引言
前面我们讲过曲线拟合问题。曲线拟合问题的特点是,根据得到的若干有关变量的 一组数据,寻找因变量与(一个或几个)自变量之间的一个函数,使这个函数对那组数据拟合得最好。通常,函数的形式可以由经验、先验知识或对数据的直观观察决定,要作的工作是由数据用最小二乘法计算函数中的待定系数。从计算的角度看,问题似乎已经完全解决了,还有进一步研究的必要吗?
从数理统计的观点看,这里涉及的都是随机变量,我们根据一个样本计算出的那些系数,只是它们的一个(点)估计,应该对它们作区间估计或假设检验,如果置信区间太大,甚至包含了零点,那么系数的估计值是没有多大意义的。另外也可以用方差分析方法对模型的误差进行分析,对拟合的优劣给出评价。简单地说,回归分析就是对拟合问题作的统计分析。

模型种类
以下为常用的回归模型。
除了这 7 种最常用的回归技术之外,你还可以看看其它模型,如 Bayesian、Ecological 和 Robust 回归。
Linear Regression线性回归
TIPS:
我们假设线性回归的噪声服从均值为0的正态分布。 当噪声符合正态分布N(0,delta^2)时,因变量则符合正态分布N(ax(i)+b,delta^2),其中预测函数y=ax(i)+b。这个结论可以由正态分布的概率密度函数得到。也就是说当噪声符合正态分布时,其因变量必然也符合正态分布。
在用线性回归模型拟合数据之前,首先要求数据应符合或近似符合正态分布,否则得到的拟合函数不正确。
一元线性回归

利用最小二乘估计得到最佳拟合直线:
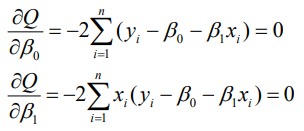
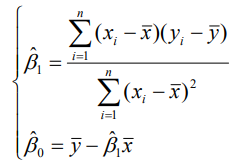
多元线性回归


回归模型的假设检验:


回归系数的假设检验和区间估计:

Stepwise Regression逐步回归
当我们处理多个独立变量时,就使用逐步回归。在这种技术中,独立变量的选择是借助于自动过程来完成的,不涉及人工干预。
逐步回归的做法是观察统计值,例如 R-square、t-stats、AIC 指标来辨别重要的变量。基于特定标准,通过增加/删除协变量来逐步拟合回归模型。常见的逐步回归方法如下所示:
- 标准的逐步回归做两件事,每一步中增加或移除自变量。
- 前向选择从模型中最重要的自变量开始,然后每一步中增加变量。
- 反向消除从模型所有的自变量开始,然后每一步中移除最小显著变量。
这种建模技术的目的是通过使用最少的自变量在得到最大的预测能力。它也是处理高维数据集的方法之一。
这个实际上就是我们后面将提到的多元回归变量筛选方法的应用。
Ridge Regression岭回归
岭回归是当数据遭受多重共线性(独立变量高度相关)时使用的一种技术。
在多重共线性中,即使最小二乘估计(OLS)是无偏差的,但是方差很大,使得观察值远离真实值。岭回归通过给回归估计中增加额外的偏差度,能够有效减少方差。
在线性方程中,预测误差可以分解为两个子分量。首先是由于偏颇,其次是由于方差。预测误差可能由于这两个或两个分量中的任何一个而发生。这里,我们将讨论由于方差引起的误差。
岭回归通过收缩参数 λ(lambda)解决了多重共线性问题。
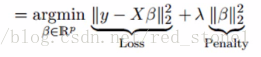
上面这个公式中包含两项。第一个是最小平方项,第二个是系数 β 的平方和项,前面乘以收缩参数 λ。增加第二项的目的是为了缩小系数 β 的幅值以减小方差。
本质上是L2正则化。
Lasso Regression套索回归
类似于岭回归,套索(Least Absolute Shrinkage and Selection Operator)回归惩罚的是回归系数的绝对值。此外,它能够减少变异性和提高线性回归模型的准确性。

套索回归不同于岭回归,惩罚函数它使用的是系数的绝对值之和,而不是平方。这导致惩罚项(或等价于约束估计的绝对值之和),使得一些回归系数估计恰好为零。施加的惩罚越大,估计就越接近零。实现从 n 个变量中进行选择。
本质是L1正则化。
ElasticNet弹性回归
弹性回归是岭回归和套索回归的混合技术,它同时使用L2 和 L1 正则化。当有多个相关的特征时,弹性网络是有用的。套索回归很可能随机选择其中一个,而弹性回归很可能都会选择。
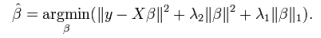
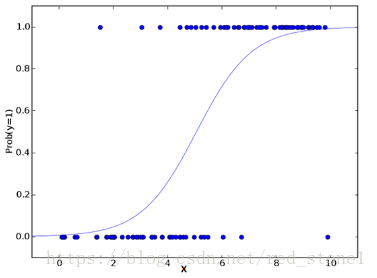
Logistic Regression逻辑斯蒂回归
把Y的结果带入一个非线性变换的Sigmoid函数中,即可得到[0,1]之间取值范围的数S,S可以把它看成是一个概率值,如果我们设置概率阈值为0.5,那么S大于0.5可以看成是正样本,小于0.5看成是负样本,就可以进行分类了。
逻辑回归用来计算事件成功(Success)或者失败(Failure)的概率,广泛用于分类问题。当因变量是二进制(0/1,True/False,Yes/No)时,应该使用逻辑回归。这里,Y 的取值范围为 [0,1],它可以由下列等式来表示。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
在上面的等式中,通过使用最大似然估计来得到最佳的参数,而不是使用线性回归最小化平方误差的方法。
损失函数:对数似然函数
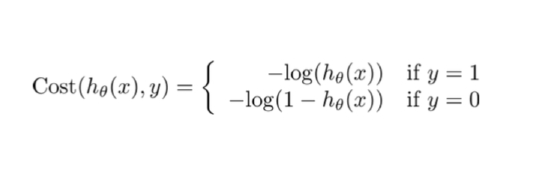
Polynomial Regression多项式回归
如果自变量的指数大于 1,则它就是多项式回归方程。
注意:不要次数过高造成过拟合(类似于Ronge现象),应观察图像。
偏相关系数
在研究两个变量之间的线性相关程度时,可考察这两个变量的简单相关系数。但
在研究多个变量之间的线性相关程度时,单纯使用两两变量的简单相关系数常具有虚假
性。因为简单相关系数只考虑了两个变量之间的相互作用,而没有考虑其它变量对这两
个变量的影响。为了更准确、真实地反映变量之间的相关关系,统计学中定义了偏相关
系数(又称净相关系数)。

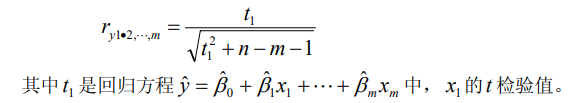
偏相关系数的检验:


多元回归变量筛选方法
用回归建模首先遇到的难题,就是选择哪些变量作为因变量的解释变量。在我们选择自变量时,一方面希望尽可能不遗漏重要的解释变量;另一方面,又要遵循参数节省原则,使自变量的个数尽可能少。
下面我们介绍一些有效的变量筛选方法,向前选择变量法、向后删除变量法和逐步回归法。
偏 F 检验是变量筛选的统计依据。


向前选择变量法
- 对所有的这 m 个模型进行 F 检验,选择 F 值最高者作为第 一个进入模型的自变量(记为xi1)。
- 对剩下的 m−1个变量分别进行偏 F 检验(即以 y 与xi1的模型为减模型, 以 y 与xi1 以及另一个自变量xj的模型为全模型)。
- 如果至少有一个 x1 通过了偏 F 检 验,则在所有通过偏 F 检验的变量中,选择 Fj 值最大者作为第二个被选的自变量,进入模型(记为 xi2 )。
- 继续上述步骤,直到在模型之外的自变量均不能通过偏 F 检验。
向后删除变量法

逐步回归法
逐步回归法采取边进边退的方法。对于模型外部的变量,只要它还可提供显
著的解释信息,就可以再次进入模型;而对于已在内部的变量,只要它的偏 F 检验不
能通过,则还可能从模型中被删除。
步骤:向前选择、向后删除、循环。

由于变量数变化,此处判定值通常采用校正决定系数。
模型评价
这里涉及到评价模型的内容,此处仅简略介绍。
残差的样本方差(MSE)
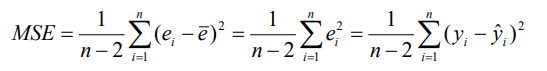
可以证明,MSE是σ^2的无偏估计量。
判定系数(R-square)


1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
经验值:>0.4, 拟合效果好。
数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差。也因此产生了校正决定系数:

n为样本数量,p为特征数量。该式消除了样本数量和特征数量的影响。
sklearn. metrics库函数
python的sklearn.metrics中包含一些损失函数,评分指标来评估回归模型的效果。
主要包含以下几个指标:
- explained_variance_score(解释方差分)(var:方差)
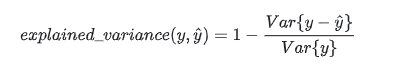
#explained_variance_score:解释方差分,这个指标用来衡量我们模型对数据集波动的解释程度,如果取值为1时,模型就完美,越小效果就越差。
explained_variance_score(y_true, y_pred, multioutput=[0.3, 0.7])
- mean_absolute_error(平均绝对误差)
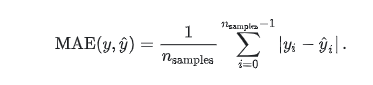
#给定数据点的平均绝对误差,一般来说取值越小,模型的拟合效果就越好。
mean_absolute_error(y_true, y_pred, multioutput=[0.3, 0.7])
- mean_squared_error(均方误差)
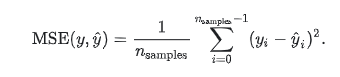
mean_squared_error(y_true, y_pred)
- mean_squared_log_error
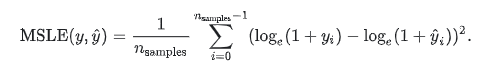
当目标实现指数增长时,例如人口数量、一种商品在几年时间内的平均销量等,这个指标最适合使用。请注意,这个指标惩罚的是一个被低估的估计大于被高估的估计。
mean_squared_log_error(y_true, y_pred)
- median_absolute_error(中位数绝对误差)
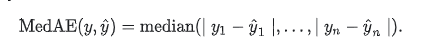
中位数绝对误差适用于包含异常值的数据的衡量.
median_absolute_error(y_true, y_pred)
- r2_score

方法:
sklearn.metrics.r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
#y_true:观测值
#y_pred:预测值
#sample_weight:样本权重,默认None
#multioutput:多维输入输出,可选‘raw_values’, ‘uniform_average’, ‘variance_weighted’或None。默认为’uniform_average’;
raw_values:分别返回各维度得分
uniform_average:各输出维度得分的平均
variance_weighted:对所有输出的分数进行平均,并根据每个输出的方差进行加权。
实例:
>>> from sklearn.metrics import r2_score
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> r2_score(y_true, y_pred)
0.948...
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> r2_score(y_true, y_pred, multioutput='variance_weighted')
...
0.938...
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> r2_score(y_true, y_pred, multioutput='uniform_average')
...
0.936...
>>> r2_score(y_true, y_pred, multioutput='raw_values')
...
array([ 0.965..., 0.908...])
>>> r2_score(y_true, y_pred, multioutput=[0.3, 0.7])
...
0.925...
显著性检验
一般地,回归方程的假设检验包括两个方面:一个是对模型的检验,即检验自变量与因变量之间的关系能否用一个线性模型来表示,这是由F 检验来完成的;另一个检验是关于回归参数的检验,即当模型检验通过后,还要具体检验每一个自变量对因变量的影响程度是否显著。这就是下面要讨论的t 检验。在一元线性分析中,由于自变量的个数只有一个,这两种检验是统一的,它们的效果完全是等价的。但是,在多元线性回归分析中,这两个检验的意义是不同的。从逻辑上说,一般常在 F 检验通过后,再进 一步进行t 检验。
回归模型的线性关系检验



- 需要注意的是,即使 F 检验通过了,也不说明该模型就是一个恰当的回归模型。
回归系数的显著性检验
回归参数的检验是考察每一个自变量对因变量的影响是否显著。换句话说,就是要 检验每一个总体参数是否显著不为零。
首先看对 β1 = 0的检验。 β1 代表 x 变化一个单位对 y 的影响程度。对 β1 的检验 就是要看这种影响程度与零是否有显著差异。
1)


2)


复共线性与有偏估计
有时某些回归系数的估计值的绝对值差异较大,有时回归系数的估计值 的符号与问题的实际意义相违背等。研究结果表明,产生这些问题的原因之一是回归自变量之间存在着近似线性关系,称为复共线性(Multicollinearity)。
参考资料
- 司守奎《数学建模算法与应用》
- XGBoost for house price prediction:https://www.kaggle.com/santibermejo/xgboost-for-house-price-prediction
- 【机器学习之路】十三种回归模型预测房价:https://blog.csdn.net/weixin_41779359/article/details/88782343
- 使用Python的scikit-learn库实现回归预测,实战对房价的评估预测:https://blog.csdn.net/wang7807564/article/details/80391278
- 你应该掌握的 7 种回归模型:https://blog.csdn.net/red_stone1/article/details/81122926
- 线性回归:https://blog.csdn.net/lilong_csdn/article/details/81937496
- 回归预测的评价指标:https://blog.csdn.net/weixin_39541558/article/details/80705006
- 深度研究:回归模型评价指标R2_score:https://www.cnblogs.com/jpld/p/12022123.html
- 逻辑斯蒂回归:https://github.com/NLP-LOVE/ML-NLP/blob/master/Machine%20Learning/2.Logistics%20Regression/2.Logistics%20Regression.md