一、 单机模式Standalone Operation
单机模式也叫本地模式,只适用于本地的开发调试,或快速安装体验hadoop,本地模式的安装比较简单,下载完hadoop安装包就可以直接运行。
1、 下载安装jdk
(1) 一定要下载Oracle的官方jdk版本,这里实验的版本是jdk1.8.0_231,具体看hadoop的版本要求,否则会有不兼容的问题,下载地址:
(2) 将jdk-8u231-linux-x64.tar.gz 解压到 /opt/modules目录下
(3) 解压命令:
$ tar –zxvf jdk-8u231-linux-x64.tar.gz –C /opt/modules
(4) 执行命令vi /etc/profile设置JAVA_HOME环境变量,增加2行内容:
export JAVA_HOME=/opt/modules/jdk1.8.0_231 export PATH=$JAVA_HOME/bin:$PATH
(5) 执行命令,让设置生效
$ source /etc/profile
(6) 验证:
$ java –version
2、 下载安装hadoop
(1) 由于考虑到jdk和hadoop版本的兼容,下载时请看一下相关版本的要求,这里实验是hadoop-3.2.1,下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
(2) 将hadoop-3.2.1.tar.gz 解压到 /opt/modules目录下
(3) 解压命令:
$ tar –zxvf hadoop-3.2.1.tar.gz –C /opt/modules
(4) 执行命令vi /etc/profile设置JAVA_HOME和HADOOP_HOME环境变量,
增加1行内容:
export HADOOP_HOME=/opt/modules/hadoop-3.2.1
修改1行内容:
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
(5) 执行命令, 让设置生效
source /etc/profile
(6) 验证:
hadoop version
(7) 执行命令:hadoop,可以查看hadoop下的所有命令用法,和linux下的shell命令一样。
$ hadoop
3、 测试-使用hadoop做几个示例
(1) 统计文件的单词出现频次:
创建一个wc.input文件,将一些单词写入到文件中
$ echo 'hadoop mapreduce hivehbase spark stormsqoop hadoop hivespark hadoop' >> wc.input
用hadoop来统计文件wc.input中的单词频次,输出到output2文件目录
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /opt/data/wc.input /opt/data/output2
查看一下一下output2文件目录,part-r-00000是结果内容
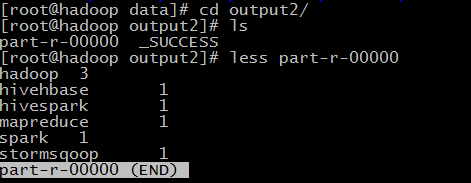
(2) 统计文件的数量
创建一个目录input3
$ mkdir /opt/data/input3
将hadoop目录下的所有文件拷贝到input3目录中
$ cp /opt/modules/hadoop-3.2.1/etc/hadoop/* /opt/data/input3
用hadoop来统计目录input3中以dfs开头命名的文件的名称和数量,输出到output3文件目录
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /opt/data/input3 /opt/data/output3 'dfs[a-z.]+'
查看一下一下output2文件目录,part-r-00000是结果内容
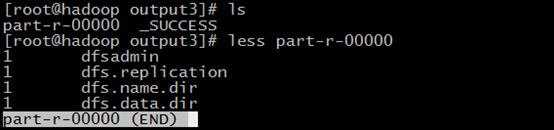
相关文章:伪分布模式Pseudo-Distributed Operation