本文出处:http://www.cnblogs.com/wy123/p/6008477.html
关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里。 今天来写一下统计信息对于复合索引在预估时候的计算方法和潜在问题。 本文原形来自于是个实际业务问题,某SQL在利用一个符合索引做查询的时候,发现始终会出现预估误差较大的情况, 而改变复合索引的列顺序,这个预估行数的误差会发生变化, 也就是说,Create index idx_index1 ON TableName(col1,col2)与Create index idx_index2 on TableName(col2,col1) 用完全一样的的查询条件做查询,两个索引的执行计划对其预估的行数是不一样的 究其原因在哪里呢?
先造一个测试环境:

CREATE TABLE TestStatistics
(
COL1 INT IDENTITY(1,1) ,
COL2 INT ,
COL3 DATETIME ,
COL4 VARCHAR(50)
)
GO
INSERT INTO TestStatistics VALUES (RAND()*10,CAST(GETDATE()-RAND()*300 AS date),NEWID())
GO 1000000
问题重现
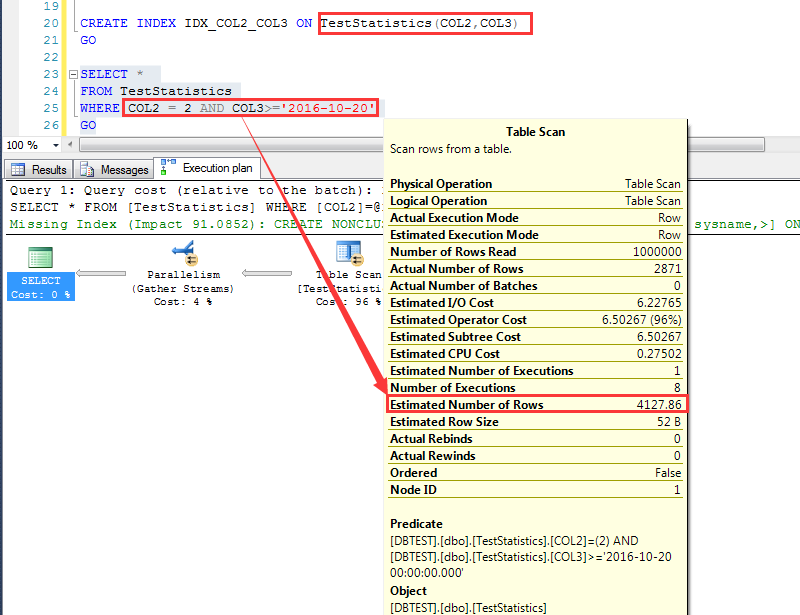
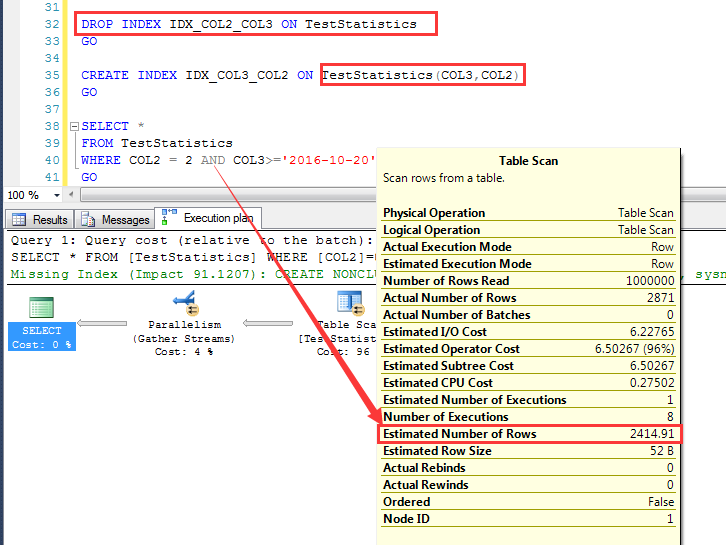
首先看一个非常有意思的问题, 在同一张表上, 先这么建一个索引:CREATE INDEX IDX_COL2_COL3 ON TestStatistics(COL2,COL3) 执行一个查询,预估为4127.86行 然后DROP掉上面的索引,继续创建一个索引:CREATE INDEX IDX_COL3_COL2 ON TestStatistics(COL3,COL2) 注意COL2和COL3的顺序不一致 继续执行上面的查询(查询条件不变,数据不变,仅仅是索引列顺序发生了变化),这一次预估为2414.91行
查询条件一样,数据也一样,为什么改变复合索引列顺序会影响到执行计划对数据行的预估呢?
