想要知道ElasticSearch是如何使用的,最快的方式就是通过一个简单的例子,第一个例子将会包括基本概念如索引、搜索、和聚合等,需求是关于公司管理员工的一些业务。
员工文档索引
业务首先需要存储员工数据。这将采取一个员工文档的形式:单个文档表示单个员工。在Elasticsearch中存储数据的行为称为索引,但是在索引文档之前,我们需要决定在哪里存储它。
在Elasticsearch中,文档属于某个类型,这些类型位于索引中。可以绘制一些(粗略)与传统关系数据库的对比:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ FieldsElasticsearch集群可以包含多个索引(数据库),这些索引又包含多个类型(表)。这些类型包含多个文档(行),每个文档都有多个字段(列)。
您可能已经注意到,在Elasticsearch的上下文中,索引被重载了几个含义。如下:
- 索引(名词):正如前面所解释的那样,索引就像传统的关系数据库中的数据库一样。它是存储相关文档的地方。index的复数形式是indices或indexes。
- 索引(动词):索引一个文档是将一个文档存储在索引(名词)中,以便它可以检索和查询。它很像插入关键词SQL。此外,如果文档已经存在,新的文档将取代旧的。
- 倒排索引:关系数据库中增加一个索引,如B-树索引,对特定列为了提高数据检索的速度。Elasticsearch和Lucene提供相同目的的索引称为倒排索引。
默认情况下,文档中的每个字段索引(有一个倒排索引)这样的搜索。一个没有倒排索引字段不可搜索。
因此我们的员工目录,我们需要处理如下事情:
- 索引的每个文档,包含每个员工的所有细节。
- 每个文档都属于
employee类型。 - 类型都包含在
megacop索引中。 - 该索引将驻留我们Elasticsearch集群内。
