大家好,我是咔咔 不期速成,日拱一卒
本期来聊聊MySQL的加锁规则,知道这些规则后可以判断SQL语句的加锁范围,同时也可以写出更好的SQL语句,防止幻读问题的产生,在能力范围内最大程度的提升MySQL并发处理事务能力。
现在你应该知道了MVCC解决了快照读下的幻读问题,但当前读的幻读问题还是基于锁解决的,也就是next-key lock。

最新文章
为什么MySQL字符串不加引号索引失效?《死磕MySQL系列 十一》
打开order by的大门,一探究竟《死磕MySQL系列 十二》
闯祸了,生成环境执行了DDL操作《死磕MySQL系列 十四》
一、了解next-key lock
在文章幻读:听说有人认为我是被MVCC干掉的这期文章中,详细说明了幻读在当前读、快照读下的解决方式。
快照读简单来说就是简单的select操作,没有加任何锁,在Innodb存储引擎下执行简单的select操作时,会记录下当前的快照读数据,之后的select会沿用第一次快照读的数据,即使有其它事务提交也不会影响当前的select结果,因此通过快照读查询的数据虽然事一致的,但有可能不是最新的数据,而是历史数据。
这个是从官方文档中获取的资料,解释在当前读下Innodb使用next-key lock锁来解决幻读问题。
“To prevent phantoms, InnoDB uses an algorithm called next-key locking that combines index-row locking with gap locking. InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
”
“大致意思,为了防止幻读,Innodb使用next-key lock算法,将行锁(record lock)和间隙锁(gap lock)结合在一起。Innodb行锁在搜索或者扫描表索引时,会在遇到的索引记录上设置共享锁或者排它锁,因此行锁实际是索引记录锁。另外, 在索引记录上设置的锁同样会影响索引记录之前的“间隙(gap)”。即next-key lock是索引记录行加上索引记录之前的“gap”上的间隙锁定。
”
二、next-key lock 加锁规则
加锁规则总结为以下几点,不同MySQL版本会有微小的差异
