一、编译环境说明
(1)python3.7.1
(2)pycharm2018
二、程序分析,对程序中的四个函数做简要说明
(1)读文件到缓冲区(process_file(dst))
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 file = open(dst, 'r') # dst为文本的目录路径 except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = file.read() except: print("Read File Error!") return None file.close() return bvffer
(2)处理缓冲区,返回存放每个单词频率的字典word_freq(process_buffer(bvffer))
def process_buffer(bvffer): # 处理缓冲区,返回存放每个单词频率的字典word_freq if bvffer: # 下面添加处理缓冲区bvffer代码,统计每个单词的频率,存放在字典word_freq word_freq = {} # 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ") # strip()删除空白符(包括'/n', '/r','/t');split()以空格分割字符串 words = bvffer.strip().split() for word in words: word_freq[word] = word_freq.get(word, 0) + 1 return word_freq
(3)输出出现频率排在前十的单词(output_result(word_freq))
def output_result(word_freq): # 出现频率排在前十的单词 if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("单词:%s 频数:%d " % (item[0], item[1]))
(4)main()函数
def main(): dst = "txt/Gone_with_the_wind.txt" # 《Gone_with_the_wind》的路径,另一组测试更改为《A_Tale_of_Two_Cities》的路径 bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
(5)主函数进行调用
if __name__ == "__main__": main()
三、代码风格说明
Python 代码强调即使是一个打算被用作脚本的文件,也应该是可导入的。并且简单的导入不应该导致这个脚本的主功能(main functionality)被执行,这是一种副作用.。主功能应该放在一个main()函数中。
在Python中,pydoc以及单元测试要求模块必须是可导入的。你的代码应该在执行主程序前总是检查if_name_=='_main_',这样当模块被导入时主程序就不会被执行。
例如程序中第48行代码:
def main(): dst = "txt/Gone_with_the_wind.txt" # 《Gone_with_the_wind》的路径,另一组测试更改为《A_Tale_of_Two_Cities》的路径 bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq) if __name__ == "__main__": main()
四、程序运行命令、运行结果截图
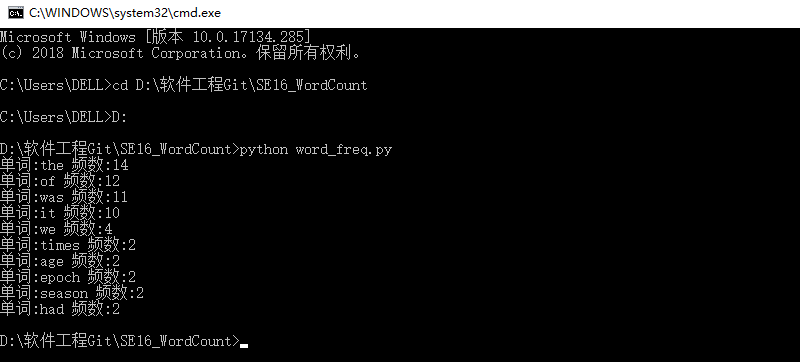
(1)对文件《A_Tale_of_Two_Cities》进行词频统计
①在pycharm2018中运行的结果截图

②在DOS命令行中运行的命令、结果截图
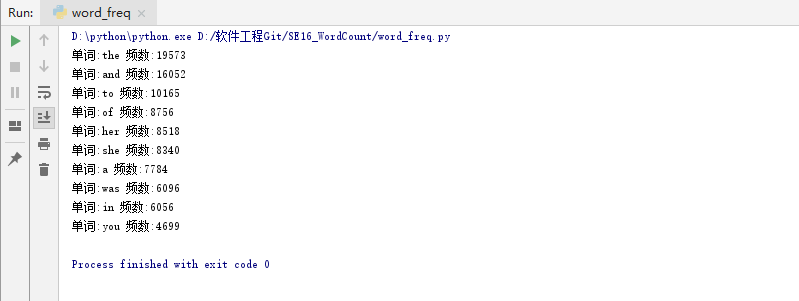
(2)对文件《Gone_with_the_wind》进行词频统计
①在pycharm2018中运行的结果截图
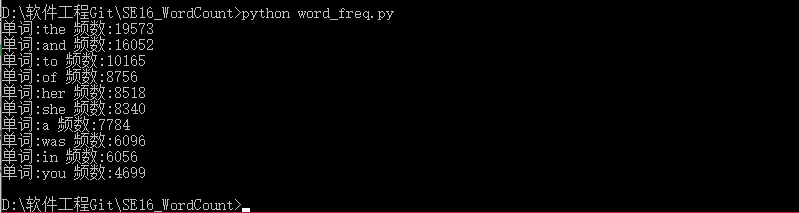
②在DOS命令行中运行的命令、结果截图
五、性能分析结果及改进
(1)代码
if __name__ == "__main__": import cProfile import pstats cProfile.run("main()", filename="result.out") # 创建Stats对象 p = pstats.Stats('result.out') # 输出调用此处排前十的函数 # sort_stats(): 排序 # print_stats(): 打印分析结果,指定打印前几行 p.sort_stats('calls').print_stats(10) # 输出按照运行时间排名前十的函数 # strip_dirs(): 去掉无关的路径信息 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 根据上面的运行结果发现函数process_buffer()最耗时间 # 查看process_buffer()函数中调用了哪些函数 p.print_callees("process_buffer")
备注:ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
①指出寻找执行时间最多的部分代码:

