在自动化测试中经常会遇到使用selenium方法定位元素点击操作失败的情况,例如,我们想实现在浏览器输入http://www.baidu.com,进入百度首页后,鼠标悬停在“更多产品”上,点击“全部产品”

若不使用js的话,代码应该如下图所示:

我们执行代码后,发现会报错

我们该如何解决这个问题呢,那就要用到这篇文章的主角js了,将代码修改为如下内容,执行代码,发现页面正常跳转了

我们在编写自动化测试用例的过程中,有时会遇到某个元素的长宽设置的比较大,将我们想要点击的元素遮挡住了,该怎么办?我们可以使用js的方法,先将遮挡我们的元素去掉,这里举个例子,我们利用js去掉百度的搜索按钮,执行以下代码

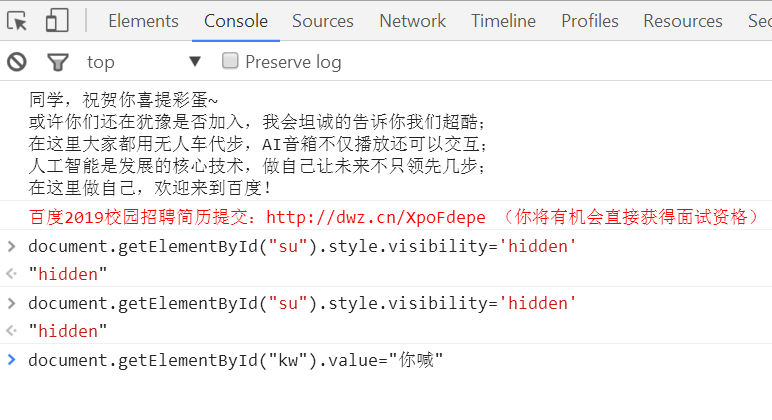
执行代码后,我们发现百度搜索按钮消失了

想看看js的效果的话,我们可以直接在浏览器按一下F12的按键,鼠标点击Console或者控制台


打开百度首页,按F12后,在控制台输入document.getElementById("kw").value="你喊",之后输入回车后,看一下效果吧
JS的使用方法:
一、查找元素:
1、根据元素的id查找元素:document.getElementById(元素id值)
2、根据元素的class属性查找元素:document.getElementsByClassName(元素class值)
3、根据元素的TagName属性查找元素:document.getElementsByTagName(标签名)
4、根据css属性查找元素:①查找一个元素:document.querySelector(css表达式)
②查找多个元素:document.querySelectorAll(css表达式)
二、获取元素属性:
1、document.getElementByXXX("").属性名
2、document.getElementByXXX("").getAttribute(属性名)
三、修改元素属性
1、document.getElementByXXX("").属性名=属性值
2、document.getElementByXXX("").setAttribute(属性名,属性值)
四、获取元素内容
1)获取的内容包含html标签:
document.getElementByXXX(" ").innerHTML
2)获取的内容不包含html标签,纯文本:
document.getElementByXXX(" ").innerText
五、修改元素内容:
1)获取的内容包含html标签:
document.getElementByXXX(" ").innerHTML=new HTML
2)获取的内容不包含html标签,纯文本:
document.getElementByXXX(" ").innerText = 文本文字
六、修改样式:
document.getElementByXXX(" ").style.样式名=样式值
例如:元素的可见性:document.getElementByXXX(" ").style.visibility='hidden'
元素的颜色:document.getElementByXXX(" ").style.color='blue'