清华大学研究生公开课
数据挖掘是数据科学,是多领域交叉学科:数据挖掘 = 机器学习 + 人工智能 + 模式识别 + 统计学
数据挖掘的广泛应用:
- Business Intelligence
- Data Analytics
- Big Data
- Decision Support
- Customer Relationship Management
"Education is the kindling of a flame, not the filling of a vessel."--Socrates
DRIP : Data Rich, Information Poor
Learning Resources
只有课堂上的传授是远远不够的,需要学生课后找书深入研究。
- 《Introduction to Data Mining》
- 《Data Mining : Practical Machine Learning Tools and Techniques》
- 《Beautiful Data : The Stories Behind Elegant Data Solutions》
- 《数据挖掘概念与技术》
- 《模式分类》
紧跟某个领域内最新动态的办法:
- 跟踪国际会议
- 关注权威期刊
- 关注业内大牛的研究方向
SVM : 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。
libsvm : A Library for Support Vector Machines
科学研究只有第一,没有第二。
搜文章、论文一定要用 Google、Google Scholar
weka: GUI化的数据挖掘软件,帮助建立对数据挖掘的感性认识,不必一开始就深入至算法层面。
神经网络软件包:matlab 收敛速度很快
KD nuggets: 数据挖掘相关数据、信息、工作机会。
学习基本原理
Tell me and I forget,(光是听老师讲,很快就会忘)
Teach me and I remember,(了解了原理以后,记忆的时间可能稍长一些)
Invoke me and I learn. (只有自己动手做过之后,才能掌握并且固化在脑海中)
"The value of college education is not the learning of many facts but the training of mind to think." -- Albert Einstain
Data
(从抽象的程度衡量)信息 > 数据
大数据的应用:
- 用户画像
- 流数据
- 预测犯罪发生
- 针对每个人的基因制定药量
- Urban Planning
关于大数据的两个定义:
- “Big data is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.” — Gartner
- “Big data refers to datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze.” — Mckinsey & Company
Synonym of data mining : knowledge discovery —— 数据挖掘的同义词是“知识发现”
数据挖掘的应用:
- 啤酒与尿布 (NOT REAL)
- money ball : 数据分析支持挑选适合自己球队的球员。
- Retail Data(零售数据) : Targeted Marketing
- Retail Data : Sentiment Analusis——零售业数据的情感分析,通过挖掘用户评论内容作消费者购物体验的分析
Is data mining realy important ?
“If you are looking for a career where your services will be in high demand, you should find something where you provide a scarce, complementary service to something that is getting ubiquitous and cheap. So what’s getting ubiquitous and cheap? Data. And what is complementary to data? Analysis. So my recommendation is to take lots of courses about how to manipulate and analyze data: databases, machine learning, econometrics, statistics, visualization, and so on.”——An interview with Google Chief Economist Hal Varian from the New York Times
From Data To Intelligence
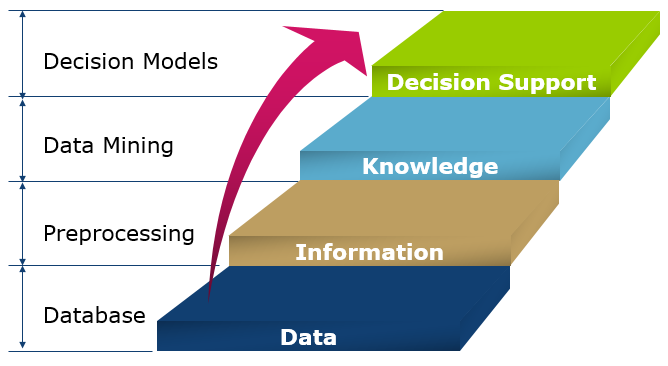
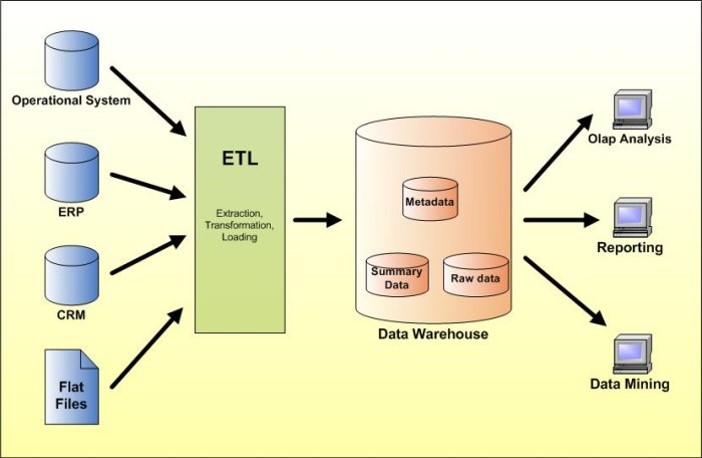
ETL : 提取、转换、装载
Data Integration & Analysis
DM Techniques - Classification
Definition : “Classification is a procedure in which individual items are placed into groups based on quantitative information on one or more characteristics (referred to as variables) and based on a training set of previously labeled items.”
Process : Given a training set: {(x1, y1), …, (xn, yn)}, produce a classifier (function) that maps any unknown object xi to its class label yi.
