今日正式学习spark,先对spark进行简单的了解。
Spark框架:

Spark生态系统:

Hadoop与Spark的对比;
Hadoop存在的缺点:
- 表达能力有限
- 磁盘IO开销大
- 延迟高:任务之间的衔接涉及IO开销,前一个任务执行完之前,其他任务无法开始,难以胜任复杂、多阶段的任务。
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题
相比于Hadoop MapReduce,Spark主要具有如下优点:
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
- Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
Hadoop与Spark流程对比:
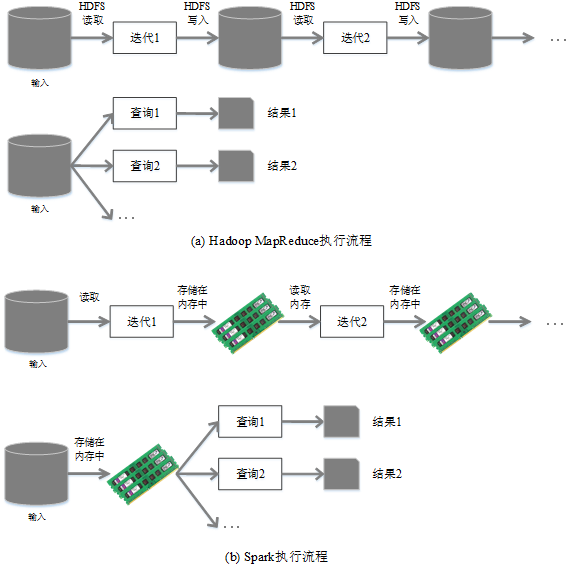
使用Hadoop进行迭代计算非常耗资源
Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
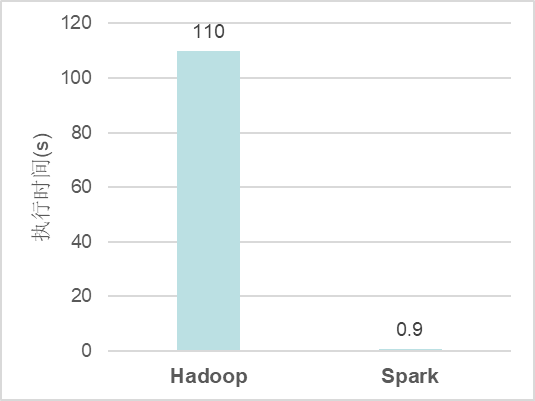
Hadoop与Spark执行逻辑回归的时间对比: