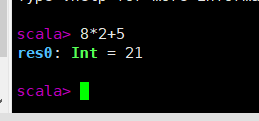
在spark shell中运行代码:
- Spark Shell 提供了简单的方式来学习Spark API
- Spark Shell可以以实时、交互的方式来分析数据
- Spark Shell支持Scala和Python
- 一个Driver就包括main方法和分布式集群
- Spark Shell本身就是一个Driver,里面已经包含了main方法
spark-shell命令以及常用参数如下:
./bin/spark-shell --master <master-url>
Spark的运行模式取决于传递给SparkContext的Master URL的值。
Master URL可以是以下任一种形式:
- local 使用一个Worker线程本地化运行SPARK(完全不并行)
- local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
- local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
- spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077 采用默认的集群管理器
- yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
- yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
- mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050
再采用本地模式启动时主要包含以下参数:
--master:这个参数表示当前的Spark Shell要连接到哪个master,如果是local[*],就是使用本地模式启动spark-shell,其中,中括号内的星号表示需要使用几个CPU核心(core),也就是启动几个线程模拟Spark集群
--jars: 这个参数用于把相关的JAR包添加到CLASSPATH中;如果有多个jar包,可以使用逗号分隔符连接它们
输入:./bin/spark-shell 默认是local模式
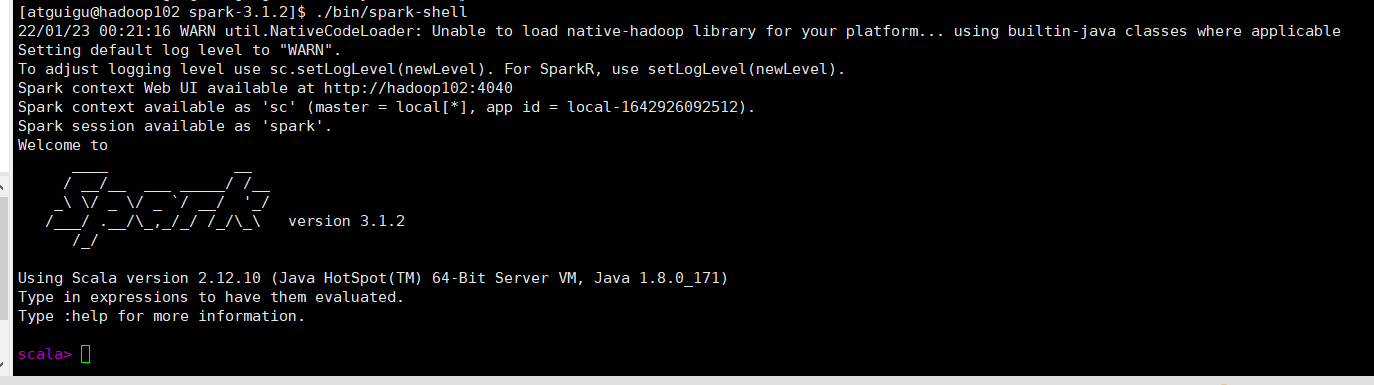
输入代码测试一下