一、什么是Zookeeper?
Zookeeper(业界简称zk)是一种提供配置管理、分布式协同以及命名的中心化服务,这些提供的功能都是分布式系统中非常底层且必不可少的基本功能,但是如果自己实现这些功能而且要达到高吞吐、低延迟同时还要保持一致性和可用性,实际上非常困难。因此zookeeper提供了这些功能,开发者在zookeeper之上构建自己的各种分布式系统。
虽然zookeeper的实现比较复杂,但是它提供的模型抽象却是非常简单的。Zookeeper提供一个多层级的节点命名空间(节点称为znode),每个节点都用一个以斜杠(/)分隔的路径表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。例如,/zookeeper/config表示一个znode,它的父节点为/zookeeper,父父节点要为根节点/,根节点/没有父节点,通过在zkClient执行ls命令可以查看其内存目录结构:
[zk: localhost:2181(CONNECTED) 18] ls / [lock, zookeeper] [zk: localhost:2181(CONNECTED) 19] ls /zookeeper [config, quota] [zk: localhost:2181(CONNECTED) 20] ls /zookeeper/config [] [zk: localhost:2181(CONNECTED) 21] get /zookeeper/config
![]()
Zookeeper内存目录结构与文件系统不同的是,这些节点都可以设置关联的数据,可以通过get命令获取其关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M。
而为了保证高可用,zookeeper需要以集群形态来部署,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。客户端在使用zookeeper时,需要知道集群机器列表,通过与集群中的某一台机器建立TCP连接来使用服务,客户端使用这个TCP链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
架构简图如下所示:
![]()
客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的zookeeper机器来处理。对于写请求,这些请求会同时发给其他zookeeper机器并且达成一致后,请求才会返回成功。因此,随着zookeeper的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
有序性是zookeeper中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper最新的zxid。
如何使用zookeeper实现分布式锁?
在描述算法流程之前,先看下zookeeper中几个关于节点的有趣的性质:
-
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
-
临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
-
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:1)节点创建;2)节点删除;3)节点数据修改;4)子节点变更。
二、分布式锁
分布式锁,这个主要得益于 ZooKeeper 为我们保证了数据的强一致性。锁服务可以分为两类,一个是 保持独占,另一个是 控制时序。
1. 保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把 zk 上的一个 znode 看作是一把锁,通过 create znode 的方式来实现。所有客户端都去创建 /lock/xxxxx 节点,最终成功创建的那个客户端就可以认为成功的拥有了这把锁,可以继续执行后面的业务逻辑,创建不成功的节点会收到异常的提示。
成功获取锁的节点继续执行后续的业务逻辑,不过可能发生的情况是该服务正在执行业务逻辑时挂掉了,如服务器掉电了,这个时候该服务就不能够正常的从Zookeeper删除其创建的锁节点,为了避免死锁的发生,创建独占锁时指定的节点类型为临时节点,Zookeeper会监控该服务创建的所有临时节点,如果该服务与Zookeeper的Session断开了,则所有的临时节点都会被删除掉,从而避免了死锁的发生。
2. 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序控制其执行的顺序。做法和上面基本类似,只是这里 /lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的CreateMode属性控制,指定其值为CreateMode.EPHEMERALSEQUENTIAL 即表示为时有序节点)。Zk 的父节点(/lock)维持一份 sequence, 保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
时序节点分布式锁算法流程如下:
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
三、实现分布式控制的Java实现
1、Curator介绍
Apache Curator是一个比较完善的ZooKeeper客户端框架,是Netflix公司开源的一个ZooKeeper客户端封装,通过封装的一套高级API 简化了ZooKeeper的操作。通过查看官方文档,可以发现Curator主要解决了三类问题:
- 封装ZooKeeper client与ZooKeeper server之间的连接处理
- 提供了一套Fluent风格的操作API
- 提供ZooKeeper各种应用场景(recipe, 比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等)的抽象封装
Curator主要从以下几个方面降低了zk使用的复杂性:
- 重试机制:提供可插拔的重试机制, 它将给捕获所有可恢复的异常配置一个重试策略,并且内部也提供了几种标准的重试策略(比如指数补偿)
- 连接状态监控: Curator初始化之后会一直对zk连接进行监听,一旦发现连接状态发生变化将会作出相应的处理
- zk客户端实例管理:Curator会对zk客户端到server集群的连接进行管理,并在需要的时候重建zk实例,保证与zk集群连接的可靠性
- 各种使用场景支持:Curator实现了zk支持的大部分使用场景(甚至包括zk自身不支持的场景),这些实现都遵循了zk的最佳实践,并考虑了各种极端情况
2、Curator与Spring的整合
1)POM依赖
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.2.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.2.0</version> </dependency>
![]()
2)Spring初使化配置文件,如applicationContext-zookeeper.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:jee="http://www.springframework.org/schema/jee" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:util="http://www.springframework.org/schema/util" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-4.3.xsd http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-4.3.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.3.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.3.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd"> <description>ZK与Spring整合,启动项目时建立与ZK的连接</description> <!--ZK重试策略--> <bean id="retryPolicy" class="org.apache.curator.retry.RetryNTimes"> <!