希尔排序
Q: 什么是希尔排序?
A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法。
A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插入排序的执行效率。
Q: 回忆之前的插入排序,有哪些缺点?
A: 回忆之前的简单排序的“插入排序”一节,在插入排序执行一半的时候,标记位i左边这部分数据项都是排过序的,而标记位右边的数据项则没有排过序。这个算法取出标记位所指的数据项,把它存储在一个临时变量里,接着,从刚刚被移除的数据项的左边第一个元素开始,每次把有序的数据项向右移动一个元素,直到存储在临时变量里的数据项能够有序回插。
A: 假设一个很小的元素在很靠近右端的位置,要把这个很小的元素移动到在左边的正确位置上,所有的中间元素都必须向右移动一位。这个步骤对每一个元素都执行了近N次的复制,虽不是所有的元素都必须移动N个位置,但是数据项平均移动了N/2个位置,就相当于执行了N次N/2个移位,总共是N2/2次复制,因此插入排序的执行效率是O(N2)。
A: 如果能以某种方式不必一个一个地移动所有中间的数据项,就能把较小的数据项移动到左边,那么这个算法的执行效率就会有很大的改进。
Q: 希尔排序的原理是什么?
A: 希尔排序通过加大插入排序中元素之间的间隔,并在这些有间隔的元素中进行插入排序,从而使数据项能大跨度地移动。当这些数据项排过一趟序后,希尔排序算法减少数据项的间隔再进行排序,依次进行下去。
A: 进行这些排序时数据项之前的间隔被称为增量,并且习惯上用字母h表示。
下图显示了增量为4时对包含10个数据项的数组进行排序的第一个步骤情况,在0、4和8号的位置上的数据项已经有序了。 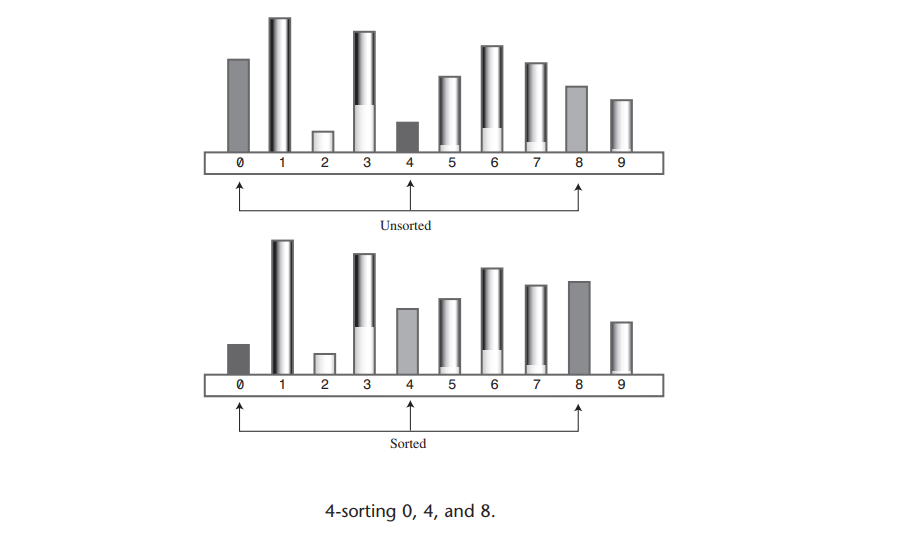
当对0、4和8号数据项完成排序之后,算法向右游一步,对1、5和9号数据项进行排序,这个排序过程持续进行,直到所有的数据项已经完成了增量为4的排序。这个过程如下图所示: 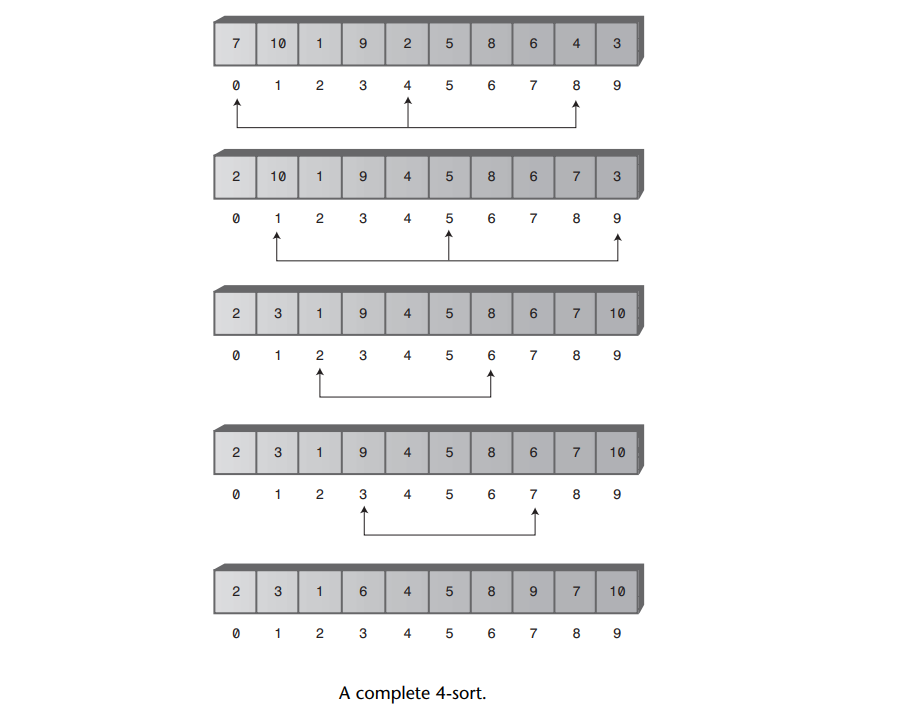
在完成增量为4的希尔排序之后,数组可以看成是有4个子数组组成:(0, 4, 8), (1, 5, 9), (2, 6), (3, 7)。这4个子数组分别完全有序,这些子数组相互交错排列,然而彼此独立。
A: 上面图解了以4为增量对包含10个数据项的数组进行排序的情况。对于更大的数组,开始的间隔也应该更大,然后间隔不断减小,直到间隔变成1。接下来就是对于任意大小的数组,如何选择间隔呢?
Q: 如何选择间隔呢?
A: 举例来说,含有1000个数据项的数组可能先以364为增量,然后以121为增量,然后以40为增量,接着以13为增量,再接着以4为增量,最有以1为增量进行希尔排序。用来形成间隔的数列(121,40,13,4,1)被称为间隔序列。这里所表示的间隔序列由Knuth提出。
A: 数列以逆向的形式从1开始,通过递归表达式h = 3 * h + 1来产生,初始值为1。下表的前两栏显示了这个公式的序列。 
A: 在排序算法中,首先在一个短小的循环中使用序列的生成公式来计算出最初的间隔。h值最初被赋值为1,然后用公式h = 3 * h + 1生成序列1,4,13,40,121,364等等。当间隔大于数组大小的时候这个过程停止。
A: 对于一个含有1000个数据项的数组,序列的第七个数字1093太大了。因此使用序列的第6个数字364作为最大的数字来开始这个排序过程,作增量为364的排序。然后,每完成一次排序全程的外部循环,用前面提供的此公式倒推式来减小间隔: h = (h - 1) / 3。这个倒推的公式生成逆置的序列364,121,40,13,4,1。从364开始,以每一个数字作为增量进行排序。当数组用增量为1排序后,算法结束。
A: 示例:ShellSort.java
Q: 有没有其他间隔序列?
A: 选择间隔序列可以称得上是一种魔法,除了h = h * 3 + 1生成间隔序列外,还有其他间隔序列。这些间隔只有一个绝对条件,就是逐渐减小的间隔最后一定要等于1,因此最后一趟排序是一次普通的插入排序。
A: 在最开始的时候,希尔排序初始的间隔为N/2,简单地把每一趟排序分成两半,因此对于大小为100的数组逐渐减小的间隔序列为50,25,12,6,3,1。这个方法的好处是不需要开始排序前为找到初始的间隔而计算序列,而只需用2整除N。但是这种证明并不是最好的数列。尽管对于大多数的数据来说这个方法还是比插入排序效果好,但是这种方法有时会使运行时间降到O(2)。
A: Flaming间隔的代码如下:
if (h < 5) {
h = 1;
} else {
h = (5 * h - 1) / 11;
}
这个方法是用2.2而非2来整除每一个间隔。对于n=100的数组,会产生序列45,20,9,4,1。这比用2整除好多了,因为这样避免了某些导致时间复杂度O(N2)的最坏情况发生。
A: 间隔序列的数字互质通常被认为很重要,也就是说除了1之外它们没有公约数,这个约束条件使每一趟排序更有可能保持前一趟排序已排好的效果。而以N/2为间隔的低效性就是归咎于它没有遵循这个准则。
A: 或许还可以设计出像上面讲述的间隔序列一样好甚至更好的序列。但是不管怎么样,都应该能够快速地计算,而不会降低算法的执行速度。
Q: 希尔排序的效率如何?
