一.简介
决策树的一个重要任务是理解数据中蕴含的知识信息。
决策树优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能产生过度匹配的问题。
适用数据类型:数值型和标称型。
二. 决策树的一般流程
1.收集数据:可以使用任何方法。
2.准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
3.分析数据:可以使用任何方法,构造树完成后,应该检查图形是否符合预期标准。
4.训练算法:构造树的结构
5.测试算法:使用经验树计算错误率。
6.使用算法:此步骤使用于任何监督学习算法,使用决策树可以更好的理解数据的内在含义。
三.决策树的表示法
决策树通过把实例从艮节点排列到某个叶子结点来分类实例,叶子结点即为实例所属的分类。树上的每一个结点指定了对实例的某个属性的测试,并且该结点的每一个后继分支对应于该属性的一个可能值。分类实例的方法是从这棵树的根节点开始,测试这个结点的属性,然后按照给定实例的属性值对应的树枝向下移动。然后这个过程在以新结点的根的子树上重复。

决策树对应表达式: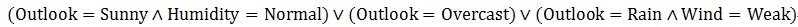
四.基本的决策树学习算法
1. ID3算法
通过自顶向下构造决策树来进行学习。构造过程是从“哪一个属性将在树的根结点被测试?”这个问题开始的。为了回答这个问题,使用统计测试来确定每一个实例属性单独分类训练样例的能力。分类能力最好的属性被选作树的根结点的测试。然后为根节点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支之下。然后重复整个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。这形成了对合格决策树的贪婪搜索(greedy search),也就是算法从不回溯重新考虑原来的选。
专门用于学习布尔函数的ID3算法概要
ID3(Examples,Target_attribute,Attributes)
Examples即训练样例集。Target_attribute是这棵树要测试的目标属性。Attributes是除目标属性外供学习到的决策树测试的属性列表。返回一棵能正确分类给定Examples的决策树。
•如果Examples都为正,那么返回label=+的单结点树Root
•如果Examples都为反,那么返回label=+的单结点树Root
•如果Attributes为空,那么返回单结点树Root,label=Examples中最普遍的Target_attribute的值
•否则开始
•A←Attributes中分类Examples能力最好的属性
•Root的决策属性←A
•对于A的每个可能值vi
•在Root下加一个新的分支对应测试A=vi
•令Examples vi为Examples中满足A属性值为vi的子集
•如果Examples vi为空
•在这个新分支下加一个叶子结点,结点的label=Examples中最普遍的Target_attribute值
•否则在这个新分支下加一个子树ID3(Examples vi,Target_attribute,Attributes-{A})
•结束
•返回Root
2. 哪个属性是最佳的分类属性
熵(entropy):刻画了任意样例集的纯度(purity)。
熵确定了要编码集合S中任意成员(即以均匀的概率随机抽出的一个成员)的分类所需要的最小二进制位数。
如果目标属性具有c个不同的值,那么S相对c个状态(c-wise)的分类的熵定义为:
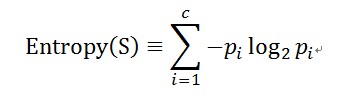
Pi是S中属于类别i的比例。
信息增益(information gain):一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低。
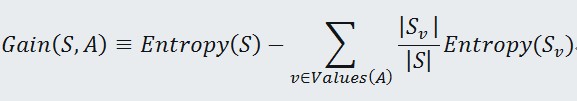
Values(A)是属性A所有可能值的集合,Sv 是S中属性A的值为v的子集。
例如,假定S包含14个样例-[9+,5-]。在这14个样例中,假定正例中的6个和反例中的2个有Wind=Weak,其他的有Wind=Strong。由于按照属性Wind分类14个样例得到的信息增益可以计算如下。
Values(Wind)=Weak,Strong
S=[9+,5-]
SWeak←[6+,2-]
Sstrong←[3+,3-]
=Entropy(S)-(8/14)Entropy(SWeak)-(6/14)Entropy(Sstrong)
=0.940-(8/14)0.811-(6/14)1.00
=0.048
3.举例

- 首先计算四个属性的信息增益:
Gain(S,Outlook)=0.246
Gain(S,Humidity)=0.151
Gain(S,Wind)=0.048
Gain(S,Temperature)=0.029
根据信息增益标准,属性Outlook在训练样例上提供了对目标属性PlayTennis的最佳预测。
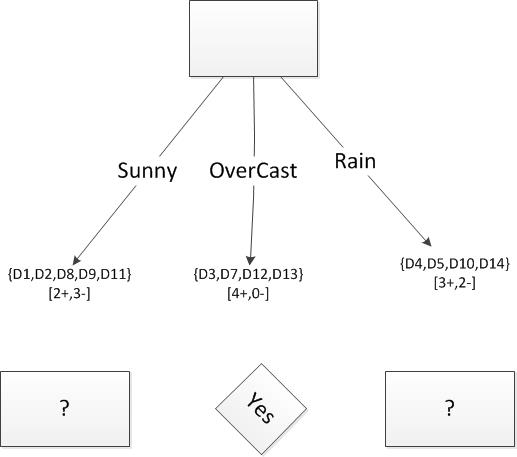
Ssunny ={D1,D2,D8,D9,D11}
Gain(Ssunny,Humidity)=0.970-(3/5)0.0-(2/5)0.0=.970
Gain(Ssunny, Temperature)=0.970-(2/5)1.0-(2/5)1.0-(1/5)0.0=.570
Gain(Ssunny ,Wind)=0.970-(2/5)1.0-(3/5).918=.019
五.决策树学习中的假设空间搜索
ID3算法中的假设空间包含所有的决策树,它是关于现有属性的有限离散值函数的一个完整空间。
当变了决策树空间时,ID3仅维护单一的当前假设。
基本的ID3算法在搜索中不进行回溯。
ID3算法在搜索的每一步都使用当前的所有训练样例,以统计为基础觉得怎样简化以前的假设。
关于C4.5决策树 可以参考 http://www.cnblogs.com/zhangchaoyang/articles/2842490.html
参考文献:http://www.cnblogs.com/lufangtao/archive/2013/05/30/3103588.html