hadoop 结构


[root@namenode ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.16.230.121 namenode 172.16.230.122 standbynamenode 172.16.230.123 datanode1 172.16.230.124 datanode2 172.16.230.125 datanode3
下载:
wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
解压缩:
tar -zxvf hadoop-3.2.1.tar.gz mv hadoop-3.2.1 /data/hadoop
创建hadoop账户,配置环境变量
for i in {121..125}; do ssh root@172.16.230.$i "useradd hadoop ; chown hadoop.hadoop /data/hadoop -R; echo "123456" | passwd --stdin hadoop"; done
配置环境变量
[hadoop@namenode ~]$ vim .bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions export JAVA_HOME=/data/jdk export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH export HADOOP_HOME=/data/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置hadoop. 进入到hadoop目录
[hadoop@namenode ~]$ cd /data/hadoop/etc/hadoop/
[hadoop@namenode hadoop]$ cat hadoop-env.sh | grep -v "#" | sed '/^$/d' export JAVA_HOME=/data/jdk export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)} export HDFS_NAMENODE_USER=hadoop export HDFS_DATANODE_USER=hadoop export HDFS_ZKFC_USER=hadoop export HDFS_JOURNALNODE_USER=hadoop export YARN_RESOURCEMANAGER_USER=hadoop export YARN_NODEMANAGER_USER=hadoop
配置core-site.xml
[hadoop@namenode hadoop]$ cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!--临时目录--> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmpdata</value> # 新建/data/hadoop/tmpdata/目录授权 </property> <!--webUI展示时的用户--> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> <!--高可用依赖的zookeeper的通讯地址--> <property> <name>ha.zookeeper.quorum</name> <value>kafka1:2181,kafka2:2181,kafka3:2181</value> </property> </configuration>
hdfs-site.xml
[hadoop@namenode hadoop]$ cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--定义hdfs集群中的namenode的ID号--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--定义namenode的主机名和rpc协议的端口--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>namenode:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>standbynamenode:8020</value> </property> <!--定义namenode的主机名和http协议的端口--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>namenode:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>standbynamenode:9870</value> </property> <!--定义共享edits的url--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://namenode:8485;standbynamenode:8485;datanode1:8485;datanode2:8485;datanode3:8485/ljgk</value> </property> <!--定义hdfs的客户端连接hdfs集群时返回active namenode地址--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--hdfs集群中两个namenode切换状态时的隔离方法--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--hdfs集群中两个namenode切换状态时的隔离方法的秘钥--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--journalnode集群中用于保存edits文件的目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/hadoop/journalnode/data</value> #新建journalnode 保存路径 </property> <!--ha的hdfs集群自动切换namenode的开关--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.safemode.threshold.pct</name> <value>1</value> </property> </configuration>
workers
[hadoop@namenode hadoop]$ cat workers
datanode1
datanode2
datanode3
yarn-site.xml
[hadoop@namenode hadoop]$ cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> <description>Enable RM high-availability</description> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> <description>Name of the cluster</description> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> <description>The list of RM nodes in the cluster when HA is enabled</description> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>namenode</value> <description>The hostname of the rm1</description> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>standbynamenode</value> <description>The hostname of the rm2</description> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>namenode:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>standbynamenode:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>kafka1:2181,kafka2:2181,kafka3:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
mapred-site.xml
[hadoop@namenode hadoop]$ cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
拷贝到 所有节点
[hadoop@namenode hadoop]$ for i in {122..125}; do scp -r /data/hadoop/ hadoop@172.16.230.$i:/data/; done [hadoop@namenode hadoop]$ mkidr -p /data/hadoop/journalnode/data/ [hadoop@namenode hadoop]$ mkidr -p /data/hadoop/tmpdata/ [hadoop@namenode hadoop]$ for i in {122..125}; do scp -r ~/.bashrc hadoop@172.16.230.$i:~/; done
启动:
1. 一定要先启动zookeeper集群
2. 启动journalnode
登陆到 每台机器上 启动 journalnode
hadoop-daemon.sh start journalnode
3. 格式化一个namenode
hdfs namenode -format
hadoop-daemon.sh start namenode
4. 启动standbynamenode 节点 namenode
#登陆到 standbynamenode 服务器,先手动执行数据同步, 再启动 hdfs namenode -bootstrapStandby hadoop-daemon.sh start namenode
5. 初始化zkfs(任意节点)
hdfs zkfc -formatZK
6.停止haoop所有进程
stop-dfs.sh
7. 启动所有
start-all.sh
上传测试:
[hadoop@namenode ~]$ hdfs dfs -mkdir /test [hadoop@namenode hadoop]$ hdfs dfs -put README.txt /test 2021-01-11 15:59:10,923 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [hadoop@namenode hadoop]$ hdfs dfs -ls /test
访问 9870 查看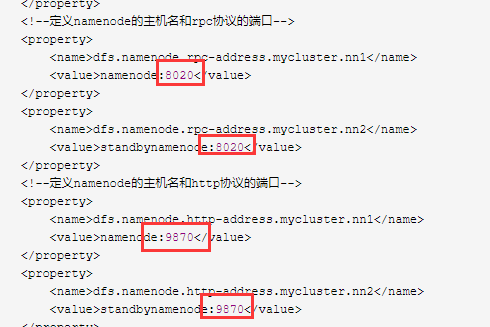
参考: https://segmentfault.com/a/1190000023834334