5.4 where
本数据集收集的是美国地区的电影数据,对于电影的制作公司以及制作国家,在本次的故事 背景下不作分析。
5.5 who
5.5.1 分析票房分布及票房 Top10 的导演
先统计除各个制片公司的电影数量和:
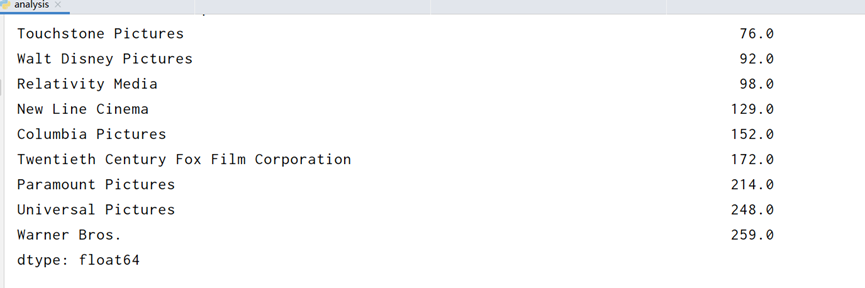
#production_companies制片公司
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
temp_list = clean_df_tmdb_5000_movies["production_companies"].str.split(",").tolist()
#Phantom Sound,Vision The Sisterhood of the Traveling Pants 2
#Artisan Entertainment The Way of the Gun
#Vincent Gallo Buffalo '66
genre_list = list(set([i for j in temp_list for i in j]))
# 构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((clean_df_tmdb_5000_movies.shape[0], len(genre_list))), columns=genre_list)
# print(zeros_df)
# 给每个制片公司出现的位置赋值为1
for i in range(clean_df_tmdb_5000_movies.shape[0]):
# zeros_df.loc[0,["Sci-fi","Mucical"]]=1
zeros_df.loc[i, temp_list[i]] = 1
# print(zeros_df.head(3))
# 统计每个制片公司数量和
genre_count = zeros_df.sum(axis=0)
# print(genre_count)
# 排序
genre_count = genre_count.sort_values()
genre_count_clean = genre_count[:-1]
print(genre_count_clean)

由于制片公司太多取20个展示
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
production_companies_list=(get_production_companies().index)
revenue_list = [] # 收入
num = clean_df_tmdb_5000_movies.shape[0] # 电影数目
for i in range(len(production_companies_list)):
revenue_list.append(0)
for i in range(len(production_companies_list)):
for j in range(num):
if(production_companies_list[i] in clean_df_tmdb_5000_movies["production_companies"][j]):
revenue_list[i]=revenue_list[i]+clean_df_tmdb_5000_movies["revenue"][j]
plt.figure(figsize=(20, 8), dpi=80)
labels = production_companies_list[-10:]
sizes = revenue_list[-10:]
explode = (0, 0.1, 0, 0) # 0.1表示将Hogs那一块凸显出来
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=False, startangle=90) # startangle表示饼图的起始角度
plt.axis('equal') # 加入这行代码即可!
plt.show()
Top10:
数据放进字典中对字典进行排序即可得到排序
map= {}
for i in range(len(production_companies_list)):
map[production_companies_list[i]]=revenue_list[i]
sorted(map.items(), key=lambda item: item[1])
print(map)
利用直方图展示出来:
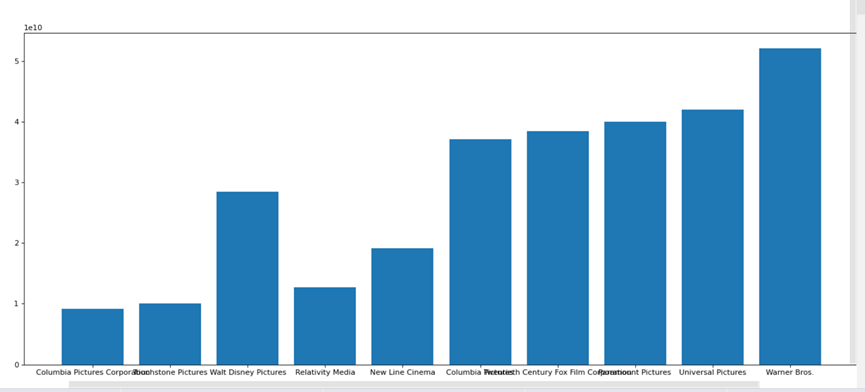
5.5.2 分析评分分布及评分 Top10 的导演
与票房同理,只不过变为评分
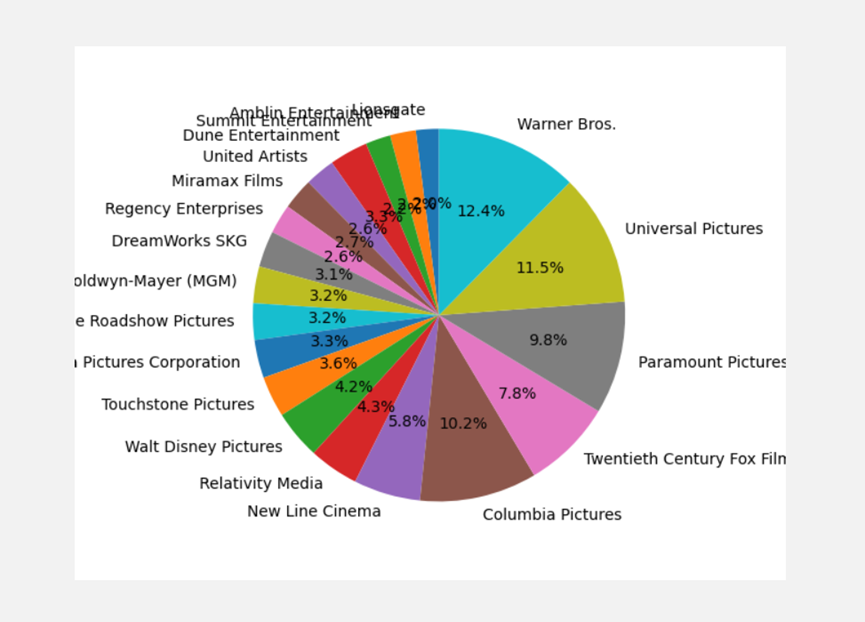
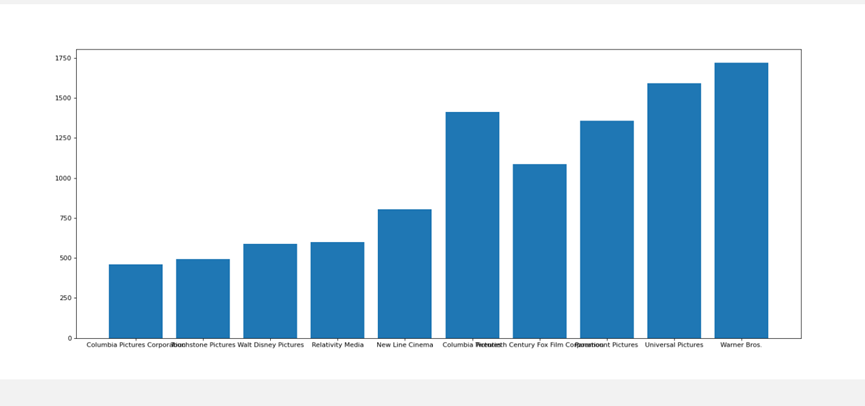
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
production_companies_list = (get_production_companies().index)
revenue_list = [] # 收入
num = clean_df_tmdb_5000_movies.shape[0] # 电影数目
for i in range(len(production_companies_list)):
revenue_list.append(0)
for i in range(len(production_companies_list)):
for j in range(num):
if (production_companies_list[i] in clean_df_tmdb_5000_movies["production_companies"][j]):
revenue_list[i] = revenue_list[i] + clean_df_tmdb_5000_movies["vote_average"][j]
plt.figure(figsize=(20, 8), dpi=80)
map= {}#利用字典进行排序
for i in range(len(production_companies_list)):
map[production_companies_list[i]]=revenue_list[i]
sorted(map.items(), key=lambda item: item[1])
_x=list(map.keys())[-10:]
_y_count=list(map.values())[-10:]
print(_y_count)
# 直方图
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y_count)
plt.xticks(range(len(_x)), _x)
plt.show()
labels = production_companies_list[-20:]
sizes = revenue_list[-20:]
explode = (0, 0.1, 0, 0) # 0.1表示将Hogs那一块凸显出来
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=False, startangle=90) # startangle表示饼图的起始角度
plt.axis('equal') # 加入这行代码即可!
plt.show()