1.什么是kafka?
kafka是分布式发布-订阅消息系统,是一种分布式的消息队列工具
kafka是一个分布式的,可分区的,可复制的消息系统
kafka对消息保存的时候根据topic进行分类,发送消息者称为Producer,消息接受者称为consumer,此外kafka集群由多个kafka实例组成,每个实例称为broker
依赖zookeeper来保证系统的可用性,保存元数据信息
2.kafka主要概念
topic主题
一个topic是对一组消息的归纳
在一个Kafka集群中,可以创建多个topic主题,以topic主题为单位管理消息,kafka中多个topic主题之间是互相隔离互不影响,从而可以在一个Kafka集群中通过创建多个topic主题实现不同的使用者独立使用不同topic主题而互不影响。
partition分区
topic可以划分出多个分区,利用分区机制保证每个分区的数据量不会太大, 可以在单个服务器上保存
分区是kafka实现负载均衡和失败恢复分布式数据存储的基本单元
每个分区可以单独发布和消费,为并发操作topic提供了可能
offset序号
每个分区都由一系列有序的,不可变的消息组成,这些消息被连续追加到分区中
分区中的每个消息都由一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。
可以设置消息的保存策略,制定保存期限,在期限到来之前,数据会一直存在,无论是否被消费国,当保存期限结束,消息会被连续的擦除,释放空间
一系列的机制保证了kafka当中数据的连续读写磁盘,保证了性能,从而使得kafka的性能与数据量无关,只和磁盘的性能是常量级的
Replication复本
每个分区拥有若干复本,这些复本存放在不同的服务器中
若干个副本中,有一个称为leader负责读写操作,而其他的作为Leader,负责同步leader中的数据,对外只提供读的能力
kafka不是以broker为单位划分leader,follwer,而是以副本为单位划分;这样,集群中的每一个broker是持有一部分分区的leader和另一部分分区的follwer,从而将写的压力分摊到不同的broken中取,利用分布式分摊写的压力,提升性能
Producer生产者
生产者将消息发布到制定的主题中,默认使用简单的负载均衡机制选择分区,如果需要可以通过特定的分区函数选择分区,制定发布到哪个分区
Consumer消费者
Consumer负责消费主题中的数据,消费时由Consumer自己来维护会话产生的数据,实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset,一般情况下随着Consumer不断的读取消息,这offset的值不断增加,从而实现连续读取数据
Broker
集群汇中的一台或多台服务器统称为broker
消费者消费数据的模式
发布订阅模式:多个Consumer可以同时从服务端读取数据,Consumer之间互不影响,每个Consumer都可以读取到全量的数据。达成了多个Consumer之间共享数据的效果。
队列模式:多个Consumer可以同时从服务端读取消息,每个消息只被其中一个Consumer读到。达成多个Consumer之间竞争数据的效果。
消费者组的概念
在Kafka中可以将多个消费者组成一个消费者组。
在消费者组内,多个消费者而形成竞争状态,互相抢夺数据。同一份消息只能被一个消费者组内的消费者消费一次。
在消费者组之间,多个消费者形成共享状态,共享数据。同一份消息会同时被多个消费者组各自消费到
3.kafka的设计
吞吐量
数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能
zero-copy:减少IO操作步骤
数据批量发送
数据压缩
Topic划分为多个partition,提高parallelism
负载均衡
producer根据用户指定的算法,将消息发送到指定的partition
存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上
多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over
通过zookeeper管理broker与consumer的动态加入与离开
拉取系统
kafka broker会持久化数据,broker没有内存压力,因此,consumer非常适合采取pull的方式消费数据
consumer根据消费能力自主控制消息拉取速度
consumer根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等
可扩展性
当需要增加broker结点时,新增的broker会向zookeeper注册,而producer及consumer会根据注册在zookeeper上的watcher感知这些变化,并及时作出调整。
4.kafka的主要特点
- 同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
