5 数据分析
5.1 why 想要探索影响票房的因素,从电影市场趋势,观众喜好类型,电影导演,发行时间,评分与 关键词等维度着手,给从业者提供合适的建议。
5.2 what
5.2.1 电影类型:定义一个集合,获取所有的电影类型
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 电影分类
# 统计分类列表
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
temp_list = clean_df_tmdb_5000_movies["genres"].str.split(",").tolist()
genre_list = list(set([i for j in temp_list for i in j]))
# 构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((clean_df_tmdb_5000_movies.shape[0], len(genre_list))), columns=genre_list)
print(zeros_df)
# 给每个顶电影出现的位置赋值为1
for i in range(clean_df_tmdb_5000_movies.shape[0]):
# zeros_df.loc[0,["Sci-fi","Mucical"]]=1
zeros_df.loc[i, temp_list[i]] = 1
print(zeros_df.head(3))
# 统计每个分类电影数量和
genre_count = zeros_df.sum(axis=0)
print(genre_count)
# 排序
genre_count = genre_count.sort_values()
print(genre_count)
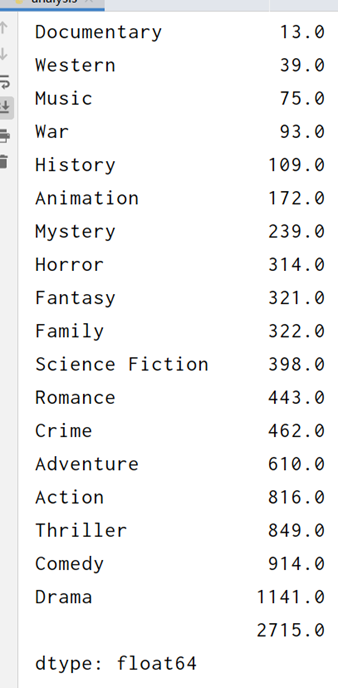
注意到集合中存在多余的元素:空的单引号,所以需要去除。
由于类型属性的值是"Action,Adventure,Fantasy,Science Fiction,"这种形式所以按逗号分割时会有空值,所以要去掉空值
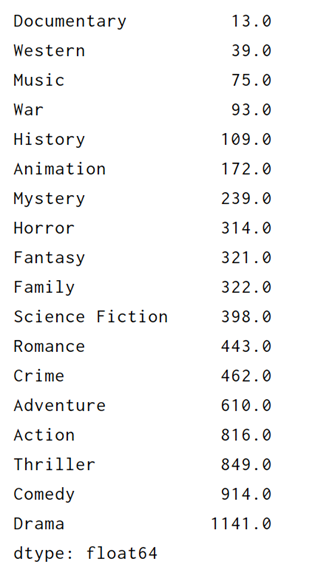
genre_count_clean=genre_count[:-1]
print(genre_count_clean)
5.2.1.1 电影类型数量(绘制条形图)
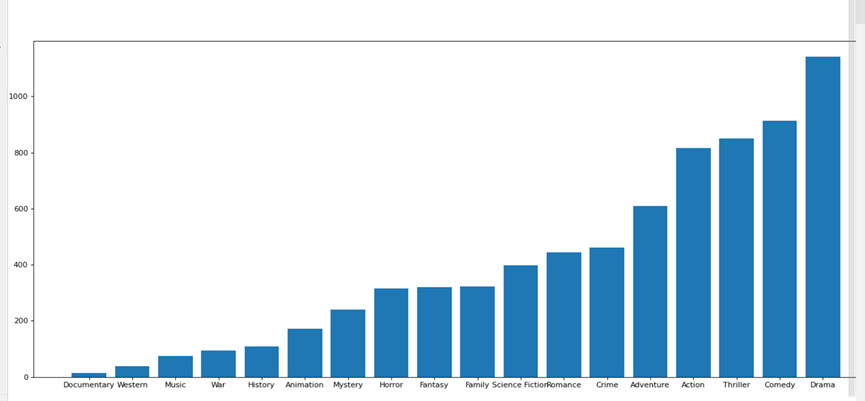
_x=genre_count_clean.index
_y=genre_count_clean.values
# 设置图形的大小
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()
5.2.1.2 电影类型占比(绘制饼图)
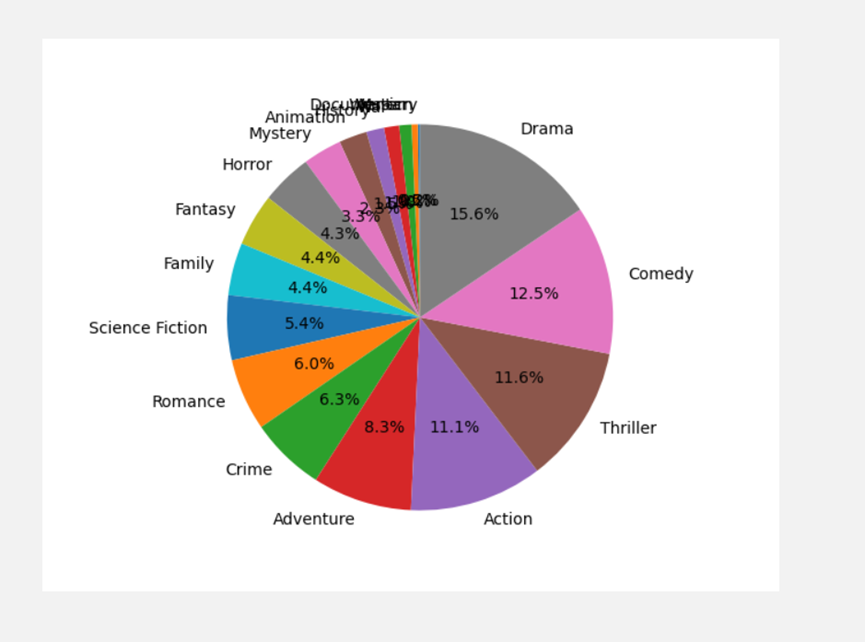
#饼状图
labels =genre_count_clean.index
sizes =genre_count_clean.values
explode = (0, 0.1, 0, 0) # 0.1表示将Hogs那一块凸显出来
plt.pie(sizes,labels=labels, autopct='%1.1f%%', shadow=False,startangle=90) # startangle表示饼图的起始角度
plt.axis('equal') # 加入这行代码即可!
