:表达式中第2个“()”提取到的值
。。。 如果表达式匹配到多个字符串,最终引用名称生成的变量会变成 [引用名称]_N_g#, N表示匹配的字符串顺序
正则表达式 正则表达式,最少要包括一个“()”, 括号里面的表示要提取的内容 比如:aaa(.+?)ccc, 可以提取到aaabbbcc中的 “bbb”.
(.+?)是一个很常用的表达式,
.表示任意一个字符
+表示重复一次或多次
?表示匹配0次或一次
更多的的介绍可以看下:正则表达式
模板 说明要获取哪个提取式的内容,比如
’$1$’: 获取第1组的内容(指第一个“()”中提取到的值)
’$2$’: 获取第2组的内容
。。。
$0$ :表示获取整个表达式匹配的内容(就是[引用名称]_g0 的值)
匹数数字 表达式可能会匹配多个字符串,匹数数字说明要获取第几个匹配值
0:表示随机一个
N:表示第N个
-1:表示全部(负数都是一样的) 如果填写了负数,最终引用名称必然会加上序号,比如[引用名称]_1, 使用的时候要注意
缺省值 表达式匹配不到字符串时,保存到引用名称中的值 默认值,可以为空的

2、参数话有哪些方法
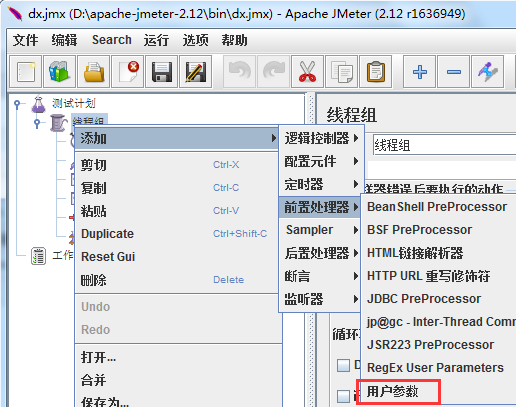
2、用户定义变量
设置方式:添加→配置元件→用户定义的变量,设置如下:

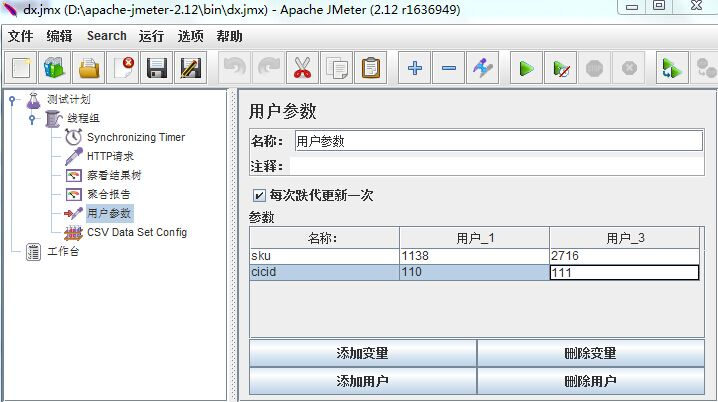
3、设置方式:添加→配置元件→csv data set config,设置如下:

1.为文件所在的位置,可以建txt文档,然后,直接改后缀名。里面的内容,第一行直接为数据。这里支持csv,txt,dat三种格式。
2.utf-8,编码格式,直接照写就行
3.sku,为参数的名字,用${sku}替换要参数化的地方。如果有多个变量,则用逗号隔开,如user,pwd
4、随机函数RandomString
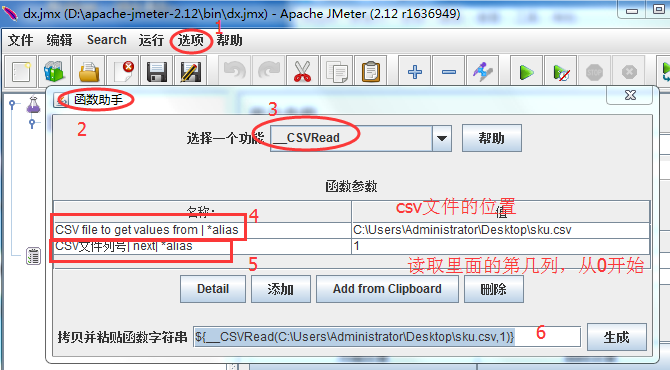
位置:按照1-2-3的步骤
操作:4中填写文件的位置,5中填写要读取的列的位置,第一列为0。点击【生成】按钮,拷贝字符串,去替换要参数化的值。
注意:Jmeter读取的文件中第一行没有标题,直接就是值了。
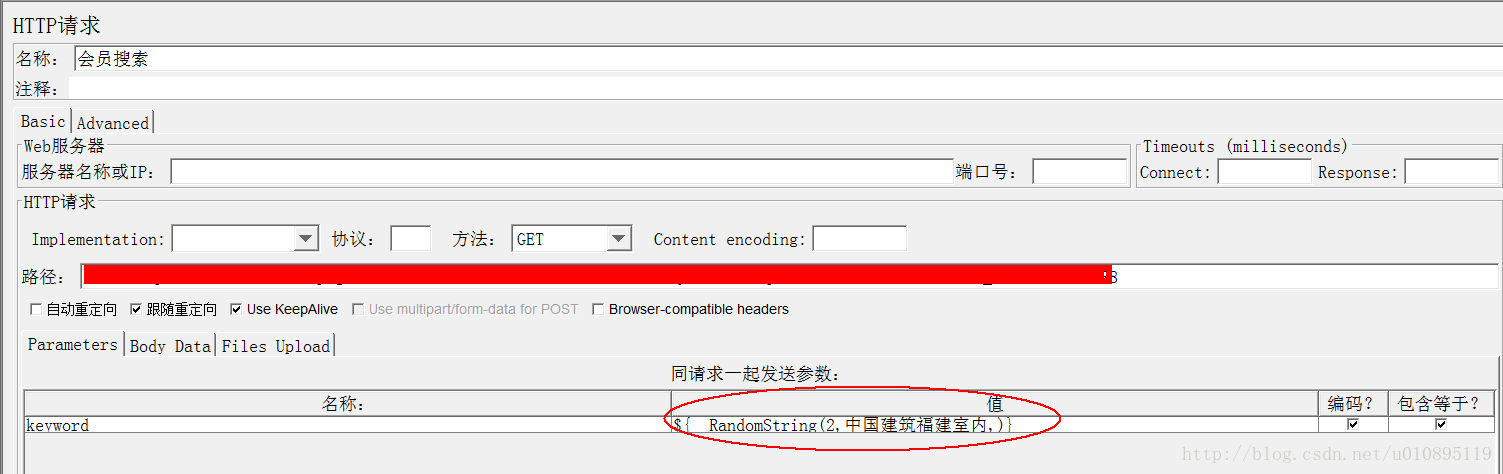
5、随机函数RandomString
设置方式:选项→函数助手对话框→选择函数为:_RandomString,设置如下:

说明:第一项为长度,设为2,则会取2个汉字;第二项为可选,建议填上,生成的随机字符串会从这一项中随机选取并组合;第三项可选,可填可不填;最后点击生成,把生成的一堆东西复制粘贴在参数的位置,如下:
3、jmeter正则表达式的使用;模板1,和模板2分别什么意思;怎么获取token,* ?的区别;
’$1$’: 获取第1组的内容(指第一个“()”中提取到的值)
’$2$’: 获取第2组的内容
。。。
$0$ :表示获取整个表达式匹配的内容(就是[引用名称]_g0 的值)
.表示任意一个字符
+表示重复一次或多次
?表示匹配0次或一次
4、jmeter怎么做性能测试,需要关注哪些测试点
5、三次握手四次挥手
6、https协议
7、url地址组成部分
【python自动化脚本】
1、使用的什么框架
2、测试用例是怎么管理的
3、setup&setdown 与setupclass&setdownclass区别
【对excel表的操作】