下面通过命令去索引第一个员工:
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}注意/megacorp/employee/1包含的信息。
megacorp:索引的名称
emplogee:类型的名称
1:员工的id
成功执行返回的是一个JSON文本,包含所有关于该员工的信息。
注意:
- 如果执行过程中失败了,可能存在的原因是elasticsearch默认配置中不允许自动创建索引,所以我们可以先简单在elasticsearch.yml配置文件添加
action.auto_create_index:true,允许自动创建索引。 - 没有必要首先执行任何管理任务,如创建一个索引或指定每个字段所包含的数据类型。我们可以直接索引一个文档。Elasticsearch附带默认的一切,因此所有必要的管理任务都会使用默认值在后台处理。
在目录中添加更多的员工:
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}检索文档
现在我们有一些数据存储在Elasticsearch中,我们可以开始处理这个应用程序的业务需求。第一个要求是检索单个员工数据的能力。
这在Elasticsearch中很容易。我们只需执行HTTP GET请求并指定文档的地址——索引,类型和ID。使用这三个信息,我们可以返回原始的JSON文档,并且响应包含有关文档的一些元数据,以及Douglas Fir的原始JSON文档作为_source字段:
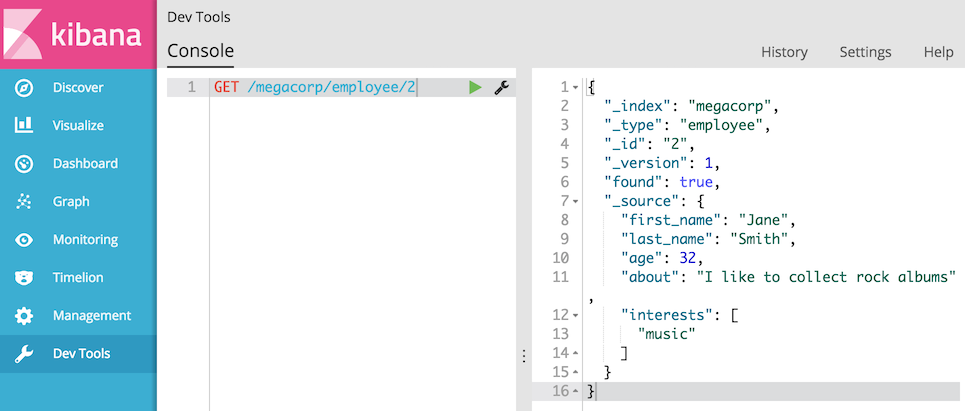
可以查看:ElasticSearch 5学习(4)——简单搜索笔记