A: 迄今为止,除了在一些特殊的情况下,还没有人能够从理论上分析希尔排序的效率。有各种各样基于试验的评估,估计它的时间级是从O(N3/2)到O(N7/6) 。
A: 下表对比了速度较慢的插入排序和速度较快的快速排序,中间还列出了希尔排序的一些估计的大O值。注意Nx/y表示N的x方的y次方根(N等于100,N3/2就是1003的平方根,结果是1000)。另外(logN)2表示N对数的平方,通常协作log2N。 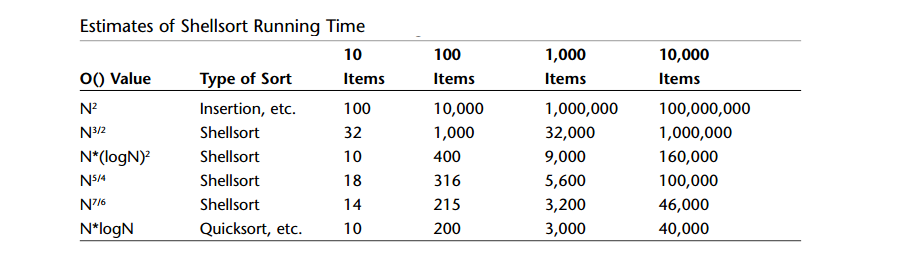
划分
Q: 什么是划分算法?
A: 划分(partitioning)是后面讨论的快速排序的根本基础,因此把它作为单独的一节来讲解。
A: 划分数据就是把数据分为两组,使所有关键字大于特定值的数据项在一组,使所有关键字小于特定值的数据项在另一组。
A: 划分算法:当leftPointer遇到比枢纽小的数据项时,它继续右移,因为这个数据项的位置已经处在数组的正确一边了。但是,当遇到比枢纽大的数据项时,它就停下来。同理rightPointer。两个内层的while循环,第一个应用于leftPointer,第二个应用于rightPointer,控制这个扫描过程,因为指针退出了while循环,所以它停止移动。下面是一段扫描不在适当位置上的数据项的简化代码:
while (leftPointer < right && mLArray[++leftPointer] < pivot) {}
while (rightPointer > left && mLArray[--rightPointer] > pivot) {}
swap(leftPointer, rightPointer);
当这两个循环都退出之后,leftPointer和rightPointer都指着在数组的错误一方位置上的数据项,所以交换这两个数据项。交换之后,继续移动这两个数据项。当两个指针最终相遇的时候,划分过程结束,并且退出外层while循环。
A: 划分算法的运行时间为O(N)。
快速排序
Q: 什么是快速排序 ?
A: 毫无疑问,快速排序是最流行的排序算法,因为有充足的理由,在大多数情况下,快速排序都是最快的,执行时间为O(N * logN)级。快速排序是在1962年由C.A.RHoare发现的。
A: 有了前面划分算法的介绍,再来理解快速排序就很容易了。快速排序算法本质上通过把一个数组划分为两个子数组,然后递归地调用自身为每一个子数组进行快速排序。
A: 基本的递归的快速排序算法代码很简单,下面是一个示例:
public void recQuickSort(int left, int right) {
if (right - left <= 0) {
// if size is 1, it's already sorted
return;
} else {
// size is 2 or larger
// partition range
int partitionIndex = partitioning(left, right);
// sort left side
recQuickSort(left, partitionIndex - 1);
// sort right side
recQuickSort(partitionIndex + 1, right);
}
}
有三个基本的步骤:
1) 把数组或者子数组划分左边和右边;
2) 调用自身对左边的进行排序;
3) 调用自身对右边的进行排序。
经过一次划分之后,所有在左边子数组的数据项都小于在右边子数组的。
只要对左边子数组和右边子数组分别进行排序,整个数组就是有序的了。
A: 如何对子数组进行排序呢?通过递归来实现。这个方法首先检查数组是否只包含一个数据项,如果数组只包含一个,那么数组就已经有序,方法立即返回,这个就是递归过程中的基值条件。
如果数组包含两个或者更多的数据项,算法就调用前面讲过的partitioning()方法对这个数组进行划分。方法返回分割边界的下标index。划分pivot给出两个子数组的分界,如下图所示。 
对数组进行划分之后,recQuickSort()递归地调用自身,数组左边的部分调用一次(从left到partitionIndex - 1位置上的数据项进行排序),数组右边的部分也调用一次(从partitionIndex + 1到right位置上的数据项进行排序)。注意这两个递归调用都不包含数组下标partitionIndex的数据项。为什么不包含这个数据项呢?难道下标为partitionIndex的数据项不需要排序?
