- 进程是计算机中资源分配的最小单位
- 一个进程可以有多个线程
- 同一个进程中的线程共享资源
- 进程与进程之间是相互隔离(如:QQ和360)
- Python中通过多进程可以利用CPU的多核优势,计算密集型操作适合用多进程开发
import multiprocessing def task(num): print("我的进程是:", multiprocessing.current_process().name, num) if __name__ == '__main__': # 创建进程 for x in range(3): process = multiprocessing.Process(target=task, args=(1,)) process.start() print("主进程结束:", multiprocessing.current_process().name)
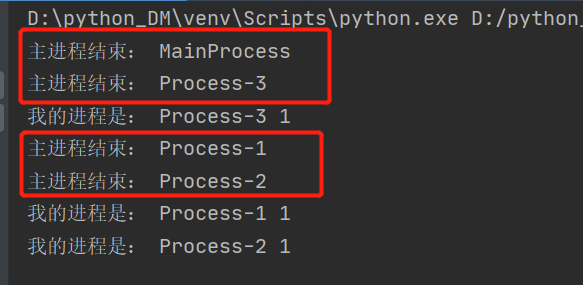
从代码来看:
- 多进程代码与多线程大同小异
- 4个进程都执行了最后一行代码
- 原因是进程之间的资源是不共享的,所以在创建子进程的时候都对主进程的资源进行了拷贝
- 拷贝的模式一共有三种
- spawn 拷贝一个python解释器
- fork拷贝模块当前的内存(子进程刚启动时候的主进程的内存)
- forkserver在代码开始运行前,会以当前代码(模块)先创建一个模板,当要创建子进程时,会拷贝这个模板
Depending on the platform,
fork,【“拷贝”几乎所有资源】【支持文件对象/线程锁等传参】【unix】【任意位置开始】【快】
The parent process uses
spawn,【run参数传必备资源】【不支持文件对象/线程锁等传参】【unix、win】【main代码块开始】【慢】
forkserver,【run参数传必备资源】【不支持文件对象/线程锁等传参】【部分unix】【main代码块开始】
When the program starts and selects the forkserver start method, a server process is started. From then on, whenever a new process is needed, the parent process connects to the server and requests that it fork a new process. The fork server process is single threaded so it is safe for it to use
import multiprocessing multiprocessing.set_start_method("spawn") # 先设置模式,在创建进程
所以当以fork模式运行时
import multiprocessing def task(num): print("我的进程是:", multiprocessing.current_process().name, num) if __name__ == '__main__': multiprocessing.set_start_method("fork") # 创建进程 for x in range(3): process = multiprocessing.Process(target=task, args=(1,)) process.start() print("主进程结束:", multiprocessing.current_process().name)
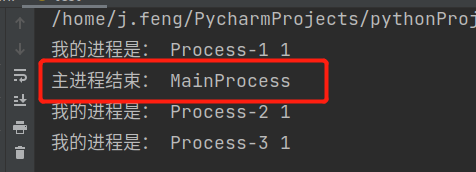
- 很明显可以看出两种模式下的区别,根本原因就是:
- spawn模式拷贝的是一个完整的python解释器,所以代码在执行的时候,依然会创建一个主进程。
- fork模式拷贝的只是这个模块,所以在代码执行的时候,只会由这个子进程来执行
fork模式的注意点:(在创建子进程时,再拷贝该模块当前的内存)
import multiprocessing import time def task(): """ 因为是拷贝了一个模块,所以子进程中也有name这个变量,注意这个name的内存是存在于子进程中的,并非主进程中的内存 因此,这个name和主进程中的name毫不相干 """ print(name) name.append(123) if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork、spawn、forkserver name = [] p1 = multiprocessing.Process(target=task) p1.start() time.sleep(2) print(name) # []
def task(): print(name) # [123] 因为name在创建子进程之前,已经追加值了,所以结论与上一段代码不冲突 if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork、spawn、forkserver name = [] name.append(123) p1 = multiprocessing.Process(target=task) p1.start()
spawn模式的注意点:(把forkserver当成spawn一样来看待就行了,同样都会将子进程当成新的主进程,执行一遍拷贝的这个模板代码)
import multiprocessing import time """ 每当有子进程启动,都会执行这个模块,因此,这个print在这个代码块中会被执行两次。 运行结果: 第一个 MainProcess 第一个 Process-1 """ print("第一个",multiprocessing.current_process().name) def task(data): """ 在spawn模式下,子进程如果需要获取主进程中main中的变量,只能在创建子进程时传递进来,当然也是不同的内存地址 name:子进程拷贝python解释器后,main中的代码并不会执行,因此子进程中的name变量并没有声明,所以报错NameError: name 'name' is not defined name1:子进程拷贝python解释器后,代码依然会从上往下运行,所以name1被声明并赋值为0,注意这个name1并不是主进程中的name1 """ # print(name) print("子进程中的name1", name1) # 子进程中的name1 0 data.append("子进程添加数据") print("子进程函数内", id(data), data) # 子进程函数内 2024973032320 ['子进程添加数据'] print("子进程函数内", multiprocessing.current_process().name) # 子进程函数内 Process-1 """ 为什么要将创建子进程的代码写入main中: -> 因为spawn模式下,会拷贝整个python解释器,当子进程start之后,这个子进程会当做主进程来执行拷贝的这个python解释器 -> 为了避免,新的主进程(由第一个主进程创建的子进程)再次创建子进程,导致无限创建子进程。 -> 所以需要将创建子进程的代码写入main中,只有在当前模块启用才创建子进程。 """ name1 = 0 if __name__ == '__main__': print("子进程不会执行到这里,为了避免递归创建子进程") multiprocessing.set_start_method("spawn") # fork、spawn、forkserver name = [] p1 = multiprocessing.Process(target=task, args=((name,))) p1.start() time.sleep(2) print("主进程", id(name), name) # 主进程 2950420364736 [] print(name1) # 0
