操作系统:macOS Mojave
python版本:python3.7
依赖库:requests、etree
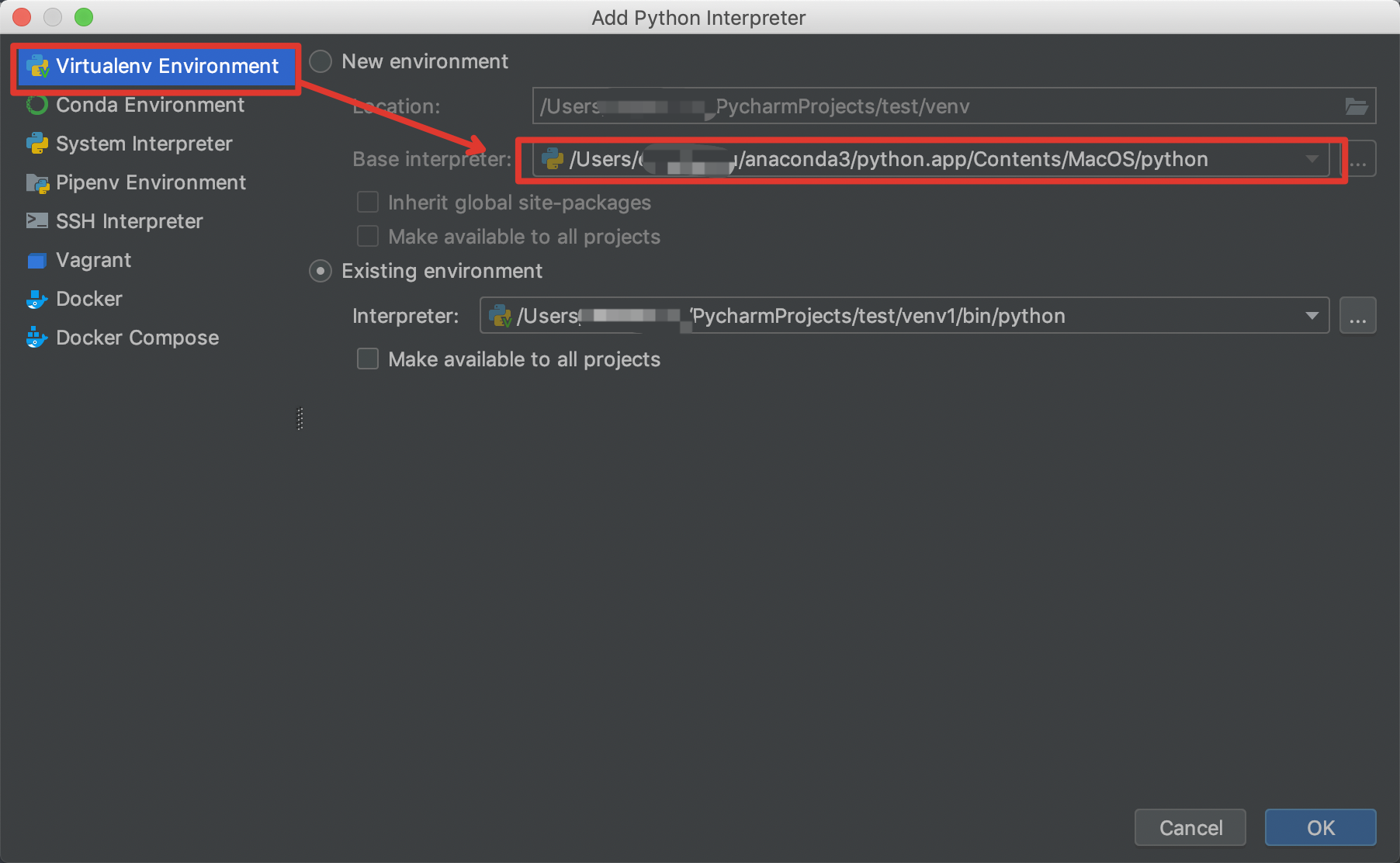
关于依赖库的安装,建议使用anaconda+pycharm的组合方式,每个依赖库的安装又会基于其他依赖包的安装,这时候anaconda的作用便是自动帮你下载安装对应的依赖,不需要人工去查找,类似于java maven的三方库管理,python常见IDE就是pycharm了。pycharm怎么关联anaconda的依赖包呢?请看下图设置:
0-0、打开pycharm-preferences,进入设置

0-1、选择anaconda所在的python执行文件
1、网站源代码获取及转换
import requests
from lxml import etree
r=requests.get("http://www.baidu.com")
#print ("状态码:",r.status_code)
#print ("网站源代码",r.text)
#print ("头部请求",r.headers)
html = etree.HTML(r.text) # 调用HTML类进行初始化
etreeResult = etree.tostring(html) # 将其转化为字符串类型,etree类型
strResult=etreeResult.decode('utf-8') #转化为utf-8编码格式,此时已是str类型
2、节点、属性值、内容的获取
语法如下:
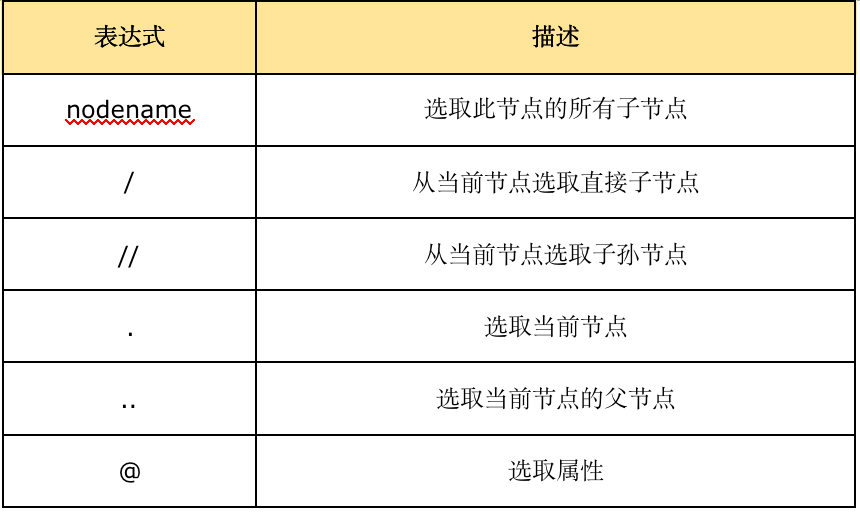
示例代码:
import requests
from lxml import etree
r=requests.get("http://www.baidu.com")
html = etree.HTML(r.text) # 调用HTML类进行初始化
resultAll = html.xpath('//*') #选取所有节点
#print("获取所有节点:",resultAll)
resultDivAll = html.xpath('//div') #选取div子孙节点
#print("获取div所有节点:",resultDivAll)
resultDiv_img = html.xpath('//div/img') #选取div下img节点
#print("获取div节点下img节点:",resultDiv_img)
resultDiv_imgSrc = html.xpath('//div/img/@src') #获取div_img的src属性值
print("获取div节点下img的src值:",resultDiv_imgSrc)
对应输出的值:
