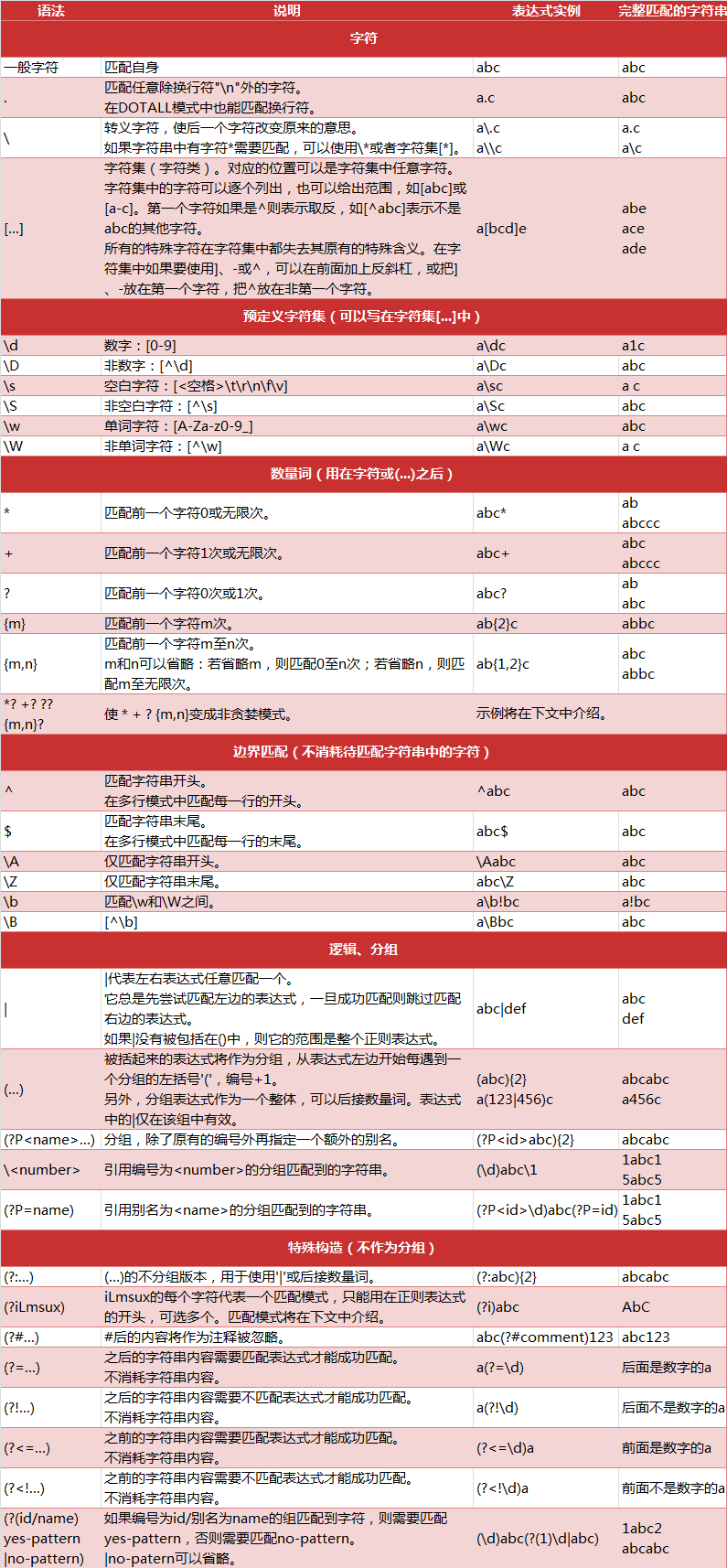
1.d 代表任意一个数字 D代表任意字母 s 表示所有长得像空格的东西,包括换行
2.w 代表数字,字母和下划线
3. *匹配前一个字符0或者无限次 (贪婪字符,但凡有就要一直去下去,?是有节制的) .匹配除换行符以外的所有字符 g全局匹配
4. [] 自定义正则化,每个字母代表一个值 [^ ] 取反
5. {n} 前面匹配符重复出现n次
6. +:至少匹配一次(有多少个取多少个,至少取一个) ?:0-1次 *:0-max
7.完整匹配而不是子集,^[]表示开始匹配 $持续匹配到结束
eg: str='18312345678'; r=str.match(/1^[3589]d{9}$/)
8.匹配特殊字符,匹配时候需要加转意符
eg: str='153^.' ; r=str.match(/^./)
9.条件分支 | ;()括号中的内容成为一个独立的内容,括号里的内容可以单独分组,单独匹配(如果不需要可以在括号前面加上?:,如果设置了^ &括号的分组功能会消失
eg: str='123.png' ; r=str.match(/.+.(?:png|gif|jp?g)$/)
m=re.match(r'(w+) (w+)(?P<sign>.*)', 'hello world')
#分组功能(...)*1 其中1表示的就是前面括号中的字母或数字,例如barbar, allohall都满足这个正则
10.数值的匹配 把合法的数值写出并分析规律, 根据规律编写正则,并测试非法数值
str='-12.34E23';
r=str.match(/^(-?)(0|[1-9]d*)(.d+)?([eE][-+]?d+)?$/)
11.中文的处理 默认中文采用的是双字节,在计算机中通过ASCII对应表来输入汉字,通过[]来设置中文的范围 escape()可以将字符串
eg: str='hello 中国' r=str.match(/[u4E00- 9FA5]/g)
12. 贪婪与懒惰: 在正则中默认是贪婪模型(尽可能多的匹配),可以在修饰数量的匹配符后面加上?则代表懒惰
eg: str='aabab' r=str.match(/a.* ? b/)
正则里面(?: )代表它是个大括号,[ ]代码的是里面任何一个,比如下面那个emoticons_str里面,第一个[ ]里面就是可能是: = ,第二个里面可能是- o,后面有个问号代表可以出现或不出现,第三个里面可能是P p D等,其实就是整个是描述表情符:-p :p :D这些。