- 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online和offline的场景。
5.kafka文件存储机制
同一个topic下有多个不同的partition,每个partition为一个目录,partition命名的规则是topic的名称加上一个序号,序号从0开始。

每一个partition目录下的文件被平均切割成大小相等(默认一个文件是500兆,可以手动去设置)的数据文件,
每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。
默认保留7天的数据。
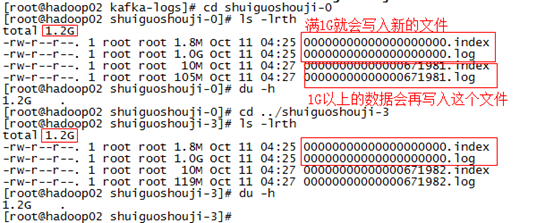
每个partition下都会有这些每500兆一个每500兆一个(当然在上面的测试中我们将它设置为了1G一个)的segment段。
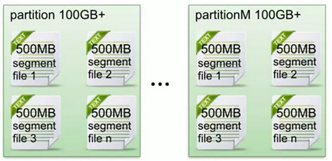
另外每个partition只需要支持顺序读写就可以了,partition中的每一个segment端的生命周期是由我们在配置文件中指定的一个参数觉得的。
比如它在默认情况下,每满500兆就会创建新的segment段(segment file),每满7天就会清理之前的数据。
它的一个特点就是支持顺序写。如下图所示:
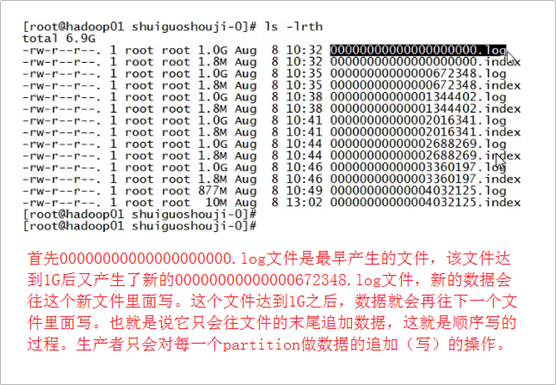
首先00000000000000000000.log文件是最早产生的文件,该文件达到1G(因为我们在配置文件里面指定的1G大小,默认情况下是500兆)
之后又产生了新的0000000000000672348.log文件,新的数据会往这个新的文件里面写,这个文件达到1G之后,数据就会再往下一个文件里面写,
也就是说它只会往文件的末尾追加数据,这就是顺序写的过程,生产者只会对每一个partition做数据的追加(写)的操作。
问题:如何保证消息消费的有序性呢?比如说生产者生产了0到100个商品,那么消费者在消费的时候安装0到100这个从小到大的顺序消费,
那么kafka如何保证这种有序性呢?难度就在于,生产者生产出0到100这100条数据之后,通过一定的分组策略存储到broker的partition中的时候,
比如0到10这10条消息被存到了这个partition中,10到20这10条消息被存到了那个partition中,这样的话,消息在分组存到partition中的时候就已经被分组策略搞得无序了。
那么能否做到消费者在消费消息的时候全局有序呢?遇到这个问题,我们可以回答,在大多数情况下是做不到全局有序的。但在某些情况下是可以做到的。 比如我的partition只有一个,这种情况下是可以全局有序的。那么可能有人又要问了,只有一个partition的话,哪里来的分布式呢?哪里来的负载均衡呢?
所以说,全局有序是一个伪命题!全局有序根本没有办法在kafka要实现的大数据的场景来做到。但是我们只能保证当前这个partition内部消息消费的有序性。 结论:一个partition中的数据是有序的吗?回答:间隔有序,不连续。 针对一个topic里面的数据,只能做到partition内部有序,不能做到全局有序。特别是加入消费者的场景后,如何保证消费者的消费的消息的全局有序性,
这是一个伪命题,只有在一种情况下才能保证消费的消息的全局有序性,那就是只有一个partition!
Segment file是什么? 生产者生产的消息按照一定的分组策略被发送到broker中partition中的时候,这些消息如果在内存中放不下了,就会放在文件中,
partition在磁盘上就是一个目录,该目录名是topic的名称加上一个序号,在这个partition目录下,有两类文件,一类是以log为后缀的文件,
一类是以index为后缀的文件,每一个log文件和一个index文件相对应,这一对文件就是一个segment file,也就是一个段。
其中的log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,索引文件记录了元数据信息。
说到segment file的索引文件和数据文件的一一对应,我们应该能想到storm中的Ack File机制,在spout发出去的时候要发一个Ack Tuple,
在下游的bolt处理完之后,它也要发一个Ack Tuple,这两个Ack Tuple里面包含了同样一份数据,这个数据叫做MessageId,它是一个对象,
这个对象里面包含两个比较重要的字段,一个是RootId,另一个是TupleId(也叫锚点Id),这个锚点Id会在我们发送数据的时候进行异或一下,
异或的结果才会发送给Ack那个Bolt。

Segment文件命名的规则:partition全局的第一个segment从0(20个0)开始,后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。 那么这样命令有什么好处呢?假如我们有一个消费者已经消费到了368776(offset值为368776),那么现在我们要继续消费的话,怎么做呢?