首先来看第一个索引时候的预估算法:
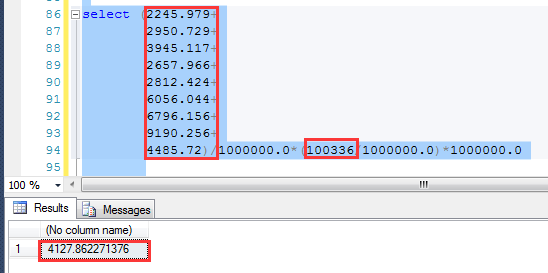
这个查询他预估为4127.86行,如下图
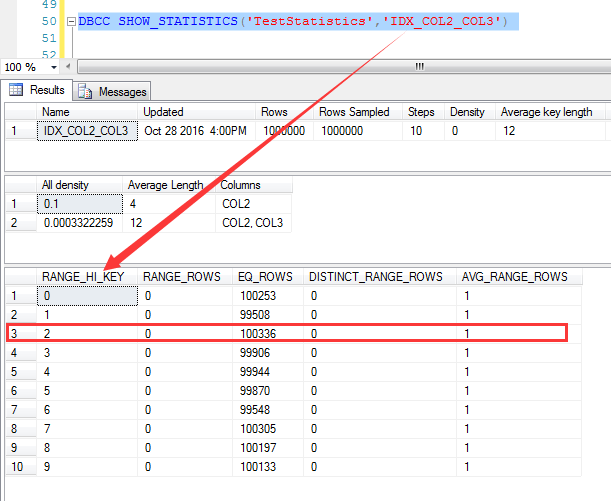
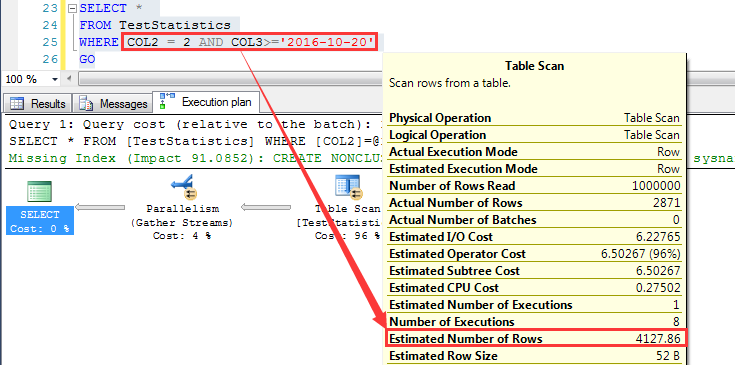
说起来预估,就离不开统计信息,首先来看IDX_COL2_COL3这个索引的统计信息, 我们知道,对于复合索引,统计信息中只有前导列的统计数据,也就是说IDX_COL3_COL2这个索引只有COL2这个列的统计信息,如下截图 对于COL2=2的统计信息,统计为100336行,我们记住这个数字
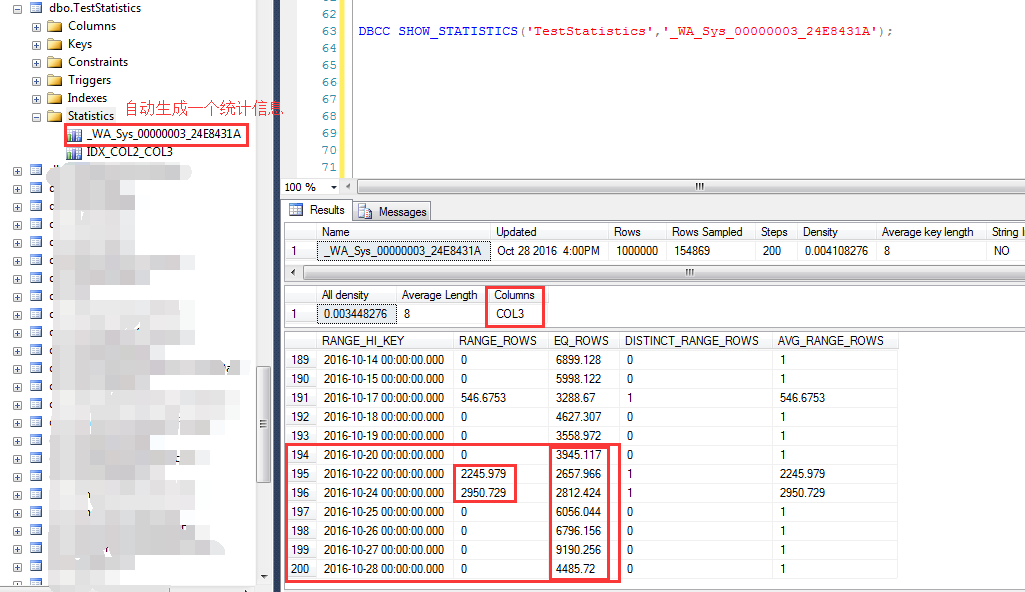
统计信息的另外一个特点就是在会在查询列(非索引列)上自动创建统计信息,如下截图 查询执行过程中,自动创建了一个名字为:_WA_Sys_00000003_24E8431A的统计信息 这个统计信息就是对COL3列的统计,可以发现在大于等于2012-10-20之后的统计行数