查询过程中只要访问的数据都会加锁,加锁的基本单位是next-key lock,左开右闭 唯一索引等值查询,next-key lock退化为行锁 索引等值查询,需要访问到第一个不满足条件的值,此时的next-key lock会退化为间隙锁 索引范围查询需要访问到不满足条件的第一个值为止
之前看过丁老师的文章说是在唯一索引下,范围查询会访问到不满足条件的第一个值为止,这个问题在MySQL8.0.18已经修复了
目前咔咔使用的MySQL版本是 8.0.26 ,接下来根据这几条规则设计几条SQL,一起来看看都锁了那些数据。
创建next_key_lock表,建表的初始化语句如下。
CREATE TABLE `next_key_lock` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`class` tinyint(4) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_class` (`class`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO next_key_lock (`class`,`name`) VALUES (1,'咔咔'),(3,'小刘'),(8,'小张'),
(15,'小李'),(20,'张但'),(25,'王五'),(25,'李四');
三、唯一索引等值查询
下图是SQL的执行流程,分为了三个终端,按照终端顺序来执行SQL

分析这条SQL满足那些规则
规则一:查询过程中只要访问到的数据都会加锁,加锁的基本单位是next-key lock,左开右闭状态。
规则二:唯一索引等值查询,next-key lock退化为行锁。
规则三:索引等值查询,需要访问到第一个不满足条件的值,此时的next-key lock会退化为间隙锁
根据规则一,加锁范围为(7,∞]
根据规则二,退化为行锁,但明显此条SQL不满足条件,因为表里边就不存在id=9的这条记录,所以此条规则不生效
根据规则三,next-key lock退化为间隙锁,加锁范围为(7,∞)
结论
得知唯一索引等值查询时,行数据存在的时候是行锁,行数据不存在,那就是间隙锁。
因此终端2的语句会一直处于等待状态,直到终端1执行完成。
四、普通索引等值查询
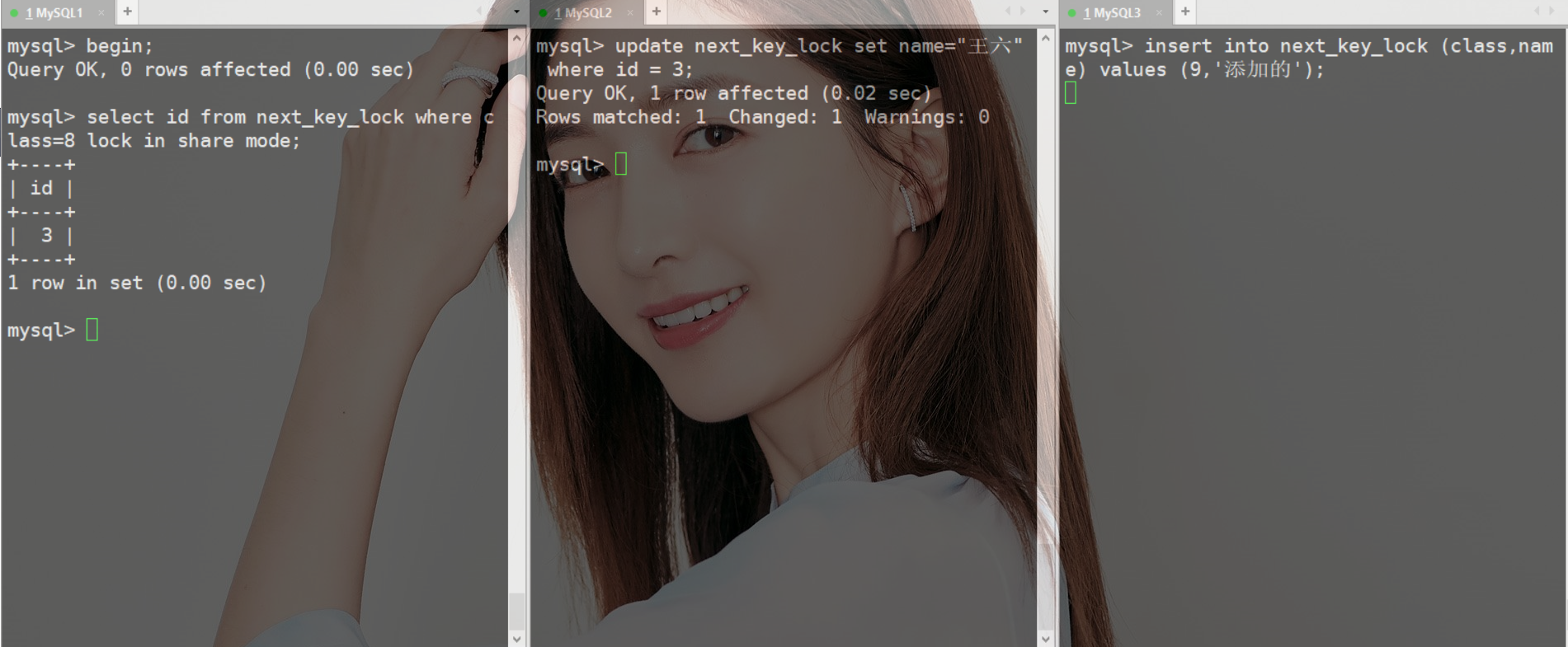
分析这条SQL满足那些规则
规则一:查询过程中只要访问到的数据都会加锁,加锁的基本单位是next-key lock,左开右闭状态。