fork练习
"""进程中的fork模式""" """ fork是可以拷贝和传递特殊对象的,如:锁、文件等 spawn和forkserver是不支持特殊对象的传递的 """ import multiprocessing def task(file_object): file_object.write("你好") file_object.flush() if __name__ == '__main__': file_object = open('x1.txt', mode='a+', encoding='utf-8') file_object.write("中国") multiprocessing.set_start_method("fork") # process = multiprocessing.Process(target=task) # 如果函数没有参数,可以选择不传递参数,创建子进程效果同下 process = multiprocessing.Process(target=task, args=(file_object,)) process.start() """ 产生的文件x1.txt的内容为: “中国你好中国” 中国 在子进程拷贝时,主进程把数据刷到了内存中,并没有写入文件 你好 子进程在把你好写入到子进程的内存中,然后使用flush刷到了文件中 中国 最后,在主进程中要结束时,文件执行close之前调用了flush把数据写入文件。 """
import multiprocessing def task(): print(name) file_object.write("你好") file_object.flush() if __name__ == '__main__': multiprocessing.set_start_method("fork") name = [] file_object = open('x1.txt', mode='a+', encoding='utf-8') file_object.write("中国") file_object.flush() p1 = multiprocessing.Process(target=task) p1.start() """ 运行结果:中国你好 中国 主进程在子进程启动之前,先把中国写入了文件,当子进程赋值主进程模块内存时,文件中已经存在数据“中国” 你好 子进程在拿到文件后,将数据立马写入了文件 """
p.start():当前进程准备就绪,等待被CPU调度(工作单元其实是进程中的线程)。 p.join():等待当前进程的任务执行完毕后再向下继续执行。 p.daemon = 布尔值:守护进程(必须放在start之前) - p.daemon = True:设置为守护进程,主进程执行完毕后,子进程也自动关闭。 - p.daemon = False:设置为非守护进程,主进程等待子进程,子进程执行完毕后,主进程才结束。 multiprocessing.current_process().name "当前进程的名称:" os.getpid():当前进程id os.getppid() :父进程id multiprocessing.cpu_count():获取cpu核心数(实际获取的是线程数)
实现进程间的数据共享一共有四种方法 Value和Array、Pipe管道(比较少用) Queues队列、(常用)Manager()
上述都是Python内部提供的进程之间数据共享和交换的机制,作为了解即可,在项目开发中很少使用,
后期项目中一般会借助第三方的来做资源的共享,例如:MySQL、redis等。
"""实现进程间的通讯(队列)""" from multiprocessing import Process, Queue # 导入多进程类和进程Queue def f(qq, data): qq.put(data) qq.put(data+"1") print("这里是f函数", qq.get()) def ff(qq, data): qq.append(data) print("这里是ff函数", qq) if __name__ == "__main__": # 创建进程队列 q = Queue() x = [] # 创建进程 """ 将主进程的队传入了子进程,实际上是复制了一份队列给到子进程, 当我们修改子进程里面的队数据时,子进程的队会将数据反序列化给到主进程, 这样就从表面上实现了主进程与子进程之间的通讯 """ proces = Process(target=f, args=(q, "你好呀")) proces1 = Process(target=ff, args=(x, "你好呀")) proces.start() proces1.start() print(q.get()) print(x) proces.join() proces1.join() """ 运行结果: 这里是ff函数 ['你好呀'] 你好呀 [] # 因为子进程会拷贝一份新的列表,并且不会将修改过的数据反序列化到主进程中,所以主进程中的数据并不会被修改 这里是f函数 你好呀1 # 因为子进程会拷贝一份新的队列,并且会将修改过的数据反序列化到主进程中,所以主进程中的队列会被修改 """
"""实现进程间的交互(管道)""" from multiprocessing import Process, Pipe # 导入进程类和管道 def f(conn): conn.send("Hello from child1") # 子进程通过管道发送数据给父进程 conn.send("Hello from child2") print(conn.recv()) # 子进程通过管道接收父进程发送的数据 if __name__ == "__main__": # 创建管道:类似于电话线,会产生电话线的两头 parent_conn, child_conn = Pipe() # 实例化子进程,将电话线的一头传递给子进程 process = Process(target=f, args=(child_conn,)) process.start() print(parent_conn.recv()) # 主进程通过管道接收子进程发送来的数据 print(parent_conn.recv()) # parent_conn.recv() # 因为子进程只发送了两条数据,父进程却接收了三条,那么程序会卡主,等待子进程发送数据 parent_conn.send("Hello from parent") process.join()