以同样的方式,我们将HTTP动词从PUT更改为GET以便检索文档,我们可以使用DELETE动词删除文档,并使用HEAD动词检查文档是否存在。要用更新的版本替换现有文档,我们只需再次PUT。
GET很简单,可以得到要求的文件。尝试一些更高级的东西,我们可以搜索所有员工,请求:
GET /megacorp/employee/_search您可以看到我们仍在使用索引megacorp和类型employee,但是我们现在使用_search端点,而不是指定文档ID。响应包括我们在hits数组中的所有三个文档。默认情况下,搜索将返回前10个结果。
响应不仅告诉我们哪些文档匹配,而且还包括整个文档本身,以便向用户显示搜索结果的所有信息。
接下来,让我们尝试搜索在其姓氏中有“Smith”的员工。为此,我们将使用一个轻松的搜索方法,它很容易从命令行使用。此方法通常称为查询字符串搜索,因为我们将搜索作为URL查询字符串参数传递:
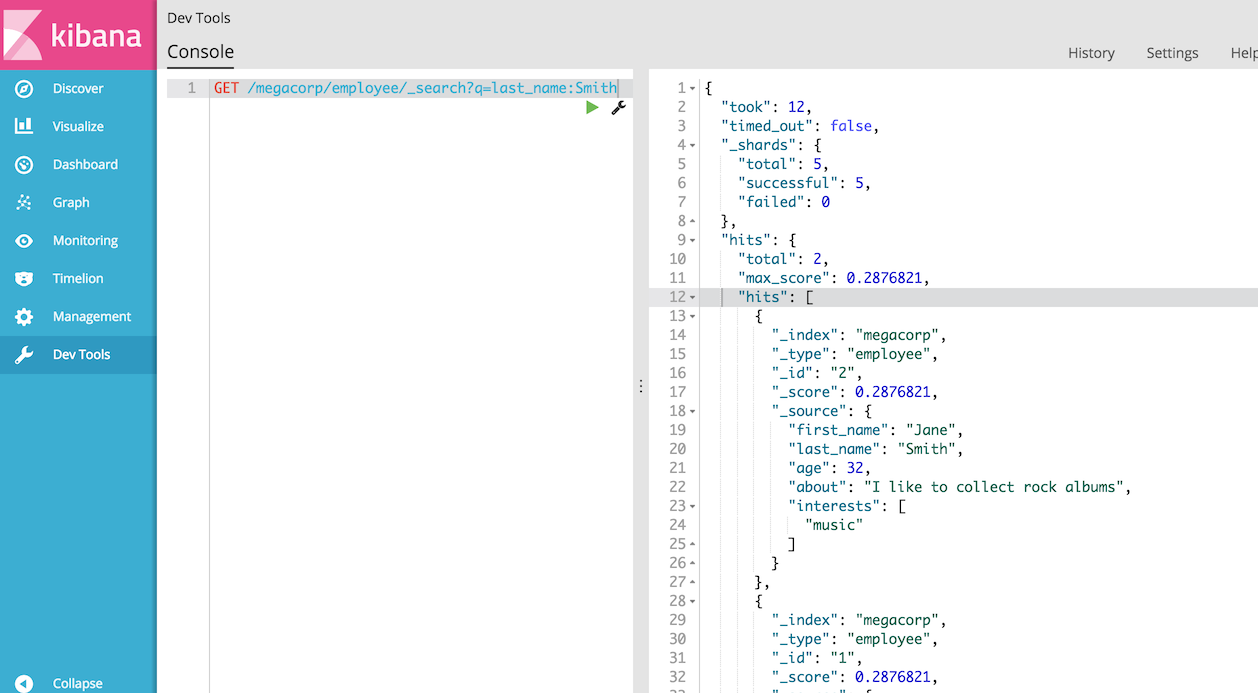
DSL查询
查询字符串搜索对于从命令行进行搜索非常方便,但它有其局限性。Elasticsearch提供了一种丰富,灵活的查询语言,称为查询DSL,它允许我们构建更复杂,更健壮的查询。
使用JSON请求正文指定域特定语言(DSL)。我们可以代表所有以前的搜索,像这样:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}这将返回与上一个查询相同的结果。可以看到一些事情已经改变。例如,我们不再使用查询字符串参数,而是使用请求正文。此请求体是使用JSON构建的,并使用匹配查询。
让我们让搜索更复杂一点。我们仍然希望找到所有名字为Smith的员工,但我们只想要30岁以上的员工。我们的查询将稍微改变一点,以容纳一个过滤器,这使我们能够有效地执行结构化搜索:
GET /megacorp/employee/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"last_name" : "smith"
}
},
"filter" : {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}我们添加了一个过滤器,执行范围搜索,并重复使用与以前相同的匹配查询。
现在我们的结果显示只有一个员工刚好是32并被命名为smith:
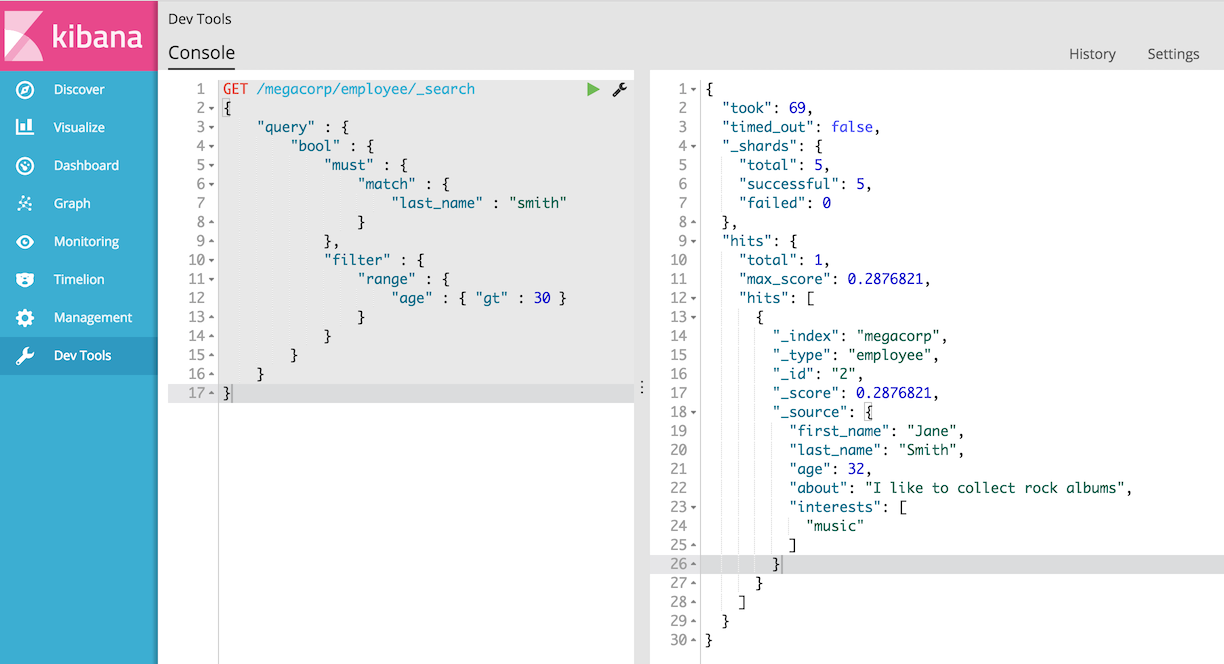
注意:关于过滤器在Elasticsearch2.0开始有很大的更新,所以有些过滤操作可能会报错。例如:filtered query已经被废弃。
全文搜索(Full-Text Search)
到目前为止的搜索很简单:单个名字,按年龄过滤。让我们尝试更高级的全文搜索,传统数据库真正难以胜任的任务。
我们将寻找所有喜欢攀岩的员工:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}您可以看到我们使用与之前相同的匹配查询来搜索关于“攀岩”字段。我们得到两个匹配的文档:
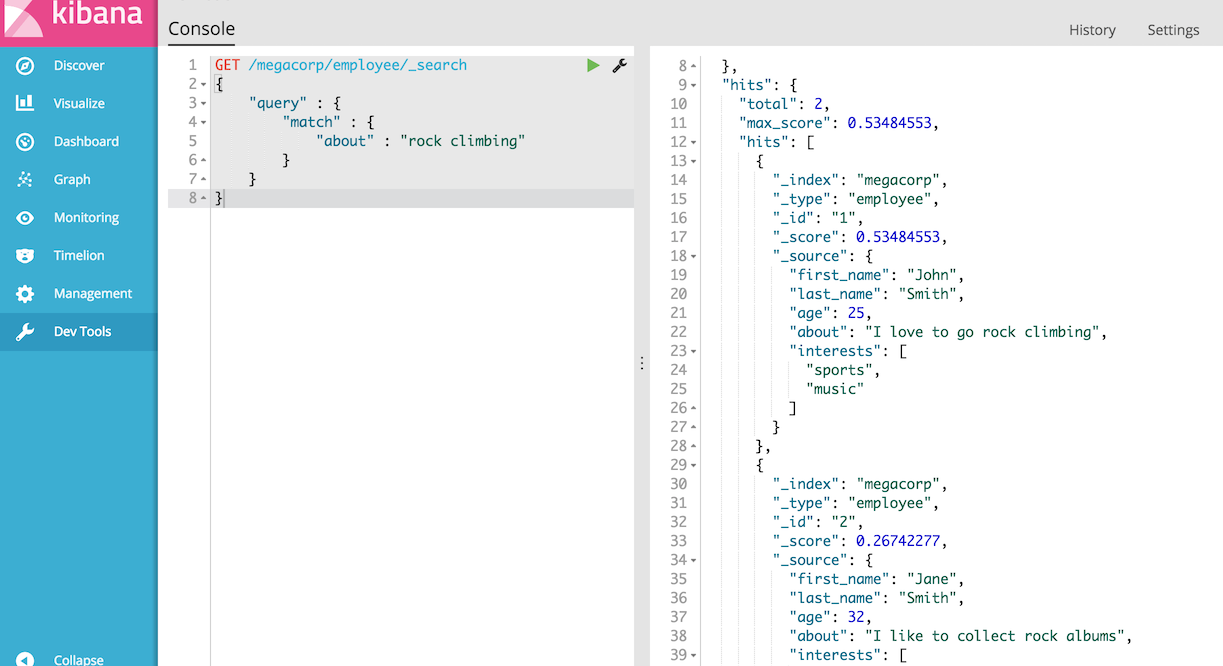
默认情况下,Elasticsearch按匹配结果的相关性分值(即每个文档与查询匹配程度)对匹配结果进行排序。第一个和最高分的结果是显而易见的:John·Smith关于字段清楚地说“攀岩”。
但为什么Jane·Smith也返回了?她的文档被返回的原因是因为在她的字段中提到了“rock”这个词。因为只有“岩石”被提及,而不是“攀登”,她的分数低于John的。
这是Elasticsearch如何在全文字段中进行搜索并返回最相关的结果的一个很好的例子。这种相关性的概念对于Elasticsearch很重要,并且是一个完全与传统关系数据库无关的概念,其中记录匹配或不匹配。