规则二:索引等值查询,需要访问到第一个不满足条件的值,此时的next-key lock会退化为间隙锁
根据规则一,加锁范围是(3,8]
根据规则二,需要访问到第一个不满足的值,加锁范围(8,15],有因为会退化为间隙锁,加锁范围变为(8,15)
结论
三条SQL执行后,你看到的现象是MySQL2执行成功,MySQL3SQL等待
MySQL3要加入的值是9,在锁范围内所以需要等MySQL1提交事务后才可执行成功。
为什么MySQL2为什么会执行成功
总结的加锁规则中,查询过程中访问到的数据都会加锁,但MySQL2使用的覆盖索引,所以并不需要回表查询主键索引,所以主键索引上是没有加任何锁的。
你要理解这块就需要知道主键索引、普通索引的索引结构,在B+tree中主键索引叶子节点存储的是整行数据,而普通索引叶子节点存储的是主键的值。
扩展
现在你知道了在这个例子中,lock in share mode值锁覆盖索引,但是如果是for update就会给主键索引上满足条件的行加上行锁。所以你也知道了使用了覆盖索引是避免不了数据被更新的,若想实现数据避免更新就需要绕过覆盖索引的优化。
现在你应该知道使用for update会给主键索引加锁,如果查询条件为普通索引但值是存在多个相同数据的,此时的加锁就会根据主键索引加锁。
五、主键索引范围锁
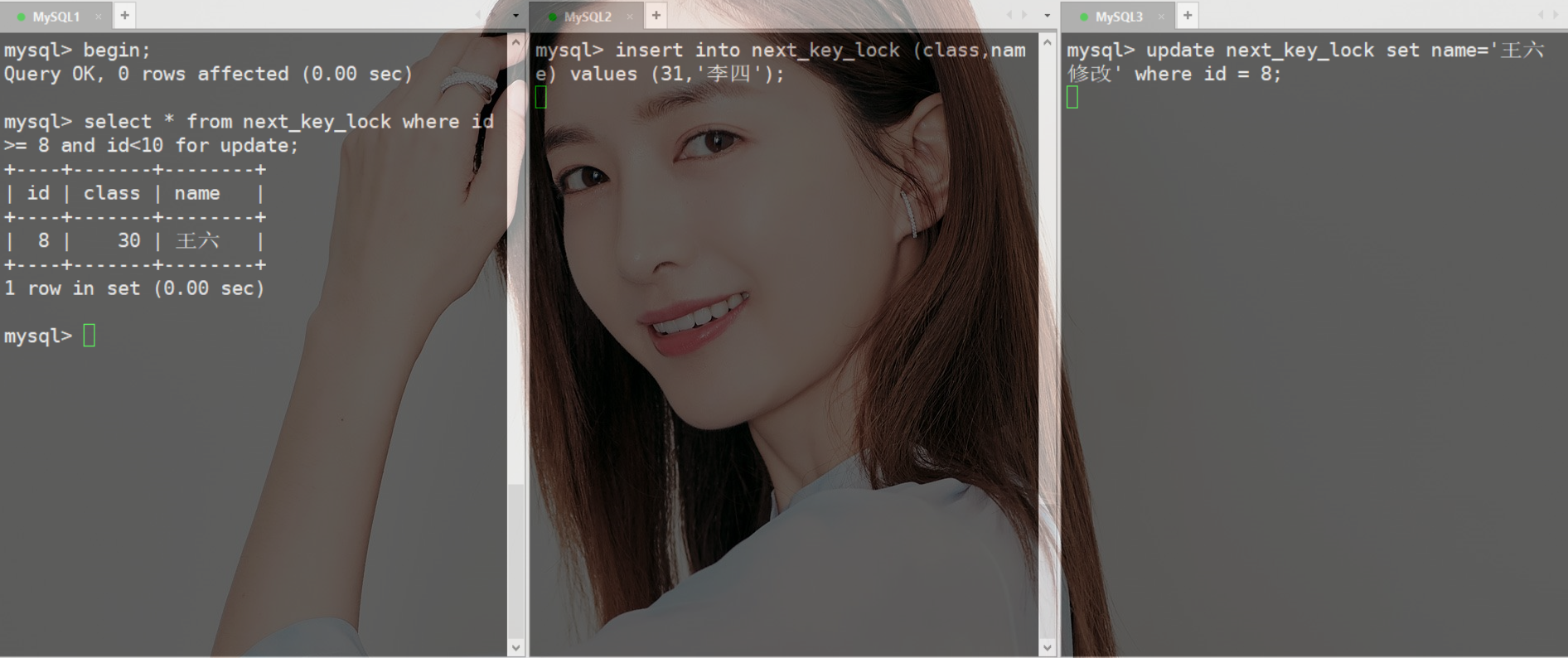
从上图得知MySQL2和MySQL3都处于等待MySQL1中
分析这条SQL满足那些规则
规则一:访问到的数据都会加锁
规则二:唯一索引等值查询,next_key_lock退化为行锁
规则三:索引范围查询需要访问到不满足条件的第一个值为止
根据规则一,加锁范围(7,8]
根据规则二,退化为行锁,加锁范围只是id=8这一行(后边解释)
根据规则三,范围查询就往后继续找,加锁范围(8,∞]
结论
此条SQL加锁范围,行锁id=8,next_key lock(8,∞]
问题:为什么从next-key lock退化为行锁
首先你需要明白所谓的等值判断和范围判断,指的是这一行数据被查询选中的时候走的判断条件是通过 a=b 还是 a>b或a<b 来确定的,直白点就是这行数据是通过等值来的还是范围查询来的。
从SQL返回结果可得知数据是根据id=8来的,因此next-key lock会退化为行锁。
六、普通索引范围锁
执行SQL为
select * from next_key_lock where class >= 8 and class<10 for update;
可以看到这个SQL跟第五案例的MySQL1的唯一区别是普通索引没有退化行锁的规则。
分析这条SQL满足那些规则
规则一:索引等值查询需要访问到第一个不满足的值,next_key lock 退化为间隙锁
规则二:索引范围查询需要访问到不满足条件的第一个值为止
根据规则一,加锁范围(7,8]
根据规则二,加锁范围(8,15]
结论
加锁范围为(7,8]、(8,15]
问题:为什么没有退化为间隙锁
仔细看规则,索引等值查询需要访问到不满足的值才会退化为间隙锁,此时是可以访问到8这个数据的,因此不会退化为间隙锁。
七、普通索引倒叙范围锁
在以上的所有案例中都是默认正序规则,接下来看下倒叙时的加锁规则是怎么样的
执行SQL为
select * from next_key_lock where class >= 15 and class<=20 order by desc lock in share mode;
由于SQL加上了order by ,因此第一个要定位class索引最右边的值,也就是class=20,因为class是普通索引等值查询,因此会加上next-key lock 左开右闭(15,20],普通索引等值查询会访问到不满足条件的值为止,所以还会继续扫描,直到遇到25,又会加上一个next-key lock (20,25],又因为25不满足查询条件,因此会退化为间隙锁(20,25)
还有一个条件是class >= 15,向左扫描到class = 8才会停下来知道了是小于15了,加锁单位是next-key loc ,左开右闭范围是(3,8]
又因为查询是*,绕过了覆盖索引,需要回表查询,因此给主键ID也会加锁,加锁为id=4,id=5两个行锁。
结论
因此这条SQL加锁范围在索引class是(3,25),主键索引上id=4,5两个行锁。
八、总结
本期文章带大家了解next_key lock的加锁范围,并且给大家总结了四条加锁规则,经过五个实战案例给再给大家说几个注意点。
唯一索引等值查询时next-key lock退化为行锁,这里指查询到数据,若没有查到数据则依然是间隙锁
普通索引等值查询next-key lock退化为间隙锁
最后一点当SQL加上排序时加锁规则会有一定的变化,在后期文章中咔咔也会不断的提供很多案例供大家查看。
“坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。
”