看上图,分2个步骤,第1步是从所有文件log文件的的文件名中找到对应的log文件,第368776条数据位于上图中的“00000000000000368769.log”这个文件中,
这一步涉及到一个常用的算法叫做“二分查找法”(假如我现在给你一个offset值让你去找,你首先是将所有的log的文件名进行排序,然后通过二分查找法进行查找,
很快就能定位到某一个文件,紧接着拿着这个offset值到其索引文件中找这条数据究竟存在哪里);第2步是到index文件中去找第368776条数据所在的位置。 索引文件(index文件)中存储这大量的元数据,而数据文件(log文件)中存储这大量的消息。 索引文件(index文件)中的元数据指向对应的数据文件(log文件)中消息的物理偏移地址。
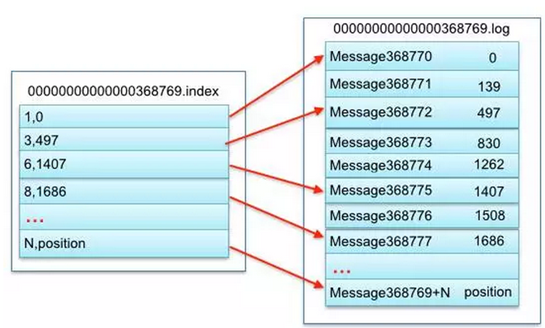
上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,
分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。 其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息),
其中497表示该消息的物理偏移地址(位置)为497。
6.kafka存储策略
kafka通过topic来分主题存放数据,主题内又有分区,分区还可以有多个副本 。
从物理结构来看,分区本身是kafka存储目录下的一个文件夹,文件夹名称是主题名加分区编号,编号从0开始
分区的内部还有segment的概念,其实就是在分区对应的文件夹下产生的文件,
一个分区会被划分为大小相等的若干个segment,一方面保证了分区的数据被划分到多个文件中(保证了文件的体积不会太大),另一方面可以基于这些segment文件进行历史数据的删除,提高效率
一个segment由一个.log和一个.index文件组成,其中.log文件为数据文件用来存储数据分段数据,.index为索引文件保存对应的.log文件的索引信息
这两个文件的命名规则:partition全局的第一个segment从0开始,后续的每个segment文件名为上一个segment文件的最后一条消息的offset值
通过查找.index文件可以获知每个存储在当前segment中的offset在.log文件中的开始位置
每条日志有固定格式:包括offset编号,日志长度,key的长度,通过这个固定格式的数据可以确定出当前offset的结束位置,从而对数据进行读取
7.kafka可靠性保障AR ISR OSR
AR
kafka分区中,维护了一个AR列表,其中包括了所有的分区的副本编号,AR分为ISR和OSR
ISR
同步列表,只有当所有的ISR内的副本都同步了leader中的数据,数据才能被提交,才能被消费者访问
OSR
非同步列表,OSR内的副本是否同步了leader的数据,不影响数据的提交,OSR内的follower只是尽力的去同步leader,数据版本可能落后。
最开始所有的副本都在ISR中,在kafka工作的过程中,如果某个副本同步速度慢于replica.lag.time.max.ms指定的阈值,则被踢出ISR 存入OSR,如果后续速度恢复可以回到ISR中
这种方案是介于leader独裁和所有民主方式之间,更加的灵活,相对于zookeeper的过半同意过半存活机制,提供了更好的可用性。牺牲了一部分的可靠性,换来的可用性对于kafka这样的消息队列来说很有意义
8.Kafka和RabbitMQ的区别
架构方面不同
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
应用场景
RabbitMQ,循AMQP协议,用于实时的对可靠性要求比较高的消息传递上。
kafka主要用于处理活跃的流式数据,大数据量的数据处理上
吞吐量
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
9.kafka生产者生产数据的可靠性
生产者向leader发送数据时,可以选择需要的可靠性级别
通过request.required.acks参数设置(0:至多一次,1:至少一次,-1:刚好一次)
0(至多一次):
生产者不停向leader发送数据,而不需要leader反馈成功消息,这种模式效率最高,可靠性最低,可能在发送过程中丢失数据。可能在leader宕机时丢失数据(可能因为网络的不稳定丢失数据。Leader宕机后,宕机期间没有接受到数据,就丢失了)
1(默认,至少一次):
producer在ISR中的leader已成功收到数据并得到确认后才会发送下一条数据,如果等待响应超时,生产者自动重发数据。(不会因为网络不稳定而丢失,但可能在leader宕机而新数据未同步完成时,因新的leader选举后截断未同步数据而造成丢失数据。如果网络不稳定,在重发的过程中,可能会导致多数据)
-1(恰好一次)
producer需要等待ISR中的leader和所有follower都确认接收到数据后才算一次发送完成,才会发送下一条数据,如果等待响应超时,生产者自动重发,数据可靠性最高(效率很低)。
但是这样也不能保证数据完全不丢失,例如当ISR中只有leader时,此时,leader宕机,如果不允许OSR中的follower成为新的leader可以保障写入数据的一致性,但除非原来的leader恢复,否则集群一直无法恢复。或者可以允许OSR列表中的follower成为新的leader,但此时存在写数据不一致的风险。
kafka还提供了min.insync.replicas参数,这个参数要求ISR列表中至少要有指定数量个副本leader才可以接受数据
即使配置request.required.acks=-1,min.insync.replicas=2,也只能保证第二个层面的可靠性,即不丢数据,但仍可能多数据。如果想要实现恰好一次的语义,则需要在这个基础上进一步的加上去重机制
Kafka提供了GUID机制,能够在客户端根据算法为每条日志增加一个全局唯一标识,重发时会保持GUID一致,从而实现了标识每条数据。
10.消费者是从leader中拿数据,还是从follow中拿数据?