精确字段搜索
在字段中查找单个字词是很好的,但有时你想要匹配字词或短语的确切序列。例如,我们可以执行一个查询,该查询将仅匹配包含“rock”和“climbing”的员工记录,并在短语“rock climbing”中显示彼此相邻的单词。
为此,我们使用改为match_phrase查询:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}仅返回John Smith的文档
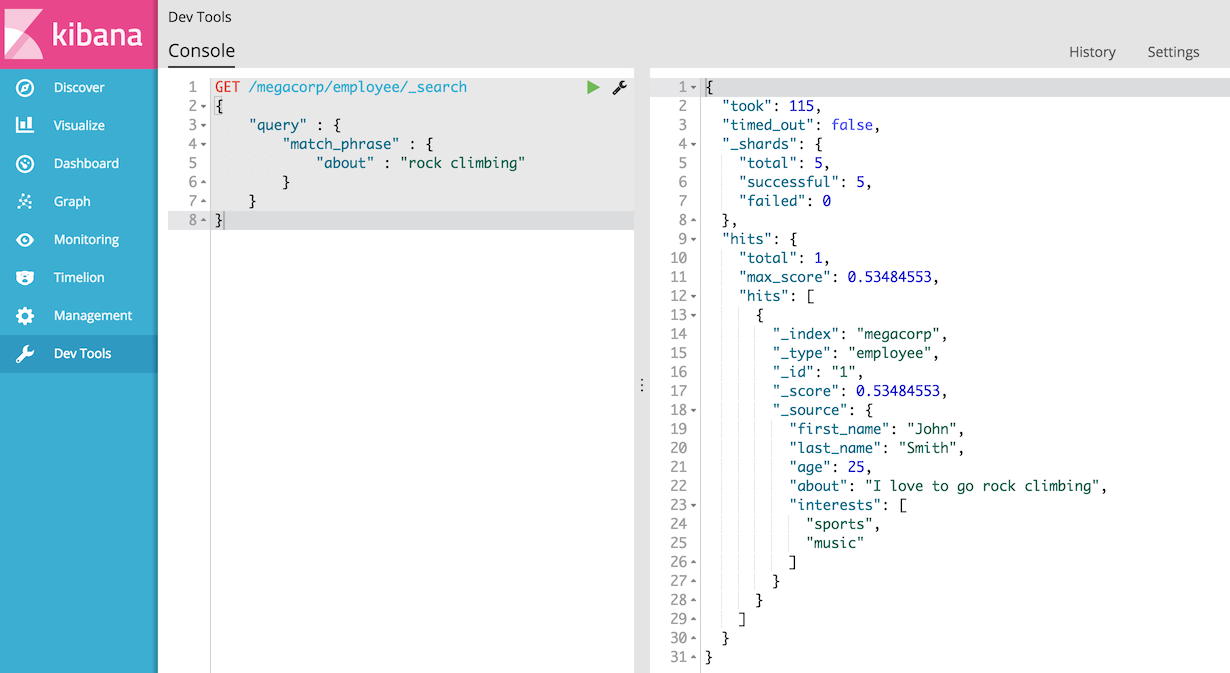
高亮搜索结果
许多应用程序喜欢从每个搜索结果突出显示文本片段,以便用户可以看到文档与查询匹配的原因。在Elasticsearch中检索突出显示的片段很容易。
让我们重新运行我们以前的查询,但添加一个新的highlight参数:
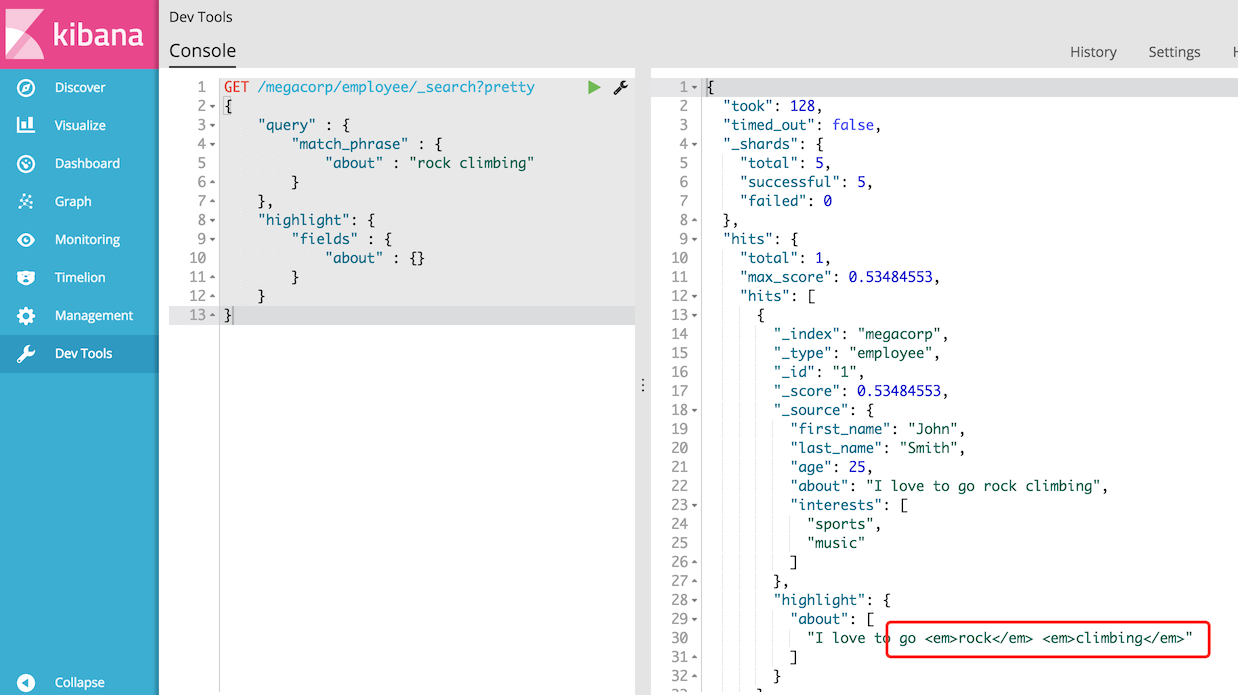
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}当我们运行此查询时,将返回与之前相同的返回,但现在我们在响应中得到一个新的部分,称为突出显示。
这包含来自about字段的文字片段,其中包含在 HTML标记中包含的匹配单词:
分析
最后,我们来到我们的最后一个业务需求:允许管理员在员工目录上运行分析。Elasticsearch具有称为聚合的功能,允许您对数据生成复杂的分析。它类似于GROUP BY中的SQL,但功能更强大。
例如,让我们找到我们的员工最喜欢的兴趣:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}如果Elasticsearch 5版本以前,将会返回:
{
...