Q: 划分应该选择什么样的枢纽(pivot)?
A: 那么partitioning()方法如何选择枢纽呢?以下是一些相关思想:
1) 应该选择具体的一个数据项的关键字的值作为枢纽:成这个数据项为pivot(枢纽);
2) 可以选择任意一个数据项作为枢纽。为了简便,我们假设总是选择待划分的子数组最右端的数据项作为pivot;
3) 划分完成之后,如果枢纽被插入到左右子数组之间的分界处,那么枢纽就落在排序之后的最终位置上了。
下图显示了用关键字为36的项作为枢纽的情况。因为不能真正像图中显示的那样把一个数组分开,所以这个图只是一个想象的情况。那么怎样才能把枢纽移动到它正确的位置上来呢? 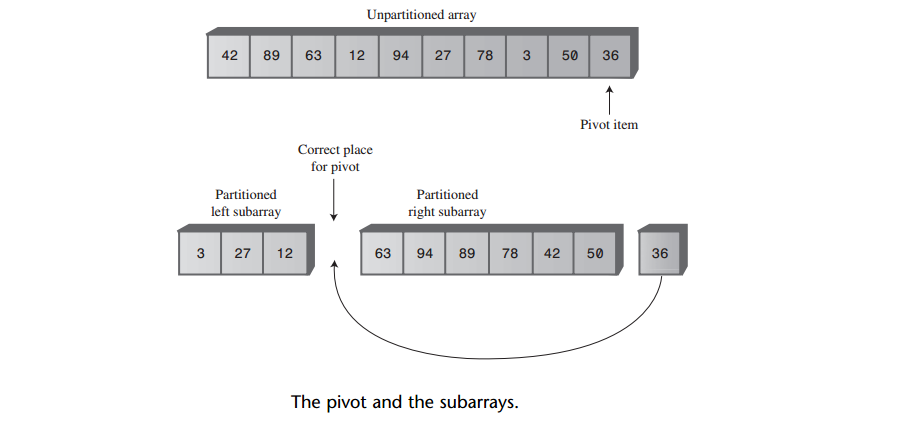
可以把右边子数组的所有数据项都像右移动一位,以腾出枢纽的位置。但是,这样做即低效又不必要。记住尽管右边子数组的所有数据项都大于枢纽,但它们都还没有排序,所以它们可以在右边子数组内部移动,而没有任何影响。因此,为了简化把枢纽插入正确位置的操作,只要交换枢纽和右边子数组的最左边的数据项(目前是63)即可。
这个交换操作把枢纽放在了正确的位置上,也就是左右子数组之间。63跳到了最右边,如下图所示: 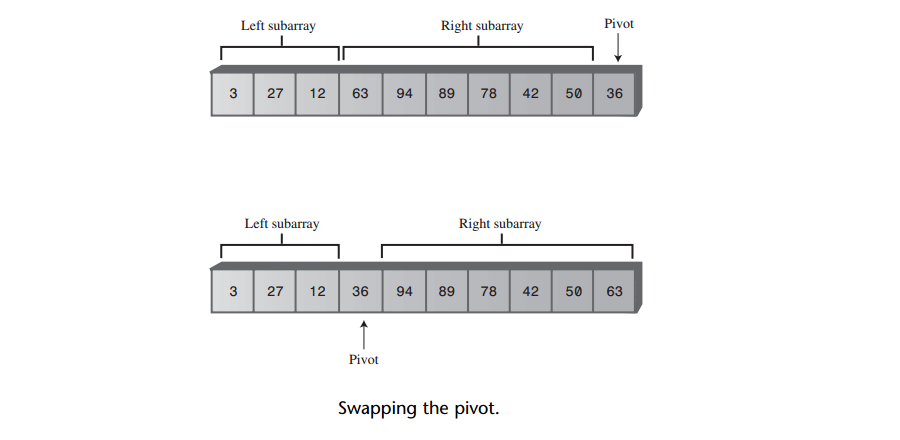
当枢纽被换到分界的位置时,它落在它最后应该在的位置上。以后所有的操作或者发生在左边或者右边,枢纽本身不会再移动了。
示例: QuickSort.java
Q: 为什么性能会降到O(n2)?
A: 如果数据是逆序的,然后采用上面的程序进行排序,就会发现算法运行得相当缓慢。
A: 问题出在枢纽的选择上,理想状态下,应该选择被排序的数据项的中值数据项作为枢纽。也就是说,应该由一半的数据项大于枢纽,一半的数据项小于枢纽。对快速排序算法来说拥有两个大小相等的子数组是最优的情况。如果快速排序算法必须要对划分的一大一小两个子数组排序,那么将会降低算法的效率,这是因为较大的子数组必须要被划分更多次。
A: N个数据项数组的最坏的划分是一个子数组只有一个数据项,另一个子数组含有N-1个数据项。
A: 在这种情况下,划分所带来的好处就没有了,算法的执行效率降低到O(N2)。除了慢,还有另外一个潜在的问题,当划分的次数增加时,递归方法的调用次数也增加,每一个方法调用都要增加所需递归工作栈的大小。如果调用次数太多,递归工作栈可能会发生溢出,从而使系统瘫痪。那么能否改进选择枢纽的方法呢?
Q: 什么是"三数据项取中" 划分?
A: 方法应该简单但能避免出现选择最大或者最小数据项作为枢纽的情况。可以检测所有的数据项,并且实际计算哪一个数据项是中值数据项,这应该是理想的枢纽,可是由于这个过程需要比排序本身更长的时间,因此它不可行。
A: 折衷的解决方案是找到数组的第一个、最后和中间元素的中间值,并将其用于枢纽。这个方案被称为“三数据项取中”,如下图: 
查找三个数据项的中值数据项自然比查找所有数据项的中值数据项快得多,同时这也有效地避免了在数据已经有序或者逆序的情况下,选择最大的或者最小的数据项作为枢纽的机会。
A: 当然很可能存在一些很特殊的数据排列使得三数据项取中的执行效率很低,但是通常情况下,对于选择枢纽它都是一个又快又有效的好方法。
A: 因为在选择的过程中使用三数据项取中的方法不仅选择了枢纽,而且还对三个数据项进行了排序。这时就可以保证子数组最左端的数据项小于枢纽,最右端的数据项大于枢纽,这就意味着即便取消了leftPointer > right和rightPointer < left的检测,leftPointer和rightPointer也不会分别越过数组。如下图:
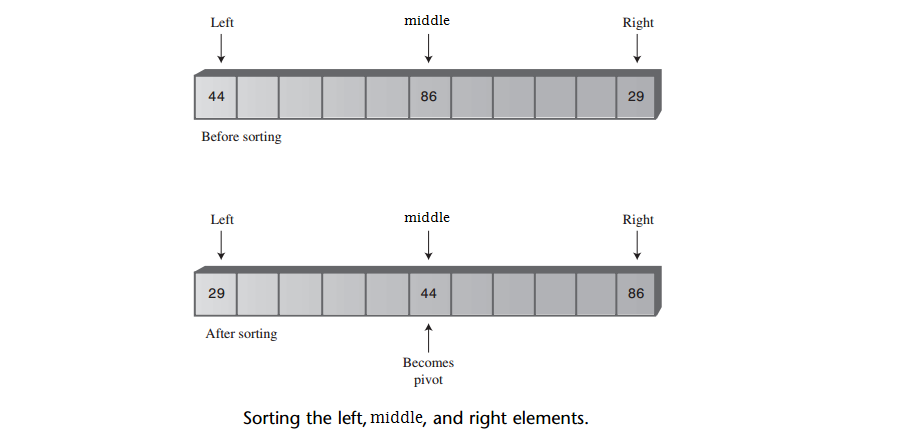
A: 三数据项取中的另一个好处是,对左端、中间以及右端的数据项排序之后,划分过程就不需要再考虑这三个数据项了。划分可以从left + 1和right - 1开始,因为left和right已经被有效地划分了。
A: 示例:QuickSort.java
Q: 对小划分使用插入排序?
A: 如果使用三数据项取中划分的方法,则必须要遵循快速排序不能执行三个或者少于三个数据项的划分规则,在这种情况下,数字3则被称为切割点(cutoff)。在上面的示例中,是用一段代码手动地对两个或者三个数据项的子数组进行排序。那么这个是最好的方法吗?
A: 处理小划分的另一个选择是使用插入排序。当使用插入排序的时候,不用限制以3为切割点。可以把界限定为10、20或者其他任何数。Knuth推荐使用9作为切割点。但是最好的选择值取决于计算机、操作系统、编译器(或者解释器)等。
A: 示例:QuickSort.java
Q: 快速排序之后使用插入排序?
A: 另一个选择是对数组整个使用快速排序。当快排结束时,数组已经是基本有序了,然后可以对整个数组应用插入排序。插入排序对基本有序的数组执行效率很高,而且很多专家都提倡使用这个方法。
A: 示例:QuickSort.java
Q: 消除递归?
A: 很多人提倡对快速排序的算法采用循坏代替递归来执行子数组的划分,这个思想源于早起的编译器以及计算机体系结构,对于每一次方法调用那种旧的系统都会导致大量的时间消耗。对于现在的系统来说,消除递归所带来的改进不是很明显,因为现在的系统可以更为有效地处理方法调用。
Q: 快速排序的效率?
A: 快速排序的时间复杂度为O(N*logN)。对于分治算法总体都是这样的,递归的方法把一列数据项分为2组,然后调用自身来分别处理每一组数据项。这种情况下,算法实际以2为底,运行时间和N*log2N成正比。
基数排序
Q: 什么是基数排序?
A: 基数排序(Radix Sort)也称为桶排序,是一种当关键字为整数类型时非常高效的排序方法。
Q: 基数排序的基本思想?
A: 设待排序的数据元素的关键字是m位d进制整数(不足m位的关键字在高位上补0),设置d个桶,令其编号为0,1,2,3,...,d-1。
A: 首先,按关键字最低位的数值依次把各数据元素放在对应的桶中。然后,按照桶号从小到大和进入桶中的先后次序收集分配在个桶中的数据元素,这样就形成了数据元素集合的一个新的排列。称这样的依次排序过程为一次基数排序。
A: 再对一次基数排序所得到的数据元素序列按关键字次低位的数值依次把各数据元素放到对应的桶中,然后按照桶号从小到大和进入桶中数据元素的先后次序收集分配在各桶中的数据元素。
A: 这样的过程重复进行,当完成了第m次基数排序后,就可以得到了排好序的数据元素的序列。
A: 下面是一个例子,有7个数据项{421, 240, 035, 532, 305, 430, 124},每个数据项都有三位。 
Q: 基数排序的实现?
A: 分析基数排序算法,因为要求进出桶中的数据元素序列满足FIFO原则,因此这里所说的桶实际就是队列。队列有顺序队列和链式队列,因此在实现中就有这两种方式。
A: 考虑到个位,十位,百位…每一位数值的个数不可能完全相同,因此很难确定队列的大小,因此采用链式队列最好,因为它可以任意扩展。请参阅:用链表实现的队列
A: 基于链式队列基数排序算法的存储结构示意图: 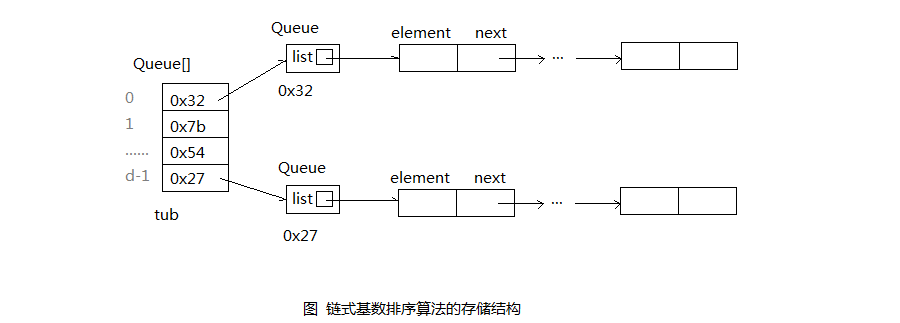
A: 一个十进制关键字K的第i位数值Ki的计算公式: 
其中,int()函数为取整函数,如int(3.5) = 3。
设k = 6321, K1, K2, K3, K4的计算结果如下:
K1 = int(6321 / 100) - 10 * (int(6321 / 101)) = 6321 - 6320 = 1;
K2 = int(6321 / 101) - 10 * (int(6321 / 102)) = 632 - 630 = 2;
K3 = int(6321 / 102) - 10 * (int(6321 / 103)) = 63 - 60 = 3;
K4 = int(6321 / 103) - 10 * (int(6321 / 104)) = 6 - 0 = 6;
A: 示例:RadixSort.java
Q: 基数排序的效率?