在SQL Server 2012中,对数据行的预估计算方式是各个字段的选择性的乘积, 假如Pn代表不同字段的密度,那么预估行数的计算方法就是: 预估行数=p0*p1*p2*p3……*RowCount 可以利用这个算法,计算目前数据下,预估出来的结果:4217.86,跟执行计划预估是一致的,非常完美!
当删除了IDX_COL2_COL3重建建立顺序为COL3+COL2的索引的时候,预估如下
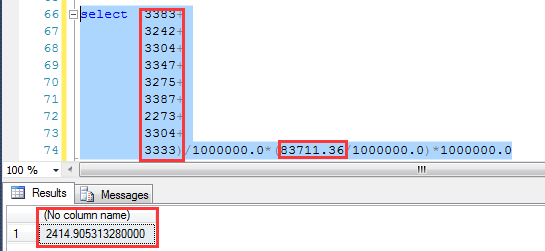
与上面同样的查询条件,预估为2414.91行
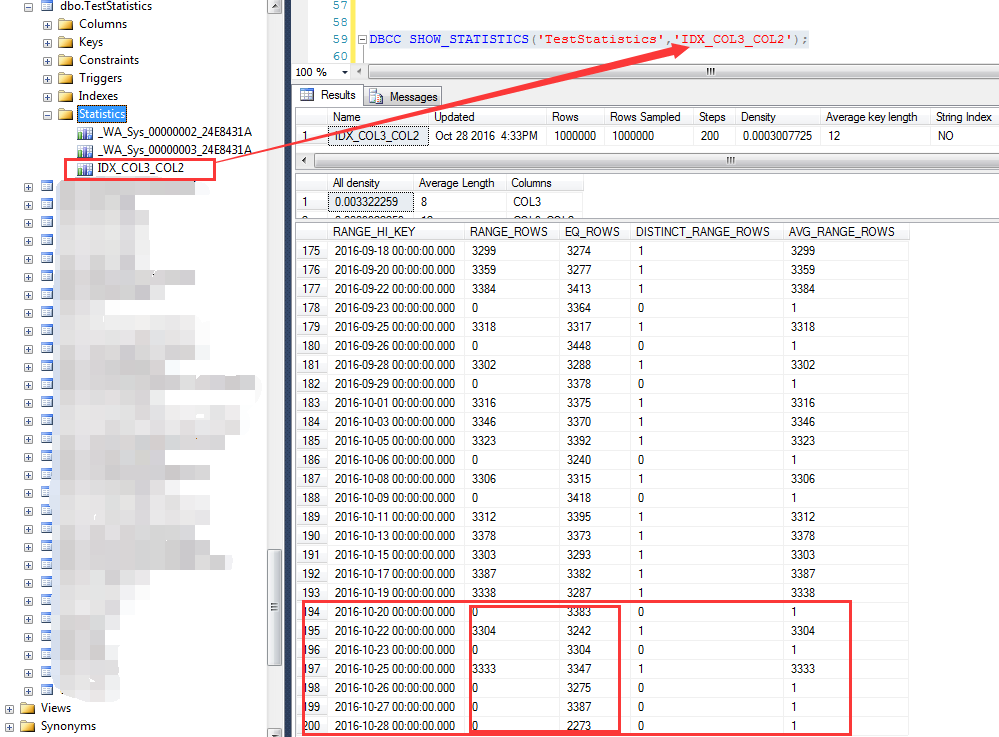
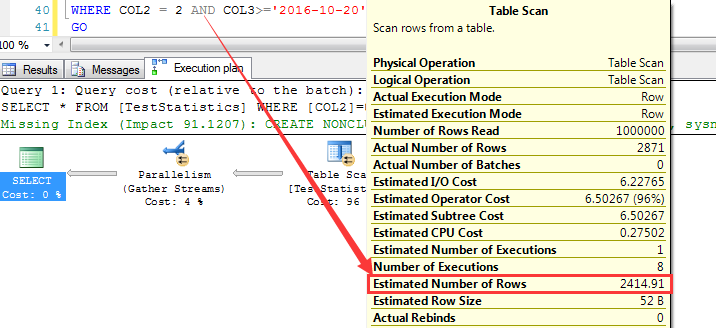
依据上面的分析步骤,首先来分析索引列上的统计信息,如下截图为大于等于2016-10-20之后的预估行数
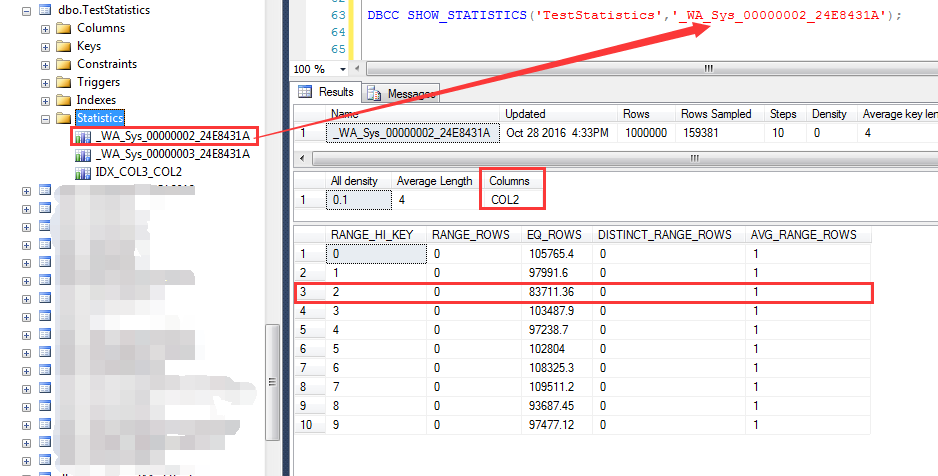
同理,本次查询也会自动建立COL2列上的统计信息(IDX_COL2_COL3索引被删除),观察这个统计信息对COL2=2的预估为83711.36行
同样我们利用上述公式,来计算预估的行数:2414.9035行,也非常完美地吻合和执行计划预估的结果
至此,应该很清楚一开始的问题了,就是为什么复合索引列顺序不一致,在查询的时候导致预估也不一致的原因。 最根本的原因有就是: 符合索引上只有前导列的统计信息,查询引擎会根据需要自动创建非前导列的统计信息, 但是,非常关键一点,如果细心的话,你会发现查询引擎自动创建的统计信息的取样行数都不是100%取样的,这一点非常关键 正是因为非前导列取样有一定的误差,导致在预估算法的时候,也即 预估行数=p0*p1*p2*p3……*RowCount的时候,密度值是不一样的 也即在创建IDX_COL2_COL3的时候,统计出来的COL2密度为P1_1,COL3密度为P2_1, 创建IDX_COL3_COL2的时候,统计出来的COL2密度为P1_2,COL3密度为P2_2,因为P1_1<>P1_2,P2_1<>P2_2 因此,计算出的结果就是P1_1*P2_1<>P2_1*P2_2,原理很简单,希望看官能明白。
照这么计算,对于两个顺序不同的统计信息,如果P1_1=P2_1并且P2_1=P2_2,那么乘积就是一样的,预估行数也就是一样的,那么是不是呢?
