一、基本信息
(1)编译环境:python3.7.1、pycharm2018
(2)结对同学:1613072030 张鑫、1613072031 殷玉洁
(3)本次作业地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
(4)项目Git地址:https://gitee.com/ntucs/PairProg/tree/SE030_031
二、项目分析
1.1程序运行模块介绍
(1)Task1.读文件到缓冲区(process_file(dst))
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 file1 = open(dst, "r") except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = file1.read() except: print("Read File Error!") return None file1.close() return bvffer
(2)Task1.统计有效行数、用正则表达式筛选合格单词并统计(process_buffer(bvffer))
def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq count = 0 for i in bvffer: # 统计文件内容中换行符的数目 if i == ' ': count += 1 if i[-1] != ' ': # 当文件最后一个字符不为换行符时,行数+1 count += 1 for i in '!"#$%&()*+-,-./:;<=>?@“”[\]^_{|}~': bvffer = bvffer.replace(i, " ") # 替换特殊字符 words = bvffer.lower().split() if words: Newwords = [] words_select = '[a-z]{4}(w)*' # 用正则表达式筛选合格单词 for i in range(len(words)): word = re.match(words_select, words[i]) if word: Newwords.append(word.group()) remain_words = [] last_words = [] for word in Newwords: if word not in stop_words: remain_words.append(word)
(3)Task1.输出出现频率排在前十的单词(output_result(word_freq))
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("<%s>:%d " % (item[0], item[1])) f = open("result.txt", 'a') print("<%s>:%d " % (item[0], item[1]), file=f) f.close()
(4)Task1.main()函数
def main(): parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
(5)Task1.主函数进行调用
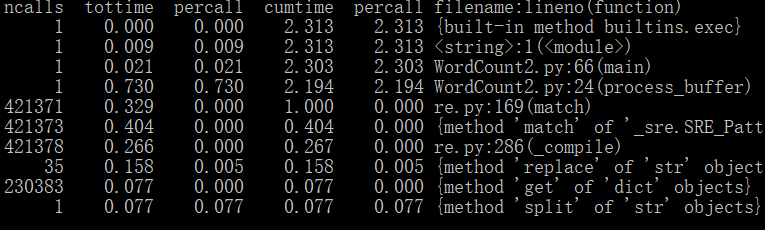
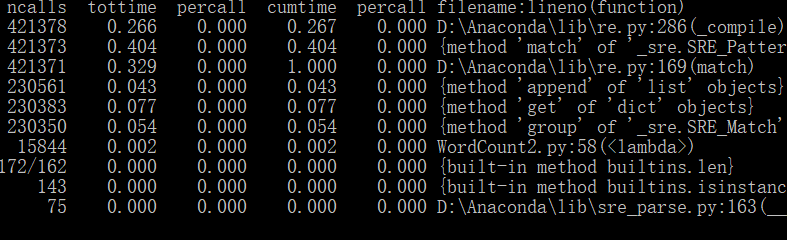
if __name__ == "__main__": cProfile.run("main()", "results") # 直接把分析结果打印到控制台 p = pstats.Stats("results") # 创建Stats对象 p.sort_stats('calls').print_stats(10) # 按照调用次数排序,打印前10函数的信息 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 按执行时间次数排序 p.print_callers(0.5, "process_file") # 想知道有哪些函数调用了process_file,小数,表示前百分之几的函数信息 p.print_callers(0.5, "process_buffer") # 想知道有哪些函数调用了process_buffer p.print_callers(0.5, "output_result") # 想知道有哪些函数调用了output_result
(6)Task2.读取停词表
stop = open("stopwords.txt", 'r') # 停词表的读取 stopfile = stop.read() stop_words = stopfile.replace(' ', " ").lower().split()
(7)Task2.查看常用短语
print("请输入统计的内容:1.单个单词 " " 2.2个单词组成的词组 " " 3.3个单词组成的词组 ") choice = int(input()) if choice != 1 and choice != 2 and choice != 3: print("输入错误,请再输一遍:") choice = int(input()) if choice == 1: last_words = remain_words elif choice == 2: for i in range(len(remain_words) - 1): phrase = "%s %s" % (remain_words[i - 1], remain_words[i]) last_words.append(phrase) elif choice == 3: for i in range(len(remain_words) - 1): phrase = "%s %s %s" % (remain_words[i - 2], remain_words[i - 1], remain_words[i]) last_words.append(phrase) for word in last_words: word_freq[word] = word_freq.get(word, 0) + 1 print("lines:%d " % count) print("words:%d " % len(Newwords)) f = open("result.txt", 'w') print("lines:%d " % count, file=f) print("words:%d " % len(Newwords), file=f) f.close() return word_freq
1.2程序算法的时间、空间复杂度分析
(1)时间复杂度分析:O(N+n)
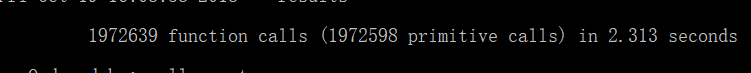
(2)空间复杂度分析:即word_freq = {}的长度,则空间复杂度为O(2n)
1.3程序运行案例截图
(1)未使用停词表的有效行数、合格单词数

