内置模块(一)
Python内置的模块有很多,我们也已经接触了不少相关模块,接下来咱们就来做一些汇总和介绍。
内置模块有很多 & 模块中的功能也非常多,我们是没有办法注意全局给大家讲解,在此我会整理出项目开发最常用的来进行讲解。
import os # 1. 获取当前脚本绝对路径 """ abs_path = os.path.abspath(__file__) print(abs_path) """ # 2. 获取当前文件的上级目录 """ base_path = os.path.dirname( os.path.dirname(路径) ) print(base_path) """ # 3. 路径拼接 """ p1 = os.path.join(base_path, 'xx') print(p1) p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png') print(p2) """ # 4. 判断路径是否存在 """ exists = os.path.exists(p1) print(exists) """ # 5. 创建文件夹 """ os.makedirs(路径) """ """ path = os.path.join(base_path, 'xx', 'oo', 'uuuu') if not os.path.exists(path): os.makedirs(path) """ # 6. 是否是文件夹 """ file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png') is_dir = os.path.isdir(file_path) print(is_dir) # False folder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu') is_dir = os.path.isdir(folder_path) print(is_dir) # True """ # 7. 删除文件或文件夹 """ os.remove("文件路径") """ """ path = os.path.join(base_path, 'xx') shutil.rmtree(path) """
-
-
import os """ data = os.listdir("/Users/feimouren/PycharmProjects/luffyCourse/day14/commons") print(data) # ['convert.py', '__init__.py', 'page.py', '__pycache__', 'utils.py', 'tencent']
# 无法查看文件夹中子文件夹中的文件 """ """ 要遍历一个文件夹下的所有文件,例如:遍历文件夹下的所有mp4文件
data获取到的是一个生成器,在编列生成器时,会获取到三个元素,1.文件夹路径,2.文件夹中的文件夹,3.文件
在遍历时,如果文件夹中还有文件夹,那么会继续遍历这个文件夹同样会获取三个元素。 """ data = os.walk("/Users/wupeiqi/Documents/视频教程/飞Python/mp4") for path, folder_list, file_list in data: for file_name in file_list: file_abs_path = os.path.join(path, file_name) ext = file_abs_path.rsplit(".",1)[-1] if ext == "mp4": print(file_abs_path)
import shutil # 1. 删除文件夹 """ path = os.path.join(base_path, 'xx') shutil.rmtree(path) """ # 2. 拷贝文件夹 """ shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files") """ # 3.拷贝文件 """ shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/") shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png") """ # 4.文件或文件夹重命名 """ shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png") shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images") """ # 5. 压缩文件 """ # base_name,压缩后的压缩包文件 # format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar". # root_dir,要压缩的文件夹路径 """ # shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files') # 6. 解压文件 """ # filename,要解压的压缩包文件 # extract_dir,解压的路径 # format,压缩文件格式 """ # shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
import sys # 1. 获取解释器版本 """ print(sys.version) print(sys.version_info) print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro) """ # 2. 导入模块路径 """ print(sys.path) """
import random # 1. 获取范围内的随机整数 v = random.randint(10, 20) print(v) # 2. 获取范围内的随机小数 v = random.uniform(1, 10) print(v) # 3. 随机抽取一个元素 v = random.choice([11, 22, 33, 44, 55]) print(v) # 4. 随机抽取多个元素 v = random.sample([11, 22, 33, 44, 55], 3) print(v) # 5. 打乱顺序 data = [1, 2, 3, 4, 5, 6, 7, 8, 9] random.shuffle(data) print(data)
import hashlib hash_object = hashlib.md5() hash_object.update("武沛齐".encode('utf-8')) result = hash_object.hexdigest() print(result)
import hashlib hash_object = hashlib.md5("iajfsdunjaksdjfasdfasdf".encode('utf-8')) hash_object.update("武沛齐".encode('utf-8')) result = hash_object.hexdigest() print(result) """ 在加密时,为了防止密码被撞出来,通常会在第二行代码处加盐 ,即添加我们自己知道的随机的字符串,这样就可以防止别人破解密码 """
xml
Python中的文件 - J.FengS - 博客园 (cnblogs.com)
json模块,是python内部的一个模块,可以将python的数据格式 转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。
json格式,是一个数据格式(本质上就是个字符串,常用语网络数据传输)
# Python中的数据类型的格式 data = [ {"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ('feimouren',123), ] # JSON格式 value = '[{"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18},["feimouren",123]]'
- json格式的作用?