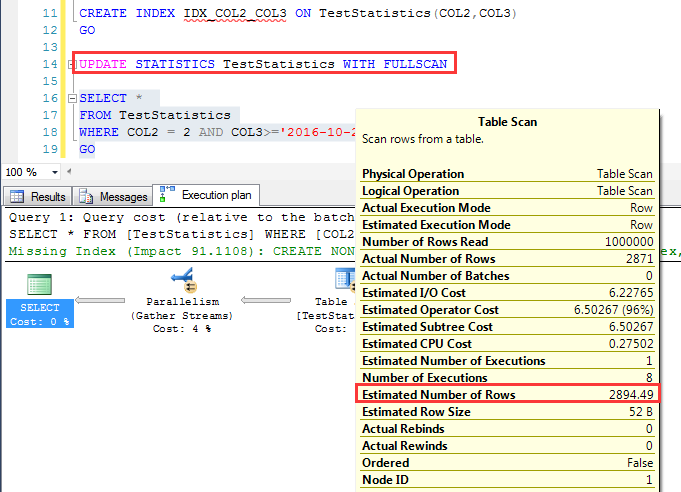
对于不同顺序的两个索引,先看COL2,COL3顺序的索引 在查询一次之后(建立了统计信息),执行一个百分之百取样(WITH FULLSCAN)的统计信息更新 重新来看其预估行数,这一次预估为:2894.49
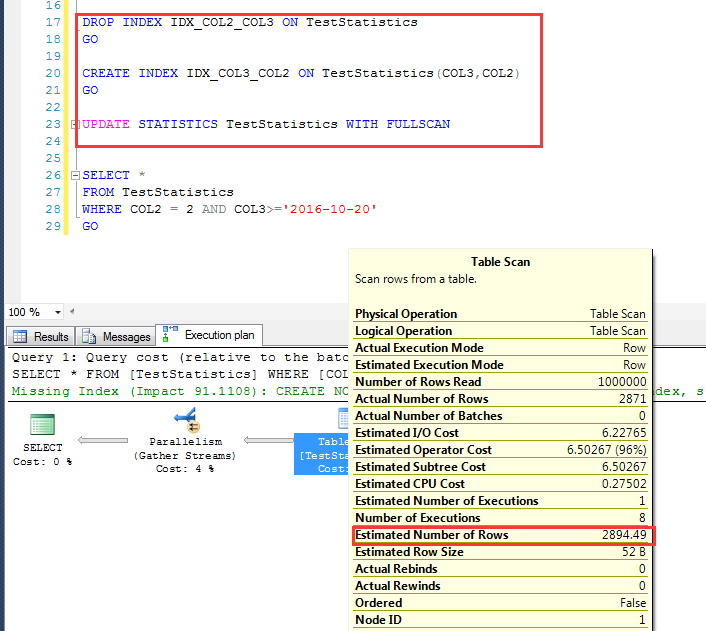
删除COL2,COL3顺序的索引,建立COL3,COL2为顺序的索引 在查询一次之后(建立了统计信息),执行一个百分之百取样(WITH FULLSCAN)的统计信息更新 重新来看其预估行数,这一次预估为:同样为2894.49,是吻合上述算法
总结:
文本简单演示了执行计划利用统计信息预估的算法和原理,以及在计算预估行数时候可能受到的干扰因素, 这就要求我们在建立索引的时候,不仅仅是说我建一个复合索引就完事了,也要注意其索引列的顺序对执行计划预估的影响, 更重要的是,要注意查询引擎自动生成的统计信息对预估的影响程度。
抛开统计信息谈索引的,都是耍流氓。抛开统计信息取样百分比谈统计信息的,也是耍流氓。
引申出来另外一个问题:维护统计信息的时候,能只更新索引列的统计信息,忽略非索引列的统计信息吗?