深度学习是一种特殊的机器学习,它可以获得高性能也十分灵活。它可以用概念组成的网状层级结构来表示这个世界,每一个概念更简单的概念相连,抽象的概念通过没那么抽象的概念计算。
“Deep learning is a particular kind of machine learning that achieves great power and flexibility by learning to represent the world as nested hierarchy of concepts, with each concept defined in relation to simpler concepts, and more abstract representations computed in terms of less abstract ones.”
a. 什么是机器学习?
通常,为了实现人工智能,我们会使用机器学习。我们有几种用于机器学习的算法。例如:
-
Find-S
-
决策树(Decision trees)
-
随机森林(Random forests)
-
人工神经网络(Artificial Neural Networks)
通常,有3类学习算法:
-
有监督机器学习算法进行预测。此外,该算法在分配给数据点的值标签中搜索模式。
-
无监督机器学习算法:没有标签与数据关联。并且,这些 ML 算法将数据组成簇。此外,他需要描述其结构,并使复杂的数据看起来简单且能有条理的分析。
-
增强机器学习算法:我们使用这些算法选择动作。并且,我们能看到它基于每个数据点。一段时间后,算法改变策略来更好地学习。
b.什么是深度学习?
任何深度神经网络都将包含以下三层:
-
输入层
-
隐藏层
-
输出层
我们可以说深度学习是机器学习领域的最新术语。这是实现机器学习的一种方式。
1.形状识别:
我们从一个简单的例子来看看我们认知层面上是如何区分物体的。比如我们要区分下面的形状,那个是圆的那个是方的:
我们的眼睛第一件要做的事情,就是看看这个形状有没有4条边。如果有的话,就进一步检查,这4条边是不是连在一起,是不是等长的,是不是相连的互相垂直。如果满足上面这些条件,那么我们可以判断,是一个正方形。
从上面的过程可以看出,我们把一个复杂的抽象的问题(形状),分解成简单的、不那么抽象的任务(边、角、长度...)。深度学习从很大程度上就是做这个工作,把复杂任务层层分解成一个个小任务。
2.识别狗和猫:
如果是传统机器学习的方法,我们会首先定义一些特征,如有没有胡须,耳朵、鼻子、嘴巴的模样等等。总之,我们首先要确定相应的“面部特征”作为我们的机器学习的特征,以此来对我们的对象进行分类识别。
而现在,深度学习的方法则更进一步。深度学习自动地找出这个分类问题所需要的重要特征!而传统机器学习则需要我们人工地给出特征!
我觉得这是两者最重要的区别。
那么,深度学习是如何做到这一点的呢?
以这个猫狗识别的例子来说,按照以下步骤:
1●首先确定出有哪些边和角跟识别出猫狗关系最大;2●然后根据上一步找出的很多小元素(边、角等)构建层级网络,找出它们之间的各种组合;3●在构建层级网络之后,就可以确定哪些组合可以识别出猫和狗。
这里我没找到猫和狗的神经网络图片,倒是看到人像识别的一个示意图,觉得挺好的:
人脸识别
可以看到4层,输入的是Raw Data,就是原始数据,这个机器没法理解。于是,深度学习首先尽可能找到与这个头像相关的各种边,这些边就是底层的特征(Low-level features),这就是上面写的第一步;然后下一步,对这些底层特征进行组合,就可以看到有鼻子、眼睛、耳朵等等,它们就是中间层特征(Mid-level features),这就是上面写的第二步;最后,我们对鼻子眼睛耳朵等进行组合,就可以组成各种各样的头像了,也就是高层特征(High-level features)这个时候就可以识别出或者分类出各种人的头像了。
