Linear Regression with PyTorch
Problem Description
初始化一组数据 ((x,y)),使其满足这样的线性关系 (y = w x + b) 。然后基于反向传播法,用均方误差(mean squared error)
[MSE = frac{1}{n} sum_{n} (y- hat y)^{2}
]
去拟合这组数据。
衡量两个分布之间的距离,最直接的方法是用交叉熵。
我们用最简单的一元变量去拟合这组数据,其实一元线性回归的表达式 (y = wx + b) 用神经网络的形式可表示成如下图所示
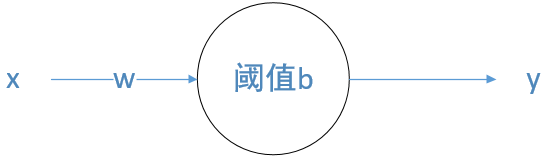
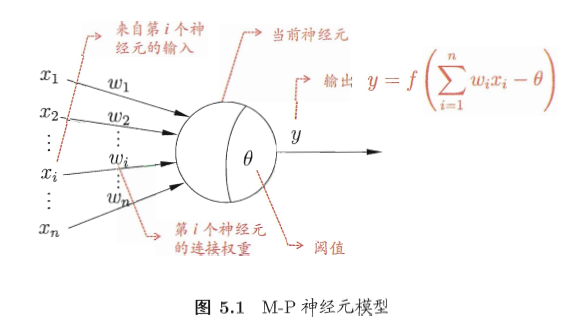
该神经网络有一个输入、一个输出、不使用任何激活函数。这就是一元线性回归的神经网络表示结果。相比较于下图这种神经网络的形式化表示,上图是一种简单的特例。
Key Points
torch.unsqueeze
重塑一个张量的 size,见下面代码
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
torch.linspace
得到一个在 start 和 end 之间等距的一维张量,见下面代码
>>> torch.linspace(1, 6, steps=3)
tensor([ 1.0000, 3.5000, 6.0000])
torch.rand
返回一个满足 size 维度要求的随机数组,随机数服从0-1均匀分布。
torch.nn.Linear(1,1)
self.prediction = torch.nn.Linear(1, 1)
这一行代码,实际是维护了两个变量,其描述了这样的一种关系:
[prediction_{1 imes1} = weight_{1 imes1} imes input_{1 imes1} + bias_{1 imes1}
]
其中,每个参数都是 (1 imes1) 维的。
Code
import torch
epoch = 10000
lr = 0.01
w = 10
b = 5
x = torch.unsqueeze(torch.linspace(1, 10, 20), 1)
y = w*x + b + torch.rand(x.size())
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.prediction = torch.nn.Linear(1, 1)
def forward(self, x):
out = self.prediction(x)
return out
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criticism = torch.nn.MSELoss()
for i in range(epoch):
y_pred = net(x)
loss = criticism(y_pred, y) # 先是 y_pred 然后是 y_true 参数顺序不能乱
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("%.5f" % loss.data)
print(net.state_dict()['prediction.weight'])
print(net.state_dict()['prediction.bias'])
输出:
0.08882
tensor([[ 9.9713]])
tensor([ 5.6524])
Results Analysis
输出显示:
- 均方误差(MSE)为 0.0882
- (weight) 的拟合结果为 9.9713
- (bias) 的拟合结果为 5.6524
分析:
- 因为我主动引入了误差(服从0-1均匀分布),而且是线性拟合,所以 MSE 几乎不能减小到零;
- 9.9713 的拟合值已经非常接近真实值 10 了;5.6524 的拟合值较真实值 5 的距离较大(距离约为自身的 10%)