队列作为一种比较抽象的数据结构,在程序世界中被广泛的应用,而实现方式和形态也各式各样,有使用进程内堆栈实现的,如stl库中的queue;有基于管道、Shmem实现的,如常见的同机进程间通信模型,而随着分布式系统应用越来越广泛,跨机通信的场景需来需多,面临的问题不仅是消息投递问题,分布式系统普适性的挑战也随着应用场景的多样性而越来越多。
一个优秀的分布式消息队列,个人分析应该具备以下的能力:高吞吐、低时延(因场景而异),传输透明,伸缩性强,有冗灾能力,一致性顺序投递,同步+异步的发送方式,完善的运维和监控工具,开源。但上面的能力有一些在设计理念上可能是相悖的,或者是应用场景不同,在最终的实现上会有所侧重。以腾讯互娱内部广泛使用的TBUSTBUSD为例,最为看重的是一致性顺序投递以及低时延,但传输上做不到透明,需要使用者手工初始化队列,了解整个网格的拓扑,另外故障后也需要手工处理。和TSFG的负责人沟通,新版本在研发中的TBUS正在解决这个问题,从而减少使用者的学习和运营成本。
消息传输模型
从消息传输模型上,大致可以抽象为以下几种:
点对点模型(Point-to-point)
基础模型中,只有一个发送者、一个接收者和一个分布式队列。如下图所示:

生产者消费者模型(Producer–consumer)
如果发送者和接收者都可以有多个部署实例,甚至不同的类型;但是共用同一个队列,这就变成了标准的生产者消费者模型。在该模型,三个角色一般称为生产者(Producer)、分布式队列(Queue)、消费者(Consumer)。

发布订阅模型(PubSub)
如果只有一类发送者,发送者将产生的消息实体按照不同的主题(Topic)分发到不同的逻辑队列。每种主题队列对应于一类接收者。这就变成了典型的发布订阅模型。在该模型,三个角色一般称为发布者(Publisher),分布式队列(Queue),订阅者(Subscriber)。

业界组件介绍
看下业界,开源的分布式消息队列有很多种,侧重的维度也略有不同,包括支持的消息模型也有一些差异,如果按是否有独立进程来看,可以分为两个大类:
-
Broker
Broker类的分布式消息队列,是指有独立部署进行的分布式服务,即发送者把消息发布到Broker进程,再由Broker进程推(或者是拉)给订阅者。
-
RabbitMq
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
-
RocketMq
RocketMq是由阿里研发团队开发的分布式队列,侧重在消息的顺序投递、高吞吐量、可靠性,在阿里内部大量使用,多次在云栖社区中被提及是“淘宝双11”的保障。目前已捐赠给Apache软件基金会。
-
Nats
Ruby-Nats作者开发,Derek Collison自称做了20多年的MQ,并经历过TIBOC、Rendezvous、EMC公司. 目前由Apcera公司维护,提供源码、二进制文件以及Docker镜像,用户有爱立信、HTC、百度、西门子、Vmware.Nats用Golang编写,Nats的设计思念中消息的成功投递不做保证,需要发送者自己维护,因此Nats在应用场景上还是比较有局限性。
-
Nats-streaming
目前由Apcera公司维护,也采用Golang编写,在保证吞吐量和时延的基础上,解决了Nats消息投递一致性的问题。之前和Apcera的Community Manager有过接触,Apcera目前只有5位工程师在进行开发维护,所以Nats-streaming目前支持的客户端API还比较少,只有Go、Java、Nodejs、C#,CAPI支持可能要到2017年中。
-
Kafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
-
ActiveMq
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
-
-
Brokerless
Brokerless类的消息队列,主要采用api的方式,编译到应用程序中,在应用程序间进行点对点的通信。
-
ZeroMq
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty作为传输模块)。
-
NanoMq
在技术选型时,我们一般从三个维度上去考量,吞吐量、时延、可靠性,不同的业务场景对两个维度的技术指标会有比较大的差异。 比如阿里的rocketmq,因为面临秒级的高并发场景,因此会十分看中吞吐量和消息的可靠性(不丢、顺序投递),而时延基本在100ms的级别,再比如kafka,最高的设计初衷也是做为分布式日志系统,因为看中的也是高吞吐量和可靠性。但对于游戏业务,实时音视频业务,不太会面临瞬间的访问高峰,而对低时延、时延稳定性会更加看中,一般认为消息投递应该在1-4ms以内。
-
Nats/Kafka测试
既然业界有如此丰富的组件,是否可以找到一种比TBUS更优的同时也适合游戏服务器的组件呢?带着这个问题,作者对Kafka、Nats、Nats-streaming进行了测试,主要关注时延、吞吐量、消息安全性这三个维度上。测试方法如下:搭建了两台机器,发送者和接收者在同一台物理机,broker部署在另一台机,两台机器ping时延在0.8ms左右。 测试结果如下:
- Kafka
得益于JAVA的跨平台能力,Kafka不需要安装,可直接运行。 因为Kafka借助zookeeper进行节点的故障探测与路由管理,因些需要先启动zookeeper。
测试版本为kafka_2.10-0.10.0.1 ,测试的时候碰到一些小问题,启动不成功,后面看了下,kafka启动不成功,常见的有两个问题,一是内存不够,因为java虚拟机运行时需要配置内存大小,如果内存不够可以调整下运行脚本。 二是jmx服务,注释掉bin/kafka-run-class.sh 下的这几行就ok。
# JMX settings #if [ -z "$KAFKA_JMX_OPTS" ]; then # KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false " #fi # JMX port to use #if [ $JMX_PORT ]; then # KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT " #fi
因为Kafka本周对消息是持久化的,可靠性不需要测试,因此主要关注时延和吞吐量,测试结果显示吞吐量能达到65M/s, 很显然是进行过了合包,但时延的表现不是很理想,无送包有多小,消息发送后,Consumer收到的时延的最小极限在32ms,调整了很多参数,都无然进行一步优化。
路由模式上,Kafka只支持发布订阅模型,即一个消息只能被一个访阅者收到,在这一点Nats更丰富一些。 整理的测试结果来看,Kafka做为一个分布式日志流水经营分析系统,还是很不错的,难怪很多2B的系统以及电商金融类的产品都在使用。
- Nats/Nats-streaming
正如上面介绍的,Nats是由原Ruby-Nats作者Derek Collison设计开发,目前由Apcera维护,由golang语言编写,研发团队只有5个人,受限于团队的规模,因此在API的支持上有一定的局限性。感兴趣的同学可以看下源码,协程的功能划分十分清晰,一些用法也很巧妙。 Nats和Nats-streaming最大的区别在于,Nats异步模式需要发送者自己处理消息丢失的问题,即不保证消息的“100%投递成功”,也不做消息暂存, 而Nats-streaming解决了这个问题。
在吞吐量、时延测试上,二者表现也十分优异。 作者实测结果显示,100W条消息投递时耗时在3-4s,1秒可以投递30-40w条消息,1k条消息投递耗时在1毫秒,完全可以满足像多人游戏等对时延比较挑剔的场景。
从路由模式上,Nats的支持非常丰富,支持以下三种:
Publish Subscribe
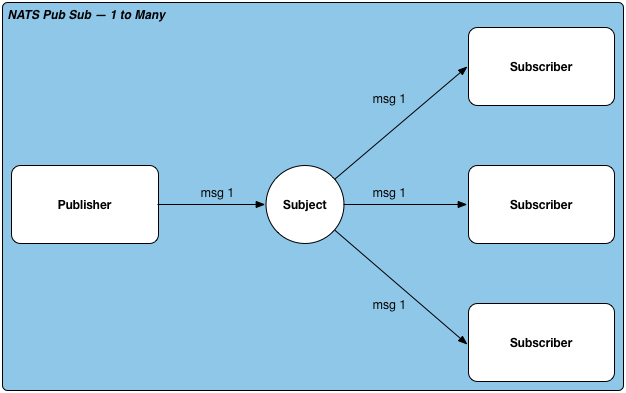
发布订阅模式,一对多,一个消息多个订阅者都可以收到,类似广播的场景。支持同步和异步调用。
Request Reply 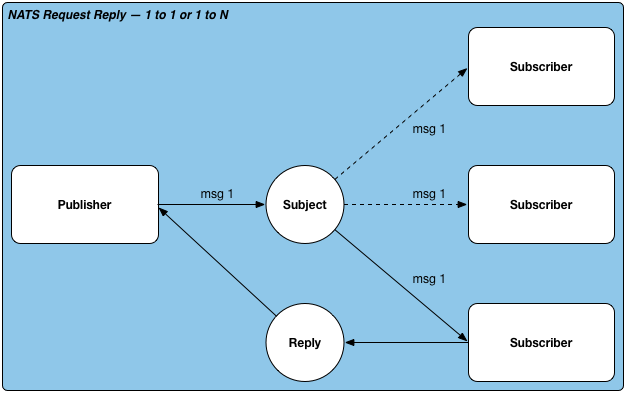
发送应答模式,Nats支持一对一和一对多的发送应答模式,可以手工指定有几个订阅者可以收到。发送应答模式采用同步调用。
Queue 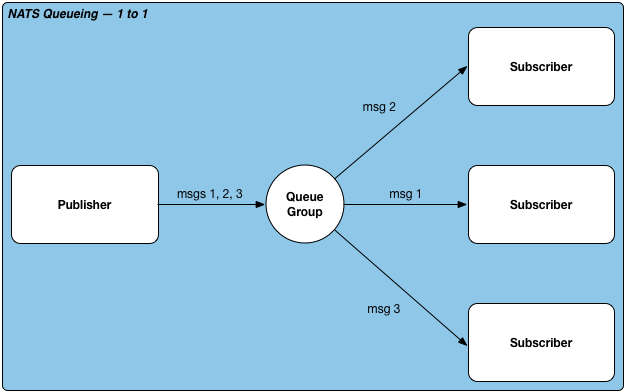
队列模式,一个消息发布后,只有一个访阅者会收到,支持同步和异步调用。这个模式对于一些无状态处理服务十分有用,比如数据仓库的无状态接入层,接入层可部署多台物理机组成一个集群,每个物理机无状态,采用这个方式即达到了冗灾能力,同时也可以保证每一个消息只会被处理一次。
从测试结果来看,Nats-streaming在安全性、时延、吞吐量上都可以达到一个比较好的水平,唯一不足的是API对各语言支持的还不够,CAPI可能要到2017年才能release.
多组件对比测试
分布式消息队列种类很多,没有精力一一测试,在网上找了一个比较权威的测试结果跟大家分享下。
测试包量和发布速率如下所示,每次测试持续时间在30S以上。
256B requests at 3,000 requests/sec (768 KB/s)
1KB requests at 3,000 requests/sec (3 MB/s)
5KB requests at 2,000 requests/sec (10 MB/s)
1KB requests at 20,000 requests/sec (20.48 MB/s)
1MB requests at 100 requests/sec (100 MB/s)
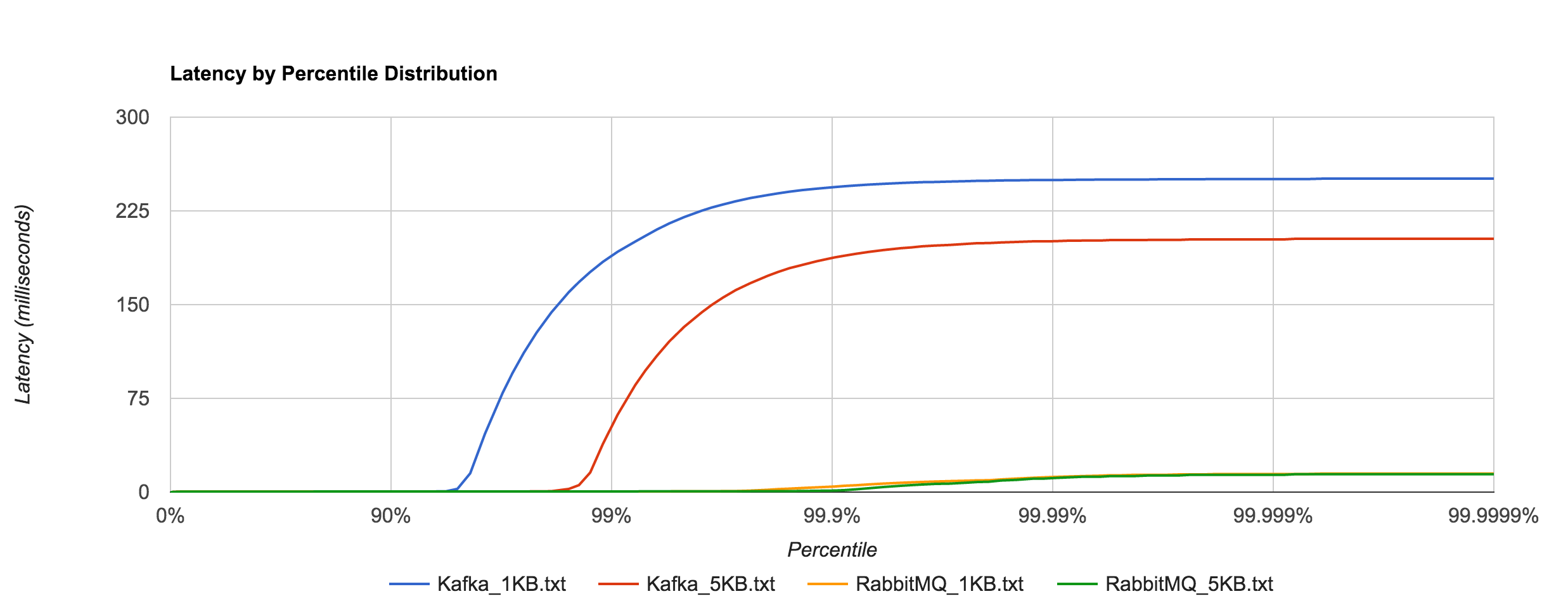
时延统计为一次发布并收到回包的整体耗时,在不同的包量和发布量的分布如下:
Nats VS Redis 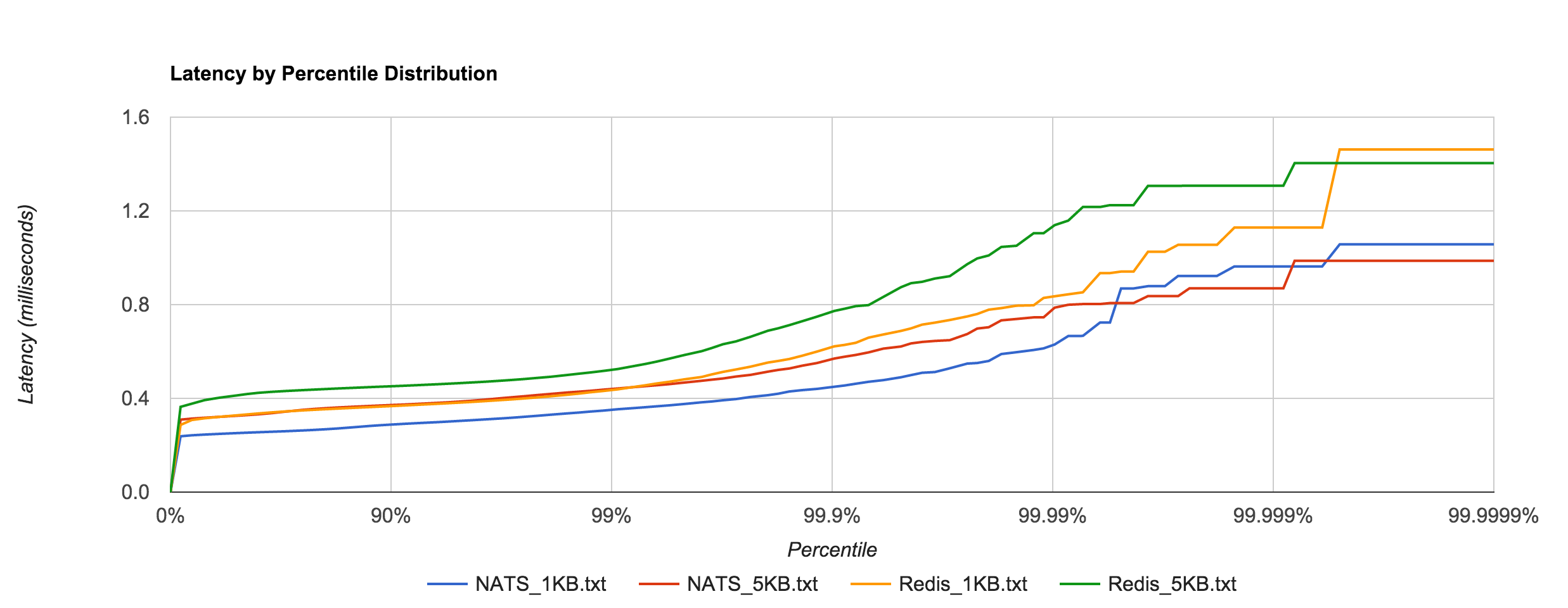
Kafka VS RabbitMQ