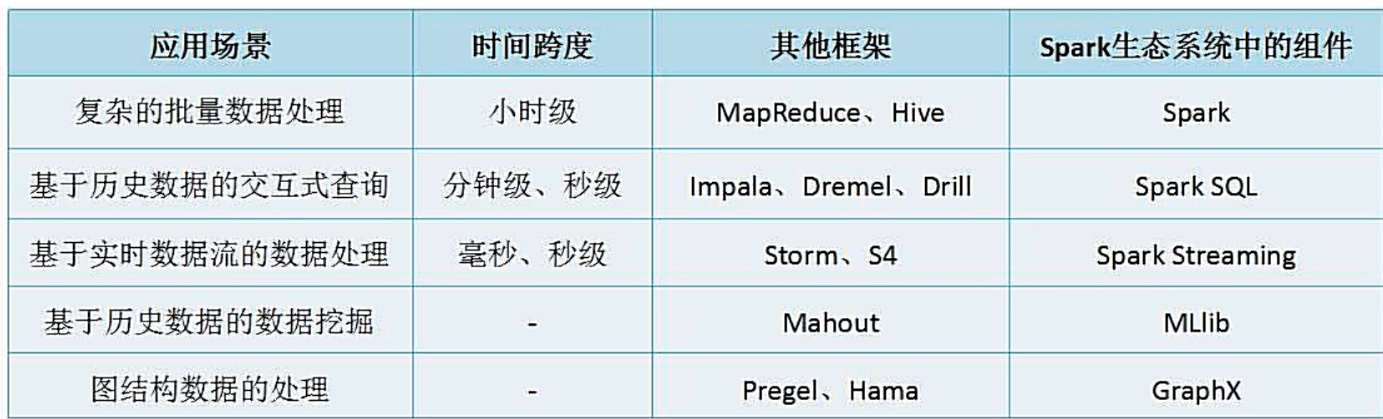
在实际应用中,大数据处理主要包括以下三个类型:
- 复杂的批量数据处理,通常时间跨度在数十分钟到数小时之间
- 基于历史数据的交互式查询,通常时间跨度在数十秒到数分钟之间
- 基于实时数据流的数据处理,通常时间跨度在数百毫秒到数秒之间
当同时存在以上三种场景时,就需要同时部署三种不同的软件:
- 复杂的批量数据处理

- 基于历史数据的交互式查询

-
基于实时数据流的数据处理

问题:
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- 不同的软件需要不同的开发和维护团队,带来了较高的使用成本
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配
Spark设计:遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统
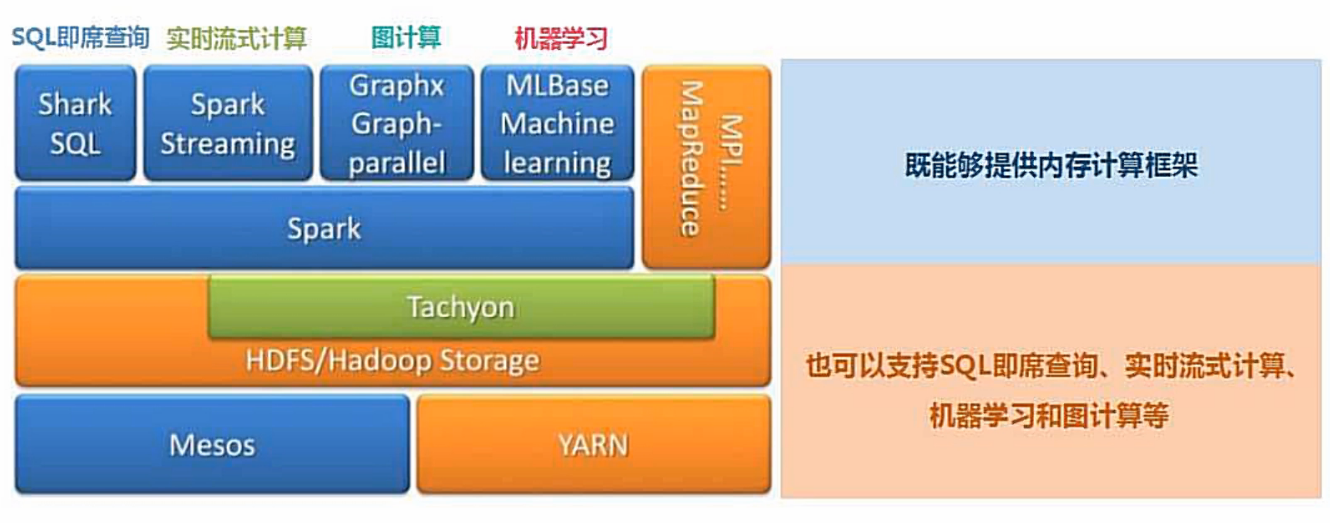
Spark生态系统:
- Spark Streaming提供流计算功能
- Mllib提供机器学习算法库的组件
- Spark Core提供内存计算
- Spark SQL提供交互式查询分析
- Graphx提供图计算
Spark生态系统组件的应用场景: