常见查询语句:
select .... from .... where .. group by ... having ... order by .. limit...
输出 获取数据 过滤 分组 过滤 排序 限定个数
以上为书写顺序,以下为执行顺序:
from -> where -> group by - >select - > having -> order by -> limit
例如:在select中定义的别名,在其之前是不能出现的;在之后可以再利用。
group by分组:
select * from 表名 group by 字段
表示该表的字段进行分组查询时,只输出该字段分组下的第一个出现的数据。
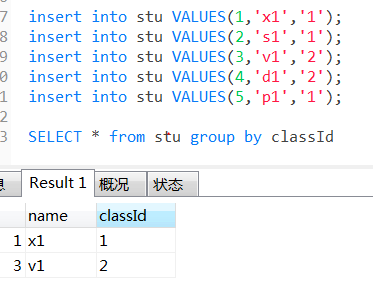
group by与聚合函数count()
出现select count(1) ,classId from stu group by classId,则输出结果为
分组后的对应的和
对比select count(name),如果name中有null,那么count不会记录null直接跳过,判断下一个是否为Null,其他情况二者一致。
select count(distinct name) from stu group by classId
表示按classId分完组后,各自除去相同名字后累加的行数。
聚集函数:
count --计数
sum -- 求和
max -- 最大值
min -- 最小值
avg -- 平均值
group - concat
truncate 表名;//清空表的内容
mysql中 group by的执行机制是先对分组的字段进行排序的,默认升序的
select * from mysql_day1 GROUP BY clid DESC; //改成降序的
having :有时候限定分组条件比对元组限定条件更有用
例:select classId from mysql_day1 group by clid having count(1)>2
实现查询班级人数大于2的班级号
order by: 对结果集进行排序;
例如: order by clid,id;
先对clid排序,再对id排序(后一个在前一个相同的情况下才排序)
case when ..then..用法:
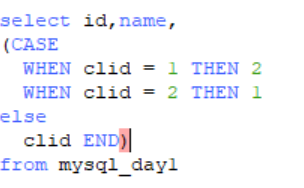
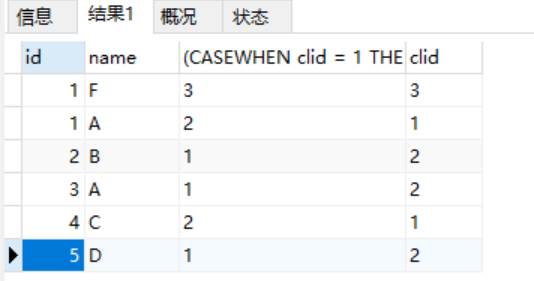
case when 与聚集函数:
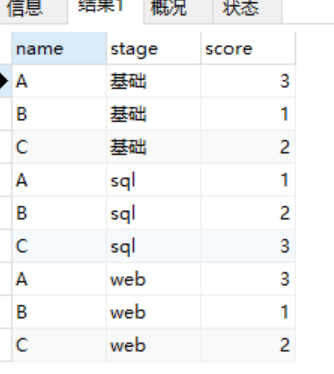
若想查找成
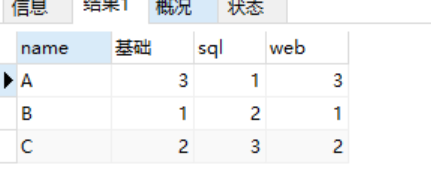
利用分组group by后,重新写出三列,利用case when 实现
select name,
max(case when stage = '基础' THEN score ELSE NULL END)as '基础',
max(case when stage = 'sql' THEN score ELSE NULL END)as 'sql',
max(case when stage = 'web' THEN score ELSE NULL END)as 'web'
from scores group by name
注意: 使用聚合函数max的目的是找出分组后的各个字段对应的值