3、 数据可视化:利用JavaWeb+Echarts完成数据图表展示过程(20分)
需求1:可视化展示截图
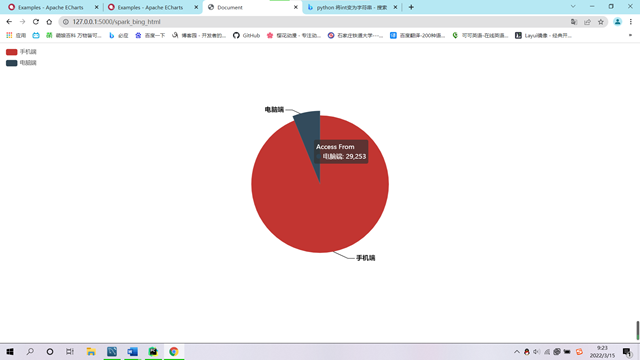
需求2:可视化展示截图
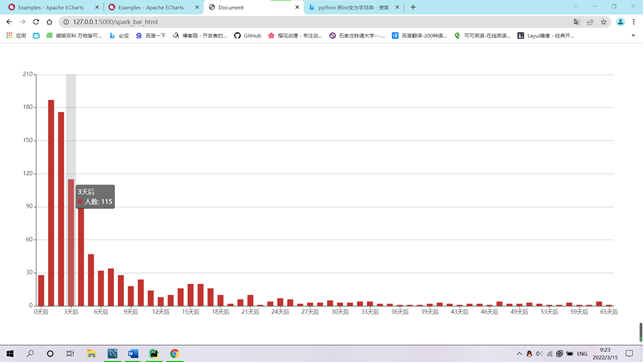
需求3:可视化展示截图
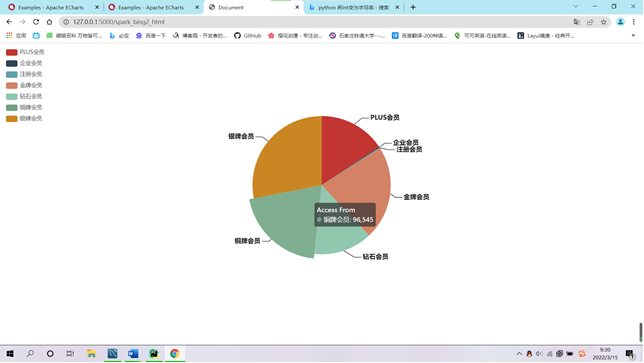
需求4:可视化展示截图

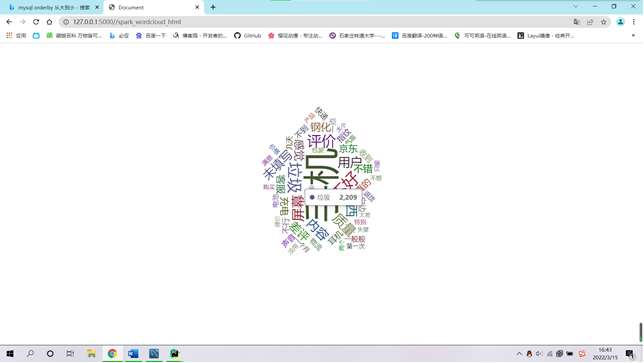
4、 中文分词实现用户评价分析。(20分)
(1)本节通过对商品评论表中的差评数据,进行分析,筛选用户差评点,以知己知彼。(筛选差评数据集截图)
通过观察的当用户评价星级grade小于等于3时,用户的差评具有实际意义,通过grede《=3来获取用户差评数据集。
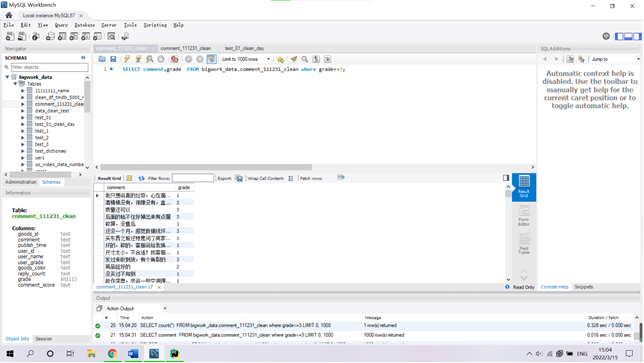
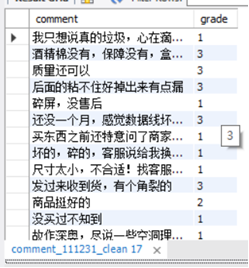
将数据导出为txt文件备用:
SELECT comment,grade FROM bigwork_data.comment_111231_clean where grade<=3 into outfile 'C:\\ProgramData\\MySQL\\MySQL Server 5.7\\Uploads\\ChaPing.txt';
(2)利用 python 结巴分词实现用户评价信息中的中文分词及词频统计;(分词后截图)
代码:
import jieba
txt = open("Data/ChaPing.txt", encoding="utf-8").read()
#加载停用词表
stopwords = [line.strip() for line in open("CS.txt",encoding="utf-8").readlines()]
words = jieba.lcut(txt)
counts = {}
for word in words:
#不在停用词表中
if word not in stopwords:
#不统计字数为一的词
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(100):
word, count = items[i]
print ("{:<10}{:>7}".format(word, count))
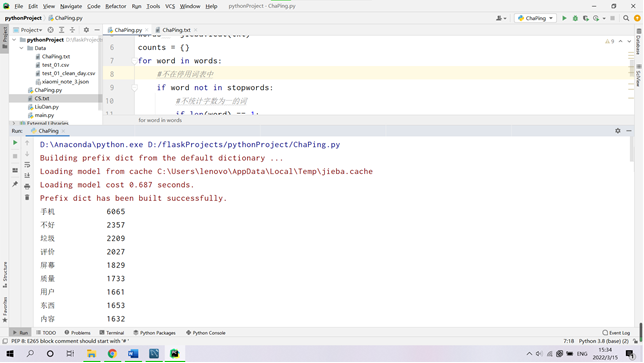
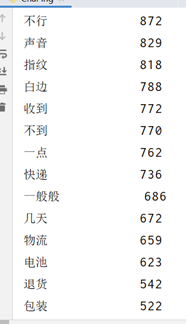
导入数据库供可视化使用:
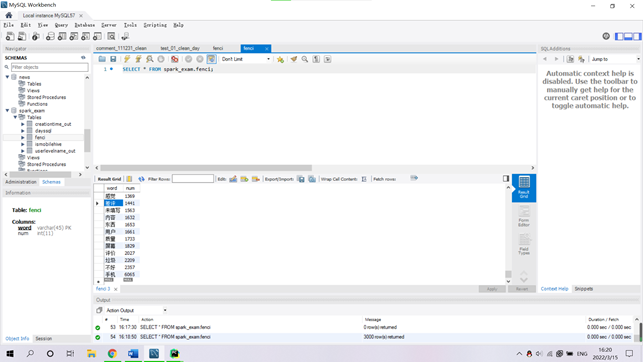
(3)在 hive 中新建词频统计表并加载分词数据;
要求实现:
①实现用户评价信息中的中文分词;

②实现中文分词后的词频统计;
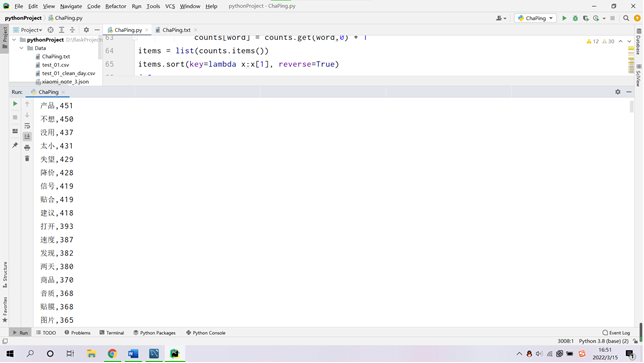
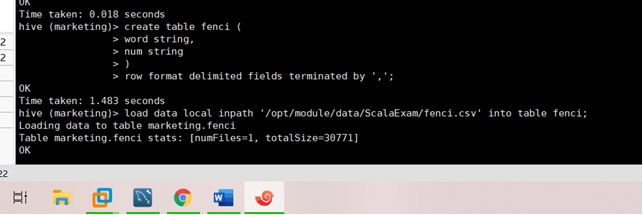
③在 hive 中新建词频统计表加载分词数据;
drop table if exists fenci;
create table fenci (
word string,
num string
)
row format delimited fields terminated by ',';
load data local inpath '/opt/module/data/ScalaExam/fenci.csv' into table fenci;
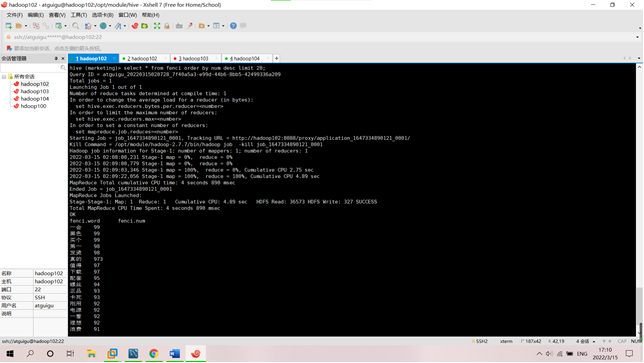
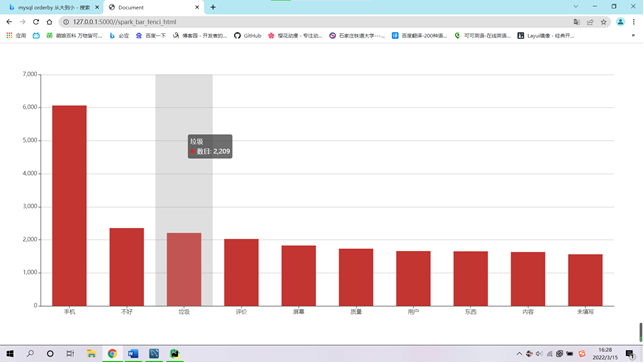
④柱状图可视化展示用户差评的统计前十类。
⑤用词云图可视化展示用户差评分词。