plt.show()
5.2.1.3 电影类型变化趋势(绘制折线图)
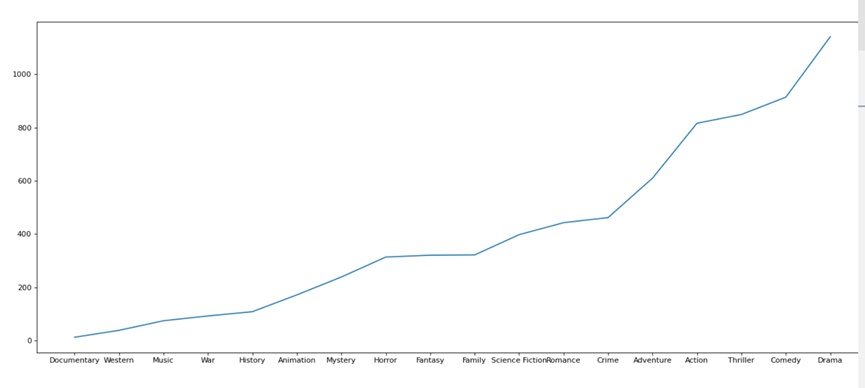
#折线图
plt.figure(figsize=(20, 8), dpi=80)
plt.plot(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x)
plt.show()
5.2.1.4 不同电影类型预算/利润(绘制组合图)
Budget预算revenue收入
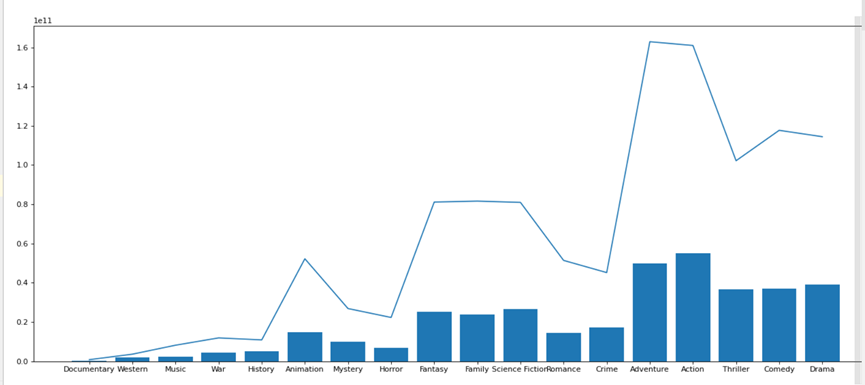
先获取各类型的预算与收入
#budget预算revenue收入
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 电影分类
# 统计分类列表
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
genre_count_clean=plot_bar_bin()
_type=genre_count_clean.index
budget_list=[]#预算
budget_list=create_0()#初始值设为0
revenue_list=[]#收入
revenue_list=create_0()
num=clean_df_tmdb_5000_movies.shape[0]#电影数目
print(len(_type))
for i in range(len(_type)):
for j in range(num):
if(_type[i] in clean_df_tmdb_5000_movies["genres"][j]):
budget_list[i]=budget_list[i]+clean_df_tmdb_5000_movies["budget"][j]
revenue_list[i]=revenue_list[i]+clean_df_tmdb_5000_movies["revenue"][j]
print(budget_list)
print(revenue_list)
在绘制组合图
_x = genre_count_clean.index
_y_budget = budget_list
_y_revenue = revenue_list
# 设置图形的大小
# 直方图
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y_budget)
plt.plot(range(len(_x)), _y_revenue)
plt.xticks(range(len(_x)), _x)
plt.show()
5.2.2 电影关键词(keywords 关键词分析,绘制词云图)

# budget预算revenue收入
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
#显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
num=clean_df_tmdb_5000_movies.shape[0]
text=""
for i in range(num):
try:
text=text+clean_df_tmdb_5000_movies["keywords"][i]
except:
print("NaN")