该部分代码为:
# 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ")
②指出寻找执行次数最多的部分代码:

该部分代码为:
for word in words: word_freq[word] = word_freq.get(word, 0) + 1
(2)使用可视化工具分析
①可视化工具:选用graphviz、gprof2dot
②对保存分析结果的result.out文件进行可视化
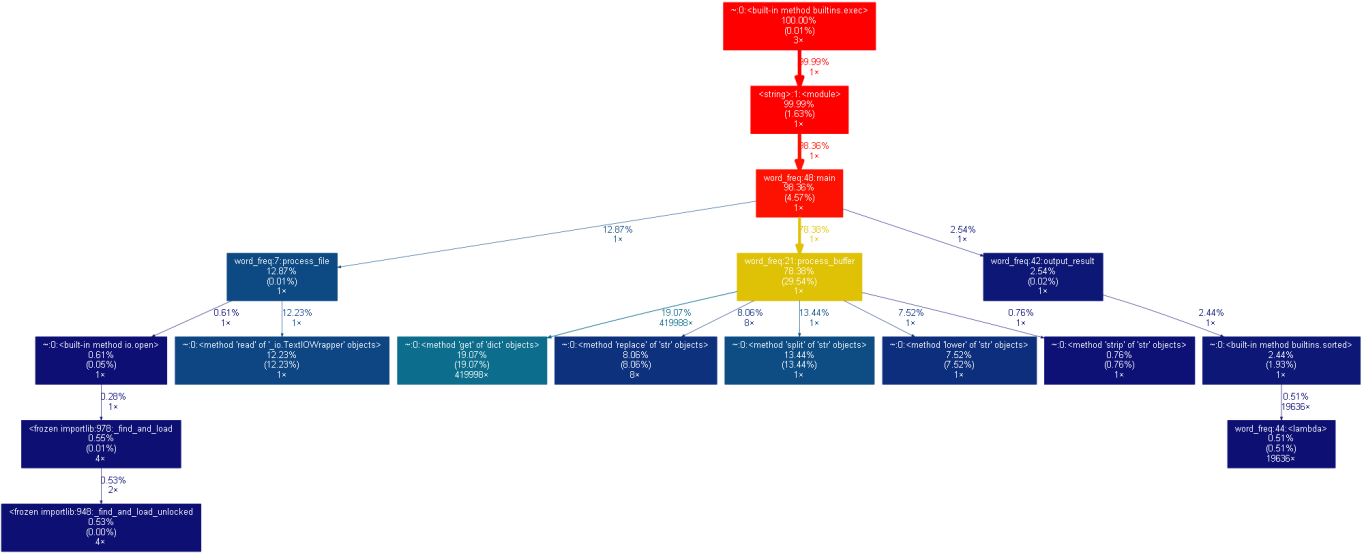
(3)代码改进尝试
①代码修改:对执行时间最久的部分代码做出修改
原代码:
# 将文本内容都改为小写且去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.lower().replace(ch, " ")
修改后:
#代码性能改进 # 将文本内容都改为小写 bvffer = bvffer.lower() # 去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.replace(ch, " ")
②修改前该部分代码耗时情况:
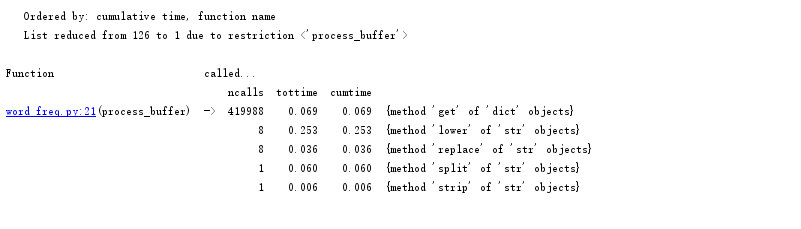
修改后该部分代码耗时情况:
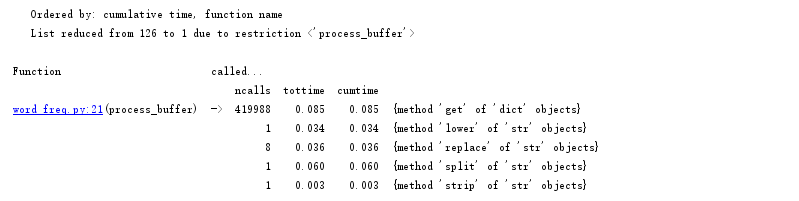
经对比发现运行时间由0.253降低为0.034。