"hits": { ... },
"aggregations": {
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}
]
}
}
}我们可以看到,两个员工对音乐感兴趣,一个在林业,一个在体育。这些聚合不是预先计算的,它们是从与当前查询匹配的文档即时生成的。
然而如果我们使用的是Elasticsearch 5版本以上的话,将会出现如下异常:
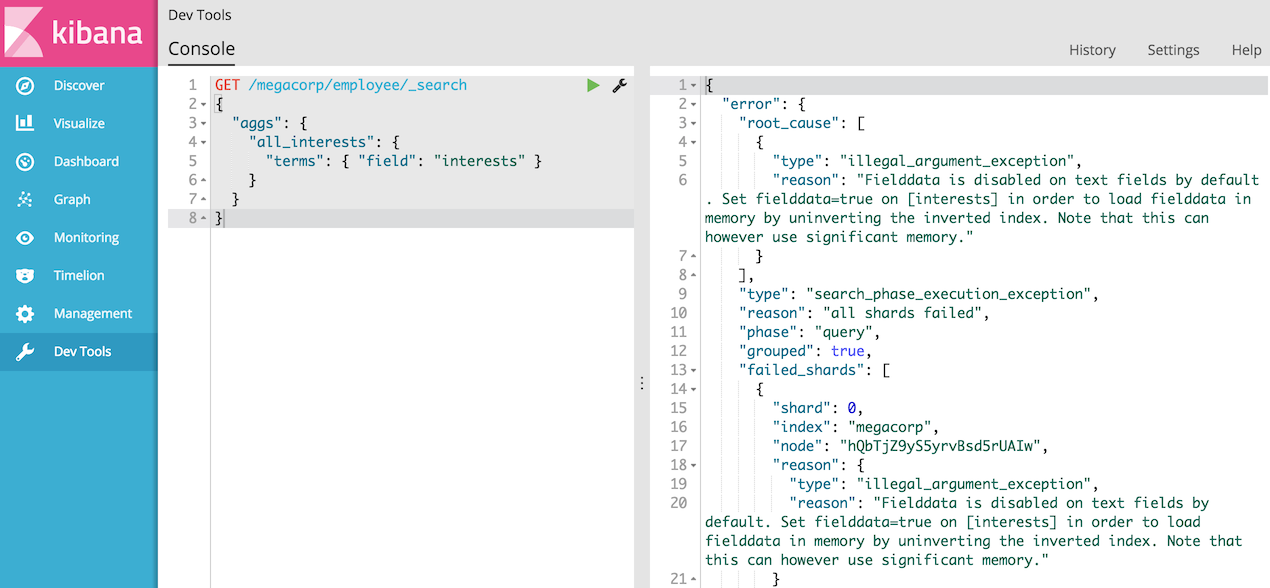
我们可以查看Elasticsearch 5.0文档——Fielddata is disabled on text fields by default
大概的意思是:Fielddata可以消耗大量的堆空间,特别是在加载高基数文本字段时。一旦fielddata已经加载到堆中,它在该段的生存期内保持。此外,加载fielddata是一个昂贵的过程,可以导致用户体验延迟命中。
所以fielddata默认禁用。如果尝试对文本字段上的脚本进行排序,聚合或访问值,就会看到这个异常,具体使用可以参考手册。
总结
这个小例子是一个很好的演示了什么是Elasticsearch。它只是很肤浅的介绍了简单的使用,许多功能被省略,以保持简短。但是这也突出了开始构建高级搜索功能是多么容易。