kafka是由follower周期性或者尝试去pull(拉)过来(其实这个过程与consumer消费过程非常相似),
写是都往leader上写,但是读并不是任意flower上读都行,读也只在leader上读,flower只是数据的一个备份,
保证leader被挂掉后顶上来,并不往外提供服务。
11.说说kafka的ISR机制?
- kafka 为了保证数据的一致性使用了isr 机制,
- 1. leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护
- 2. 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
- 3. 当ISR中所有Replica都向Leader发送ACK时,leader才commit
12.SparkStreaming连接kafka如何保证数据的不重复不丢失
sparkStreaming接收kafka数据的方式有两种:
1.利用Receiver接收数据;
2.直接从kafka读取数据(Direct 方式)
保证数据不丢失
(1)Receiver方式为确保零数据丢失,必须在Spark Streaming中另外启用预写日志(Write Ahead Logs)。这将同步保存所有收到的Kafka数据到分布式文件系统(例如HDFS)上,以便在发生故障时可以恢复所有数据。
(2)Direct方式依靠checkpoint机制来保证。每次streaming 消费了kafka的数据后,将消费的kafka offsets更新到checkpoint。当你的程序挂掉或者升级的时候,就可以接着上次的读取,实现数据的零丢失。
(Direct需要用户采用checkpoint或者第三方存储来维护offsets,而不像Receiver-based那样,通过ZooKeeper来维护Offsets,此提高了用户的开发成本)
kafka的acks参数有一个非常重要的作用。如果acks设置为0,表示Producer不会等待Broker的响应,Producer无法确定消息是否发送成功,可能会导致数据丢失,但acks值为0时,会得到最大的系统吞吐量。如果acks设置为1,表示Producer会在leader Partition收到消息并得到Broker的一个确认,这样会有更好的可靠性。如果设置为-1,Producer会在所有备份的Partition收到消息时得到Broker的确认,这个设置可以得到最高的可靠性保证。
保证数据不重复
这里业务场景被区分为两个:
幂等操作
业务代码需要自身添加事物操作
所谓幂等操作就是重复执行不会产生问题,如果是这种场景下,你不需要额外做任何工作。但如果你的应用场景是不允许数据被重复执行 的,那只能通过业务自身的逻辑代码来解决了。
这个spark给出了官方方案:
dstream.foreachRDD {(rdd, time) =
rdd.foreachPartition { partitionIterator =>
val partitionId = TaskContext.get.partitionId()
val uniqueId = generateUniqueId(time.milliseconds,partitionId)
//use this uniqueId to transationally commit the data in partitionIterator
}
}
就是说针对每个partition的数据,产生一个uniqueId,只有这个partition的所有数据被完全消费,则算成功,否则算失效,要回滚。下次重复执行这个uniqueId时,如果已经被执行成功,则skip掉。
13.kafka 是如何清理过期数据的?
kafka的日志实际上是以日志的方式默认保存在/kafka-logs文件夹中的,默认7天清理机制,
日志的真正清理时间。当删除的条件满足以后,日志将被“删除”,但是这里的删除其实只是将
该日志进行了“delete”标注,文件只是无法被索引到了而已。但是文件本身,仍然是存在的,只有当过了log.segment.delete.delay.ms 这个时间以后,文件才会被真正的从文件系统中删除。
14.一条message中包含哪些信息?
- 包含 header,body。
- 一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成。
- header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。
- 当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、 压缩格式等等);
- 如果magic的值为0,那么不存在attributes属性body是由N个字节构成的一个消息体,包含了具体的key/value消息