--重试次数--> <constructor-arg index="0" value="10"/> <!--每次间隔ms--> <constructor-arg index="1" value="5000"/> </bean> <!--ZK客户端--> <bean id="curatorFramework" class="org.apache.curator.framework.CuratorFrameworkFactory" factory-method="newClient" init-method="start"> <!--ZK服务地址,集群使用逗号分隔--> <constructor-arg index="0" value="127.0.0.1"/> <!--session timeout会话超时时间--> <constructor-arg index="1" value="10000"/> <!--ConnectionTimeoutMs创建连接超时时间--> <constructor-arg index="2" value="5000"/> <!--重试策略--> <constructor-arg index="3" ref="retryPolicy"/> </bean> </beans>
![]()
3)创建Zookeeper Curator的工具类(可以有也可以没有)
import javax.annotation.PostConstruct; import javax.annotation.Resource; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.imps.CuratorFrameworkState; import org.apache.zookeeper.ZooKeeper; import org.springframework.stereotype.Service; import lombok.extern.slf4j.Slf4j; /** * * @author fenglibin * */ @Service @Slf4j public class ZKCuratorUtil { // ZK客户端 @Resource(name = "curatorFramework") private CuratorFramework curatorFramework; public ZKCuratorUtil(CuratorFramework curatorFramework) { this.curatorFramework = curatorFramework; } /** * 初始化操作 */ @PostConstruct public void init() { log.info("Use zookeeper as the zookeeper's name space."); // 使用命名空间 curatorFramework = curatorFramework.usingNamespace("zookeeper"); } /** * 获取Zookeeper客户端连接 * * @return */ public CuratorFramework getCuratorFramework() { return curatorFramework; } public ZooKeeper getZooKeeper() throws Exception { return getCuratorFramework().getZookeeperClient().getZooKeeper(); } /** * 判断ZK是否连接 * * @return */ public boolean isStarted() { return curatorFramework != null && (curatorFramework.getState() == CuratorFrameworkState.STARTED); } /** * 判断是否已经停止 * * @return */ public boolean isStoped() { return curatorFramework == null || (curatorFramework.getState() == CuratorFrameworkState.STOPPED); } }
4)单元测试类
该单元测试实现的是一个独占锁,以确保交易系统中幂等实现逻辑,业务逻辑如下图所示:
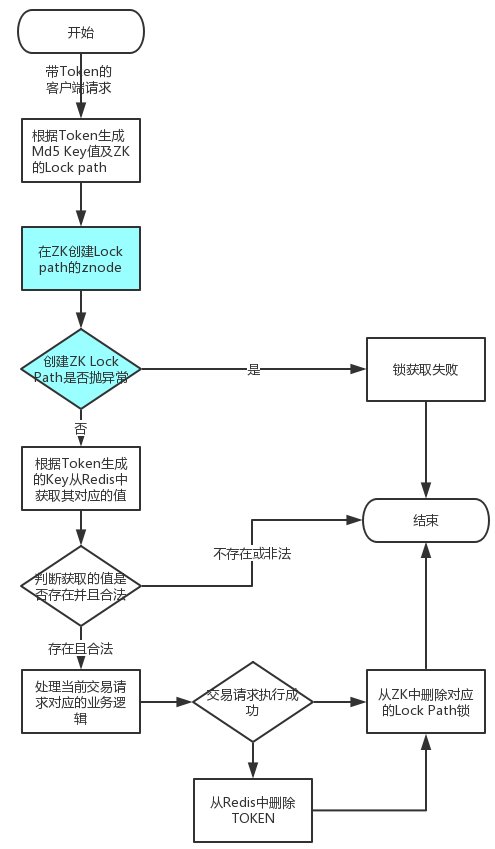
业务测试代码如下:
@Resource private RedisTemplate<String, String> redisTemplate; @Resource private ZKCuratorUtil zkCuratorUtil; //该路径必须先在zookeeper中创建,否则会报错 private String lockPath = "/lock/"; @Test public void testZookeeperLock() { // 用于判断交易唯一性和合法性的Token,在交易执行之前先保存在服务端, // 并且下发给客户端,客户端会在执行交易之前把Token带上,没带Token的 // 请求、Token不存在的服务端的请求、Token不正确的请求都视为非法请求 String token = "..."; String key = MD5Util.md5Of32(token); String currentLockPath = new StringBuilder(lockPath).append(key).toString(); boolean isGetLock = false; boolean handleSuccess = false; try { isGetLock = isGetLock(currentLockPath); if (!isGetLock) { log.warn("当前交易正在被处理中"); return; } log.info("处理交易开始"); String storedToken = redisTemplate.opsForValue().get(key); // 判断Token是否存在且合法 if (!token.equals(storedToken)) { log.warn("指定的Token不存在."); return; } handleSuccess = true; log.info("处理交易结束"); } catch (Exception e) { log.info("处理发生异常", e); } finally { if (handleSuccess) { // 限制了单个Token只能够执行一笔记交易,因而执行成功后将其删除 List<String> keys = new ArrayList<String>(); keys.add(key);// 限制了单个Token只能够执行一笔记交易,因而执行成功后将其删除 } if (isGetLock) { // 从Zookeeper删除用于锁定的key try { zkCuratorUtil.getZooKeeper().delete(currentLockPath, -1); } catch (Exception e) { log.error("Delete zookeeper path:" + currentLockPath + " failed.", e); } } } } /** * 使用在Zookeeper创建临时节点的机制,如果创建成功,则认为其获取锁成功, * 如果创建节点失败,则认为锁获取失败。 * @param currentLockPath 待创建的锁节点 * @return */ public boolean isGetLock(String currentLockPath) { String nowDate = String.valueOf(System.currentTimeMillis()); try { //在Zookeeper创建指定的临时节点,如果节点已经存在了,会抛出异常 zkCuratorUtil.getZooKeeper().create(currentLockPath, nowDate.getBytes(), Ids.READ_ACL_UNSAFE, CreateMode.EPHEMERAL); } catch (Exception e) { return false; } return true; }
![]()
参考:
https://blog.csdn.net/qiangcuo6087/article/details/79067136