(2)使用停词表前的耗时最多、运行次数最多的函数
(3)停词表展示

(4)使用停词表后统计有效行数、合格单词数、常用短语
①一个单词组成的词组

②两个单词组成的词组
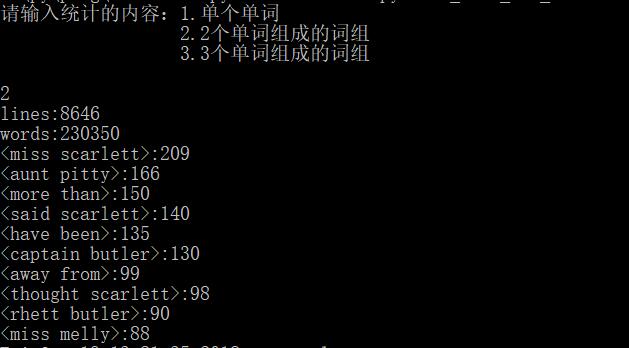
③三个单词组成的词组

三、性能分析
(1)性能提高时间
关于性能的提高方面,我们在查找性能不足、寻求和讨论改进方法、实现性能提高、程序性能优化测试等过程中经历了两天时间,每天平均耗时大约在两到三个小时。
(2)性能图表展示

四、其他
(1)结对编程时间开销(单位:小时)
从准备工作和分工开始到博客撰写完成大约经历了六天时间。我们每天在课余时间划分出两到三个小时进行资料的查询、知识点的学习和讨论。后期博客方面则快些,用了两天的课余时间完成。
(2)结对编程照片

五、事后分析与总结
(1)讨论决策过程
我们在做词组统计时针对是选择“正则表达式”还是“将单词进行两两结合” 的方式进行了讨论,并选择使用两两结合的方式完成任务。接着,我们还对停词表的单词进行了讨论。
(2)评价合作伙伴
殷玉洁评价张鑫:张鑫是一位非常认真的同学。他从分配任务时就照顾到了我对Python不熟悉的短板;能够积极学习、修改和讨论目标程序的实现方法,查询陌生的知识点;接着热心帮助我扫除知识盲区,共同完成学习任务。目前来说,没有什么缺点。
张鑫评价殷玉洁:殷玉洁同学虽然对Python代码的掌握不很熟悉,但是学习态度是端正的。在完成任务的过程中,她也能够自主利用线上资源查询相关知识进行学习。如果平时能够走出书本,拓宽一下知识面会更好。
(3)评价整个过程:关于结对过程的建议
我们平时没有频繁的接触,私下里并不互相了解,但是这次结对过程增强了同学间的互动,也给彼此留下了深刻的记忆。
首先,本次结对使我们充分利用到了双方的优势进行互补。张鑫同学对Python语言较为熟悉,学习理解能力较强,主动负责较为困难的代码以及程序的测试部分任务。殷玉洁同学则紧跟其后进行学习和讨教,在能力范围内做出一些贡献,学习和理解后完成博客部分的撰写和排版。
其次,由于班级和性别的不同,两人平时没有什么接触。通过此次结对学习,我们认识彼此并且通力合作,完成了看似不易的工作。在互相讨论的过程中,我们能够做到互相理解、互相尊重,只为找到最合适的解决方法,在不断了解对方后建立了深厚的情谊。
最后,结对完成任务即是一个团队的任务。我们认为无论成员数量如何,每个成员都要把自己当做一份子;无论能力如何,做事态度最重要;无论面对的工作是容易还是困难,都需要每位成员积极探索、努力实践、端正态度。至此,我们很期待接下来与更多同学的结对合作环节,希望能一如既往地愉快合作。
(4)其他
希望这样利于学习、开拓视野的活动能够不以作业的形式开展。