三、对比机器学习和深度学习
上面我们大概了解了机器学习和深度学习的工作原理,下面我们从几个重要的方面来对比两种技术。
1.数据依赖
随着数据量的增加,二者的表现有很大区别:
数据量对不同方法表现的影响
可以发现,深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
2.硬件依赖
深度学习十分地依赖于高端的硬件设施,因为计算量实在太大了!深度学习中涉及很多的矩阵运算,因此很多深度学习都要求有GPU参与运算,因为GPU就是专门为矩阵运算而设计的。相反,普通的机器学习随便给一台破电脑就可以跑。
3.特征工程
特征工程就是前面的案例里面讲过的,我们在训练一个模型的时候,需要首先确定有哪些特征。
在机器学习方法中,几乎所有的特征都需要通过行业专家在确定,然后手工就特征进行编码。
然而深度学习算法试图自己从数据中学习特征。这也是深度学习十分引人注目的一点,毕竟特征工程是一项十分繁琐、耗费很多人力物力的工作,深度学习的出现大大减少了发现特征的成本。
4.解决问题的方式
在解决问题时,传统机器学习算法通常先把问题分成几块,一个个地解决好之后,再重新组合起来。但是深度学习则是一次性地、端到端地解决。如下面这个物体识别的例子:
物体识别
如果任务是要识别出图片上有哪些物体,找出它们的位置。那么传统机器学习的做法是把问题分为两步:发现物体 和 识别物体。首先,我们有几个物体边缘的盒型检测算法,把所有可能的物体都框出来。然后,再使用物体识别算法,例如SVM在识别这些物体中分别是什么。
但是深度学习不同,给它一张图,它直接给出把对应的物体识别出来,同时还能标明对应物体的名字。这样就可以做到实时的物体识别。例如YOLO net就可以在视频中实时识别:
实时检测
5.运行时间
深度学习需要花大量的时间来训练,因为有太多的参数需要去学习。顶级的深度学习算法ResNet需要花两周的时间训练。但是机器学习一般几秒钟最多几小时就可以训练好。
但是深度学习花费这么大力气训练处模型肯定不会白费力气的,优势就在于它模型一旦训练好,在预测任务上面就运行很快。这才能做到我们上面看到的视频中实时物体检测。
6.可理解性
最后一点,也是深度学习一个缺点。其实也说不上是缺点吧,那就是深度学习很多时候我们难以理解。一个深层的神经网络,每一层都代表一个特征,而层数多了,我们也许根本就不知道他们代表的啥特征,我们就没法把训练出来的模型用于对预测任务进行解释。例如,我们用深度学习方法来批改论文,也许我们训练出来的模型对论文评分都十分的准确,但是我们无法理解模型到底是啥规则,这样的话,那些拿了低分的同学找你质问“凭啥我的分这么低啊?!”,你也哑口无言····因为深度学习模型太复杂,内部的规则很难理解。
但是机器学习不一样,比如决策树算法,就可以明确地把规则给你列出来,每一个规则,每一个特征,你都可以理解。
但是这不是深度学习的错,只能说它太牛逼了,人类还不够聪明,理解不了深度学习的内部的特征。
自从 MIT Technology Review(麻省理工科技评论) 将 深度学习 列为 2013 年十大科技突破之首。加上今年 Google 的 AlphaGo 与 李世石九段 惊天动地的大战,AlphaGo 以绝对优势完胜李世石九段。人工智能、机器学习、深度学习、强化学习,成为了这几年计算机行业、互联网行业最火的技术名词。
其中,深度学习在图像处理、语音识别领域掀起了前所未有的一场革命。我本人是做图像处理相关的,以 2016 年计算机视觉三大会之一的 Conference on Computer Vision and Pattern Recognition(CVPR) 为例,在 Accept Papers 中,以 “Convolution” 关键词做搜索,就有 44 篇文章。以 “Deep” 为关键词搜索,有 96 篇文章:
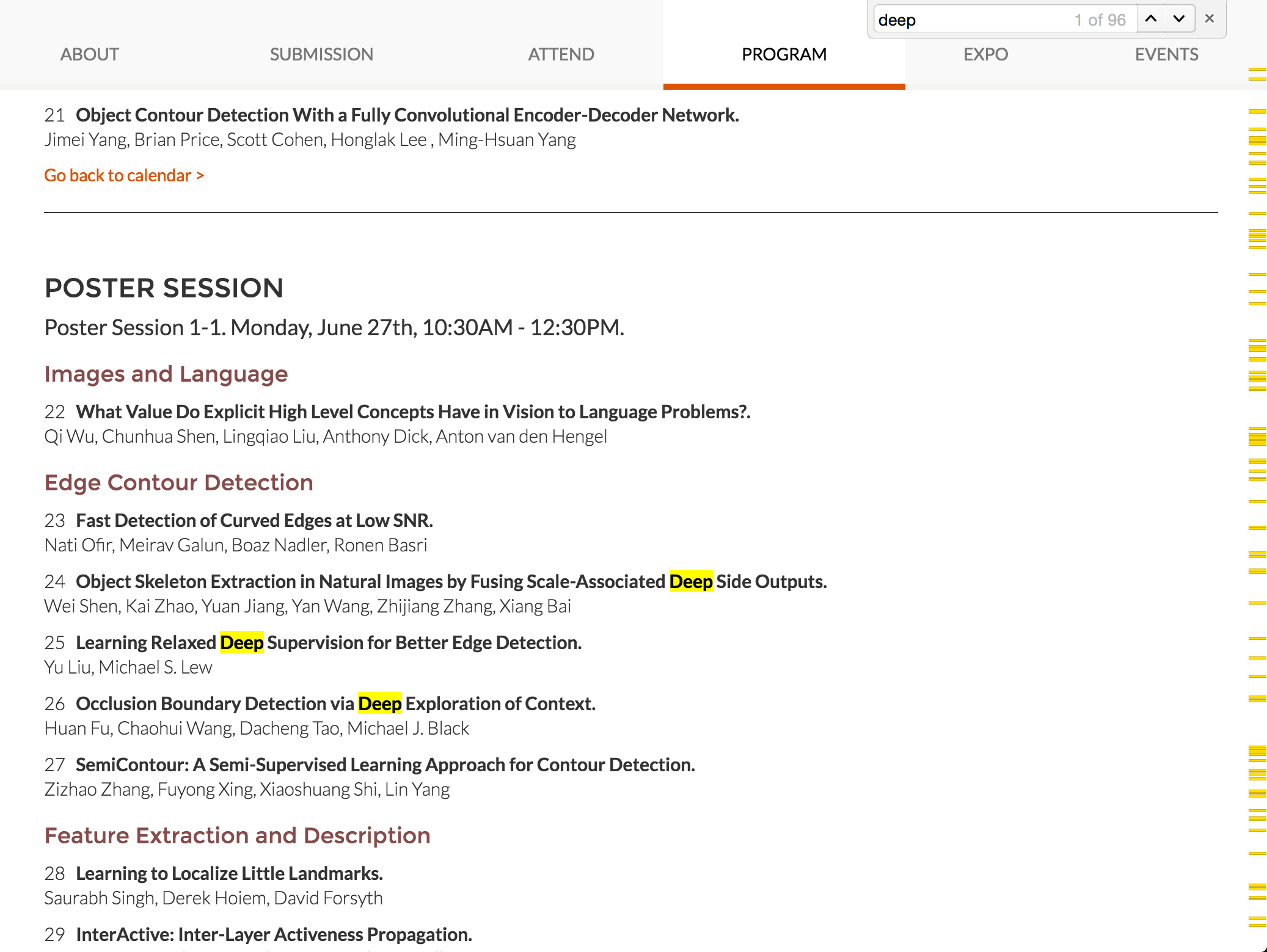
可以说,以 卷积神经网络(CNN)为代表的方法在图像处理领域已经取得了统治地位。同样的,以 递归神经网络(RNN) 在语音处理方面也大放异彩。
但是在深度学习独领风骚的同时,传统的机器学习算法,如 SVM 慢慢不像十多年前那么火热了,甚至受冷落了,如在上面 CVPR 2016 年 Accept Papers 页面中,搜索 “SVM”,仅仅有 4 篇文章:

相比于深度学习,传统的机器学习算法难道就此没落了吗,还有必要去学习吗?
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
所以,不禁很多人又这样的疑问,传统的机器学习算法难道就此没落了吗?还有必要去学习吗?
我认为传统的机器学习算法不会没落,非常有必要去学。
机器学习发展了二十多年来,已经渗透到很多领域,如 Robotics, Genome data, Financial markets。
而目前,深度学习占据统治地位的多数是在计算机视觉领域、自然语言处理领域。而且深度学习是 data driven 的,需要大量的数据,数据是其燃料,没了燃料,深度学习也巧妇难为无米之炊。如图像分类任务中,就需要大量的标注数据,因为有了 ImageNet 这样 百万量级,并带有标注 的数据,CNN 才能大显神威。
但是事实上,在实际的问题中,我们可能并不会有海量级别的、带有标注的数据。如暑假我在广州参加 CCF ADL70 机器学习研讨班的时候,碰到北京的一个药厂的学友,他们想用机器学习来预测药物对人的影响。但问题是,他们没有那么多的数据,仅仅就几十例,最多上百例的监督数据。据他们跟我介绍,他们就用的是 MCMC(Markov chain Monte Carlo) 的方法。
又比如说,我在研究我们老师的 正颌手术术后面型三维预测模拟及仿真分析 这个项目的时候,也是样本数量非常少,需要用这么少的数据来预测病人在做过正颌手术后面部的变形情况。
以上两种情况是非常常见的,这时候深度学习算法就无能为力,因为小数据下深度学习十分的容易 Overfitting。
通过上面的两个例子,我想说的是,在小数据集上,深度学习还取代不了诸如 非线性和线性核 SVM,贝叶斯分类器 方法。实际操作来看,SVM 只需要很小的数据就能找到数据之间分类的 超平面,得到很不错的分类结果。
所以,既然能用 Linear regression、Logistic regression 能解决的问题,那这时候还干嘛一定要用深度学习算法呢?况且,机器学习算法中,常常绕不开的 overfitting 问题,所以根据 奥卡姆剃刀原则:如无必要,勿增实体。这时候,能用简单的模型解决的问题,就不要用复杂的模型。
同样的,南大周志华老师也认为:即便是大数据,在无需另构特征的任务上也取代不了其他分类器。本质上,将它看作特征学习器比较合适。
所以,虽然深度学习发展如火如荼,但是其他机器学习算法并不会因此而没落。甚至我认为,结合深度学习,其他机器学习算法因此还可能获得新生。我了解的,清华大学的朱军老师 正在开发一个结合贝叶斯方法和深度学习方法的机器学习平台:ZhuSuan(珠算) Project,详情如下:

So,该做一个总结了。深度学习算法与传统的机器学习算法,各有利弊,大致如下:
-
深度学习是 data driven 的,需要大量的数据,而传统的机器学习算法通常不需要;
-
深度学习本质上可以看作一个特征学习器,在无需另构特征情况下,传统的机器学习算法已经能够胜任日常的任务;
- 如无必要,勿增实体。能够简单的模型解决的,不必要上深度学习算法,杀鸡焉用牛刀?