"""实现进程间的数据共享""" from multiprocessing import Process, Manager # 导入进程类和数据共享类 import os def f(d, l): # 其实他的通讯原理与队相同,都是创建了一个新的列表与字典。 # 在修改数据时,不需要加锁,Mannager已经帮我们加了 d[os.getpid()] = os.getpid() # 修改共享字典的数据 l.append(os.getpid()) # 修改共享列表的数据 if __name__ == "__main__": # 创建共享字典 d = Manager().dict() # 创建共享列表 l = Manager().list() # 创建空列表,用于存储进程地址 process_list = [] for x in range(10): p = Process(target=f, args=(d, l)) p.start() process_list.append(p) # 设置进程join() for x in process_list: x.join() print(d) print(l)
""" 进程锁 1.线程锁在spawn模式下不可以传递给子进程,但是进程锁可以传递 2.Queue和pipe不需要加锁 """ import multiprocessing from multiprocessing import Process, Array, Value # 因为在子进程task函数中修改了公共数据,所以容易发生数据混乱,因此要加锁 def task(arr, val, v, rlock): rlock.acquire() arr[0] += 1 val.value = 666 v.value = 'a'.encode('utf-8') print(arr[:], val.value, v.value) rlock.release() if __name__ == '__main__': # 注意:这些数据类型是基于C语言编写的,所以要符合C的语法要求 arr = Array('i', [0, 22, 33, 44]) # 数组:元素类型必须是int; 只能是这么几个数据 num = Value('i', 666) # int类型 v1 = Value('c') # char类型 # 存储进程的列表 process_list = [] # 创建进程锁 lock = multiprocessing.RLock() for x in range(5): process = Process(target=task, args=(arr, num, v1, lock)) process.start() process_list.append(process) # 为了主进程等待子进程执行完,代码再继续往下走,通常会这么写 for x in process_list: x.join() print("主进程中的", arr[:]) print("主进程中的", num.value) print("主进程中的", v1.value)
"""进程池""" import time from concurrent.futures import ProcessPoolExecutor def task(num): print("执行", num) time.sleep(1) if __name__ == '__main__': # 创建可容纳5进程的进程池 pool = ProcessPoolExecutor(5) for x in range(5): pool.submit(task, x) # 把任务提交给进程池,让进程池分配处理 # 等待进程池中的任务全部执行完毕,主进程在继续往下执行 pool.shutdown(True) # 默认不等待(False) print("END") """ 运行结果: 执行 0 执行 1 执行 2 执行 3 执行 4 END """
"""进程池的回调""" import time from concurrent.futures import ProcessPoolExecutor def task(num): print("执行", num) time.sleep(2) return num def done(res): time.sleep(1) print(res.result()) time.sleep(1) if __name__ == '__main__': # 创建进程池 pool = ProcessPoolExecutor(5) for x in range(5): futur = pool.submit(task, x) # futur与线程池一样,都是一个Future对象,里面记录的是子进程执行完任务的返回值 futur.add_done_callback(done) # 与线程池中的Future不同,这里回调done函数时,是有主进程来执行的 pool.shutdown(True) print("END")
"""进程池中的锁""" """ 运行结果: -> 没有加锁:文件fi.txt中的10 每次都大于0 甚至没有一次等于0 -> 加锁:文件fi.txt中的10 每次等于0 完美解决数据混乱问题 """ import time import multiprocessing from concurrent.futures import ProcessPoolExecutor def task(lock): print("%s进来了购票大厅" % multiprocessing.current_process().name) # 假设文件中保存的内容就是一个值:10 with lock: with open("f1.txt", "r", encoding="utf-8") as file: count_num = int(file.read()) print("%s开始排队了抢票了" % multiprocessing.current_process().name) time.sleep(1) count_num -= 1 with open("f1.txt", "w", encoding="utf-8") as file: file.write(str(count_num)) if __name__ == '__main__': # 创建锁 manager = multiprocessing.Manager() lock = manager.RLock() pool = ProcessPoolExecutor(5) for x in range(10): pool.submit(task, lock) pool.shutdown(True) print("抢票结束")
协程、线程、进程的区别?
线程,是计算机中可以被cpu调度的最小单元。 进程,是计算机资源分配的最小单元(进程为线程提供资源)。 一个进程中可以有多个线程,同一个进程中的线程可以共享此进程中的资源。 由于CPython中GIL的存在: - 线程,适用于IO密集型操作。 - 进程,适用于计算密集型操作。 协程,协程也可以被称为微线程,是一种用户态内的上下文切换技术,在开发中结合遇到IO自动切换,就可以通过一个线程实现并发操作。 所以,在处理IO操作时,协程比线程更加节省开销(协程的开发难度大一些)。