Algorithms :
- Decision Trees(决策树)
- K-Nearest Neighbours(K最邻近分类算法)
- Neural Networks(神经网络)
- Support Vector Machines(支持向量机)
Applications :
- Churn Prediction(流失预测)
- Medical Diagnosis(医学诊断)
Type : supervised learning(监督学习)
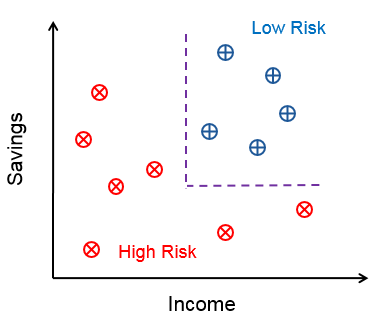
实质 : Classification Boundaries(分界面,如下图),对空间进行划分
Confusion Matrix(混淆矩阵,如下图)

Receiver Operating Characteristic(ROC曲线,如下图)
threshold 阀值,临界值
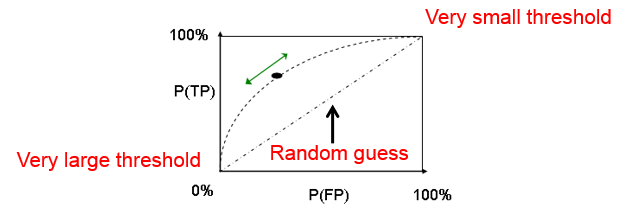
AUC(Area Under roc Curve)
衡量分类模型好坏的一个标准
DM Techniques - clustering
Definition : “Clustering is the assignment of a set of observations into subsets (called clusters) so that observations in the same cluster are similar in some sense.”
Distance Metrics(距离度量) :
- Euclidean Distance
- Manhattan Distance
- Mahalanobis Distance
Algorithms :
- K-Means
- Sequential Leader
- Affinity Propagation
Applications :
- Market Research
- Image Segmentation
- Social Network Analysis
Type : 无监督学习
Hierarchical Clustering(分层聚类,如下图)
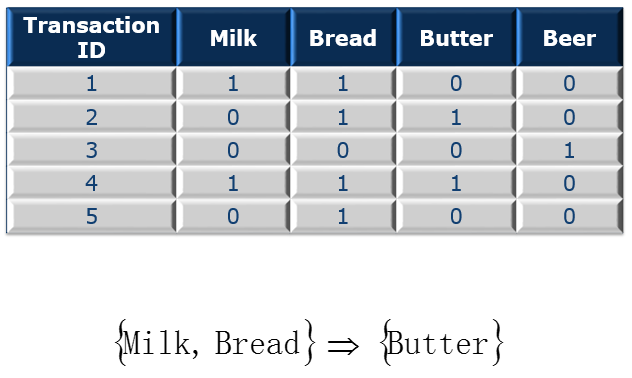
DM Techniques – Association Rule(关联规则)
如下图,如果买了牛奶和面包机器会自动推荐你买黄油
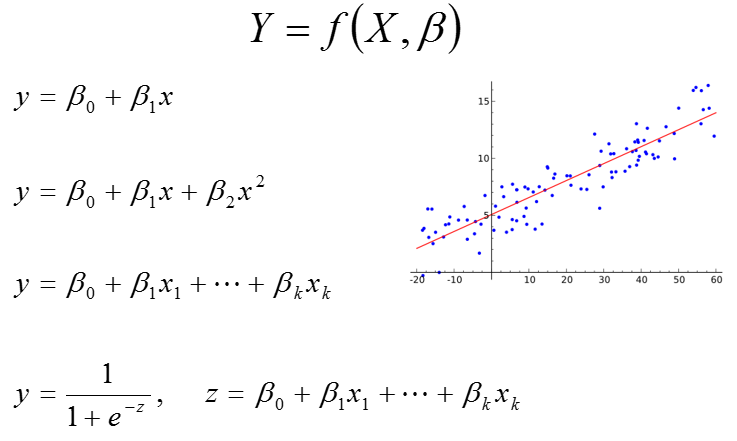
DM Techniques – Regression(线下回归,如下图)
Seeing is Knowing
**数据挖掘的 KEY POINT : 可解释性。 **
可视化软件
Data Preprocessing(数据预处理)
Real data are often surprisingly(惊人地) dirty.
- A Major Challenge for Data Mining
Typical Issues
- Missing Attribute Values
- Different Coding/Naming Schemes
- Infeasible Values(不可行的值)
- Inconsistent Data(不一致的值)
- Outliers(极端值)
Data Quality
- Accuracy
- Completeness
- Consistency
- Interpretability
- Credibility
- Timeliness
GIGO : garbage in garbage out.
Data Cleaning
- Fill in missing values.
- Correct inconsistent data.
- Identify outliers and noisy data.
Data Integration
- Combine data from different sources.
Data Transformation
- Normalization
- Aggregation
- Type Conversion
Data Reduction
- Feature Selection
- Sampling
数据挖掘相关问题
- 隐私保护
- 云计算:弹性扩容(如下图)避免机器资源浪费(Pay As You Go)
- 并行计算 : GPU 作为计算卡、科学计算、廉价的超级计算
The Big Picture
数据挖掘 = 数据 + 模型 + 高性能计算平台
如果强调结果的可解释性,选择:决策树。反之,神经网络。
聚类:K-means;分类:KNN
金融大数据:量化交易,克服交易者性格上的缺陷
数据挖掘不创造规律,它只能发掘规律。
负相关:A 增加则 B 减少
注意可能存在的“分组”规律、注意数据间的相关性、注意心理因素的影响
数据挖掘领域的经典问题:Survivorship Bias(幸存者偏差)