跨语言数据传输,例如: A系统用Python开发,有列表类型和字典类型等。 B系统用Java开发,有数组、map等的类型。 语言不同,基础数据类型格式都不同。 为了方便数据传输,大家约定一个格式:json格式,每种语言都是将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。
-
Python数据类型与json格式的相互转换:
-
数据类型 -> json ,一般称为:序列化
# 实际就是将python的语法代码变成了字符串 import json data = [ {"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] res = json.dumps(data) # 里面的中文字符会根据unicode编码将中文转换成16进制 print(res) # [{"id": 1, "name": "\u98de\u67d0\u4eba", "age": 18}, {"id": 2, "name": "alex", "age": 18}] res = json.dumps(data, ensure_ascii=False) # 设置参数为False后,会保留中文 print(res) # [{"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18}]
- json格式 -> 数据类型,一般称为:反序列化
""" 反序列化,将特定的字符串变成python中有语法意义的代码""" import json data_string = '[{"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' # 将字符串data_string变成了data_list列表 data_list = json.loads(data_string) print(type(data_list), data_list) for x in data_list: print(x) """ 运行结果: <class 'list'> [{'id': 1, 'name': '飞某人', 'age': 18}, {'id': 2, 'name': 'alex', 'age': 18}] {'id': 1, 'name': '飞某人', 'age': 18} {'id': 2, 'name': 'alex', 'age': 18} """
-
-
- python的数据类型转换为 json 格式,对数据类型是有要求的,默认只支持:
+-------------------+---------------+ | Python | JSON | +===================+===============+ | dict | object | +-------------------+---------------+ | list, tuple | array | +-------------------+---------------+ | str | string | +-------------------+---------------+ | int, float | number | +-------------------+---------------+ | True | true | +-------------------+---------------+ | False | false | +-------------------+---------------+ | None | null | +-------------------+---------------+import json from decimal import Decimal from datetime import datetime data = [ {"id": 1, "name": "武沛齐", "age": 18, 'size': Decimal("18.99"), 'ctime': datetime.now()}, {"id": 2, "name": "alex", "age": 18, 'size': Decimal("9.99"), 'ctime': datetime.now()}, ] class MyJSONEncoder(json.JSONEncoder): def default(self, o): if type(o) == Decimal: return str(o) elif type(o) == datetime: return o.strftime("%Y-%M-%d") return super().default(o) res = json.dumps(data, cls=MyJSONEncoder) print(res)
- python的数据类型转换为 json 格式,对数据类型是有要求的,默认只支持:
-
json模块中常用的是:
-
-
"""将序列化的代码写入文件中使用dump""" import json data = [ {"id": 1, "name": "飞某人", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] file_object = open('xxx.json', mode='w', encoding='utf-8') json.dump(data, file_object) # 将data列表进行序列化,写入file_object.json文件中 file_object.close()