# os.path.join()函数: 连接两个或者更多的路径名组件
# 加入(encoding='gb18030', errors='ignore')是为了防止出现解码错误,是可以省略的,但省略后如出现错误,可查阅“参考文献[1]”
wc = WordCloud(scale=1, max_font_size=100)
# 词云参数设置
wc.generate(text)
# genarate v.生成; Python中称为使用生成器
plt.imshow(wc, interpolation='bilinear')
# 显示图像
# bilinear adj.双直线的;双线性的;双一次性的;
plt.axis('off')
# 隐藏坐标轴
plt.tight_layout()
# tight_layout会自动调整子图参数,使之填充整个图像区域。
# tight adj. 紧的;紧身的;挤满的;layout n.排版;布局;设计
plt.savefig('tu1.png', dpi=300)
# 保存词云图,分辨率为300,也可以用 wc.to_file('1900_basic.png')
plt.show()
# plt.imshow()函数负责对图像进行处理,并显示其格式
# plt.show()则是将plt.imshow()处理后的函数显示出来。
5.3 when
查看 runtime 的类型,发现是 object 类型,也就是字符串,所以,先进行数据转化。
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
print( clean_df_tmdb_5000_movies["runtime"])
5.3.1 电影时长(绘制电影时长直方图)
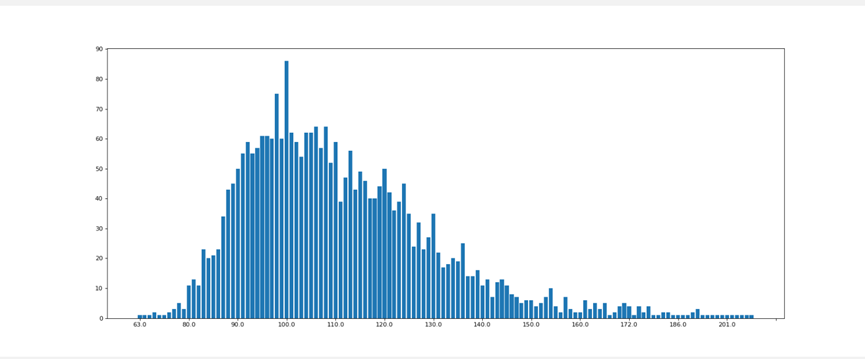
clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
# 准备数据
runtime_data = clean_df_tmdb_5000_movies["runtime"].tolist()
runtime_data.sort()
_y_count=[]
for i in range(len(set(runtime_data))):
_y_count.append(0)
flag=0
for i in set(runtime_data):
_y_count[flag]=runtime_data.count(i)
flag=flag+1
_x = set(runtime_data)
print(_x)
print(_y_count)
# 设置图形的大小
# 直方图
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y_count)
plt.xticks(range(len(_x)), _x)
x_major_locator = MultipleLocator(10)
# 把x轴的刻度间隔设置为1,并存在变量里
y_major_locator = MultipleLocator(10)
# 把y轴的刻度间隔设置为10,并存在变量里
ax = plt.gca()
# ax为两条坐标轴的实例
ax.xaxis.set_major_locator(x_major_locator)
# 把x轴的主刻度设置为1的倍数
ax.yaxis.set_major_locator(y_major_locator)
# 把y轴的主刻度设置为10的倍数
plt.show()
5.3.2 发行时间(绘制每月电影数量和单片平均票房)
Pass