A: 所有要做的只是把原始的数据项从数组拷贝到链表,然后再拷贝回来。如果有10个数据项,则有20次拷贝。拷贝的次数和数据项的个数成正比,即O(N)。
A: 对每一位重复一次这个过程,假设对5位的数字排序,就需要20*5次拷贝。位数我们设为M。因此基于链式队列的基数排序算法的时间复杂度为O(MN)。
A: 尽管从数字中提取出每一位需要花费时间,但是没有比较。现代计算机中位提取操作要快于比较操作。
小结
- 希尔排序将增量应用到插入排序,然后逐渐缩小增量
- 增量为n的排序表示每隔n个元素进行排序
- 常用的间隔序列是由递归表达式h=3*h+1生成的,h的初始值为1
- 一个容纳了1000个数据项的数组,对它进行希尔排序可以是间隔序列为364, 121, 40, 13, 4,最后是1的增量排序
- 希尔排序算法的时间复杂度大概为O(N*(logN)2),这比时间复杂度为O(N2)的排序算法要快,比如插入排序,但是比时间复杂度为O(N*logN)的算法慢,比如快速排序。
- 划分数组就是把数组分为两个子数组,在一组中所有的数据项关键字的值小于指定的值,而在另一组中所有数据项关键字的值则大于或等于给定值
- 枢纽是在划分的过程中确定数据项应该放在哪一组的值。小于枢纽的数据项都放在左边一组,而大于枢纽的数据项都放在右边一组
- 在划分算法中,各自的while循环中的两个数组下标的指针,分别从数组的两端开始,相向移动,查找需要交换的数据项
- 当一个数组下标指针找到一个需要交换的数据项时,它的while循环终止
- 当两个while循环都终止时,交换这两个数据
- 当两个while循环都终止时,并且两个子数组的下标指针相遇或者交错,则划分过程结束
- 划分操作有线性的时间复杂度O(N),做N+1或N+2次的比较以及少于N/2次的交换
- 划分算法的内部while循环需要额外的检测,以防止数组下标越界
- 快速排序划分一个数组,然后递归调用自身,对划分得到的两个子数组进行快速排序
- 只含有一个数据项的子数组定为已经有序,这一点可以作为快速排序算法的基值(终止)条件
- 快速排序算法划分时的枢纽是一个特定数据项关键字的值,这个数据项称为pivot(枢纽)
- 在快速排序的简单版本中,总是由子数组的最右端的数据项作为枢纽
- 划分的过程中枢纽总是放在被划分子数组的右界,它不包含在划分的过程中
- 划分之后枢纽也换位,被放在两个划分子数组之间,这就是枢纽的最终排序位置
- 快速排序的简单版本,对已经有序(或者逆序)的数据项排序的执行效率只有O(N2)
- 更高级的快速排序版本中,枢纽是子数组中第一个、最后一个一级中间一个数据项的中值。这称为“三数据项取中”(median-of-tree)划分
- 三数据项取中划分有效地解决了对已有序数据项排序时执行效率仅是O(N2)的问题
- 在三数据项取中划分中,在对左端、中间以及右端的数据项取中值的同时对它们进行排序
- 这个排序算法消除了划分算法内部while循环中对数据越界的检测
- 快速排序算法的时间复杂度为O(N*log2N)(除了用简单的快速排序版本对已有序数据项排序的情况)
- 子数组小于一定的容量(切割界限,cutoff)时用另一种方法来排序,而不用快速排序
- 通常用插入排序对小于切割界限的子数组排序
- 在快速排序已经对大于切割界限的子数组排完序之后,插入排序也可用于整个的数组
- 基数排序的时间复杂度和快速排序相同,只是它需要两倍的存储空间
参考
- 《Java数据结构和算法》Robert Lafore 著,第7章 - 高级排序