"""将文件中的特定字符串反序列化成python中的代码""" import json file_object = open('xxx.json', mode='r', encoding='utf-8') data_list = json.load(file_object) print(type(data_list),data_list) """ 运行结果: <class 'list'> [{'id': 1, 'name': '飞某人', 'age': 18}, {'id': 2, 'name': 'alex', 'age': 18}] """
-
-
import time # 获取当前时间的时间戳:自1970-1-1 00:00到现在的时间的时间差(秒) t = time.time() print(t) # 1643260394.4218106 # 获取当前地区的时区,因为我们的时间比UTC时间要快,所以得出来的是个负数 # t1/60/60 = -8 表示我们在东八区, t+t1 = 当前UTC的时间 t1 = time.timezone print(t1) # -28800 print(t1/60/60) # -8.0
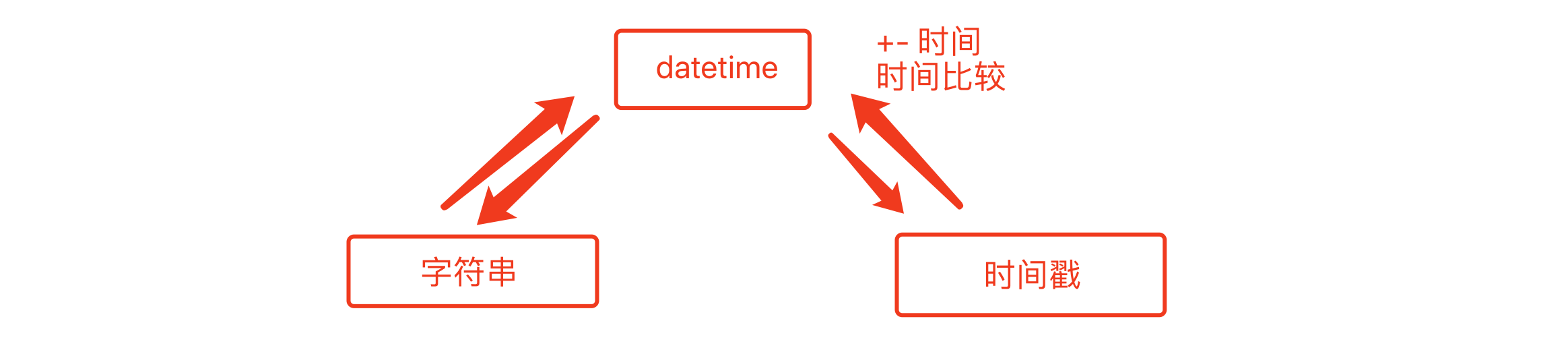
- datetime
from datetime import datetime, timezone, timedelta # 获取当前时间,获取的时间的数据类型是datetime,并不是一个字符串 t = datetime.now() print(t, type(t)) # 2022-01-27 13:20:07.358746 <class 'datetime.datetime'> # 获取当前UTC的时间 t = datetime.utcnow() print(t) # 2022-01-27 05:22:09.672516 # 获取指定时区的当前时间 t = timezone(timedelta(hours=8)) t1 = datetime.now(t) print(t1) # 2022-01-27 13:25:56.842880+08:00
# datetime类型 +/- timedelta类型 (加减都行) from datetime import datetime, timedelta, timezone t = datetime.now() t1 = timedelta(days=140, hours=50, minutes=120, seconds=120) print(t-t1) # 在现在时间的基础上减去140天50小时120分钟120秒,天时分秒这些参数可以根据需求省略 print(t+t1) # 在现在时间的基础上减去140天50小时120分钟120秒,天时分秒这些参数可以根据需求省略 # datetime之间相减,计算间隔时间(不能相加)、可以比较 # datetime类型 - datetime类型 # datetime类型 比较 datetime类型 t1 = datetime.now() t2 = datetime.utcnow() t = t1 - t2 print(t) # 8:00:00 本时区时间减去utc时间的差值(小时) print(t.days, t.seconds) # 0 28800 只能显示天与秒
-
字符串
from datetime import datetime """字符串转化为datetime格式时间""" text = "2022-1-27" text1 = "2021-1-27 12:54:25" t = datetime.strptime(text, "%Y-%m-%d") # 2022-01-27 00:00:00 <class 'datetime.datetime'> t1 = datetime.strptime(text1, "%Y-%m-%d %H:%M:%S") # 2021-01-27 12:54:25 <class 'datetime.datetime'> print(t, type(t)) print(t1, type(t1)) t2 = datetime.now() t3 = t2.strftime("%Y-%m-%d %H:%M:%S") print(t3) # 2022-01-27 17:56:12
-
时间戳
from datetime import datetime import time t1 = time.time() t2 = datetime.fromtimestamp(t1) # 将时间戳转化为datetime时间 print(t2) # 2022-01-27 18:02:30.742881 t1 = datetime.now() t2 = t1.timestamp() # 将datetime时间转换为时间戳 print(t2) # 1643277881.572226
-
|
符号 |
说明 |
|
%y |
两位数的年份表示(00-99) |
|
%Y |
四位数的年份表示(000-9999) |
|
%m |
月份(01-12) |
|
%d |
月内中的一天(0-31) |
|
%H |
24小时制小时数(0-23) |
|
%I |
12小时制小时数(01-12) |
|
%M |
分钟数(00=59) |
|
%S |
秒(00-59) |
|
%a |
本地简化星期名称 |
|
%A |
本地完整星期名称 |
|
%b |
本地简化的月份名称 |
|
%B |
本地完整的月份名称 |
|
%c |
本地相应的日期表示和时间表示 |
|
%j |
年内的一天(001-366) |
|
%p |
本地A.M.或P.M.的等价符 |
|
%U |
一年中的星期数(00-53)星期天为星期的开始 |
|
%w |
星期(0-6),星期天为星期的开始 |
|
%W |
一年中的星期数(00-53)星期一为星期的开始 |
|
%x |
本地相应的日期表示 |
|
%X |
本地相应的时间表示 |
|
%Z |
当前时区的名称 |
|
%% |
%号本身 |