用户可以自己定义文件上传的格式
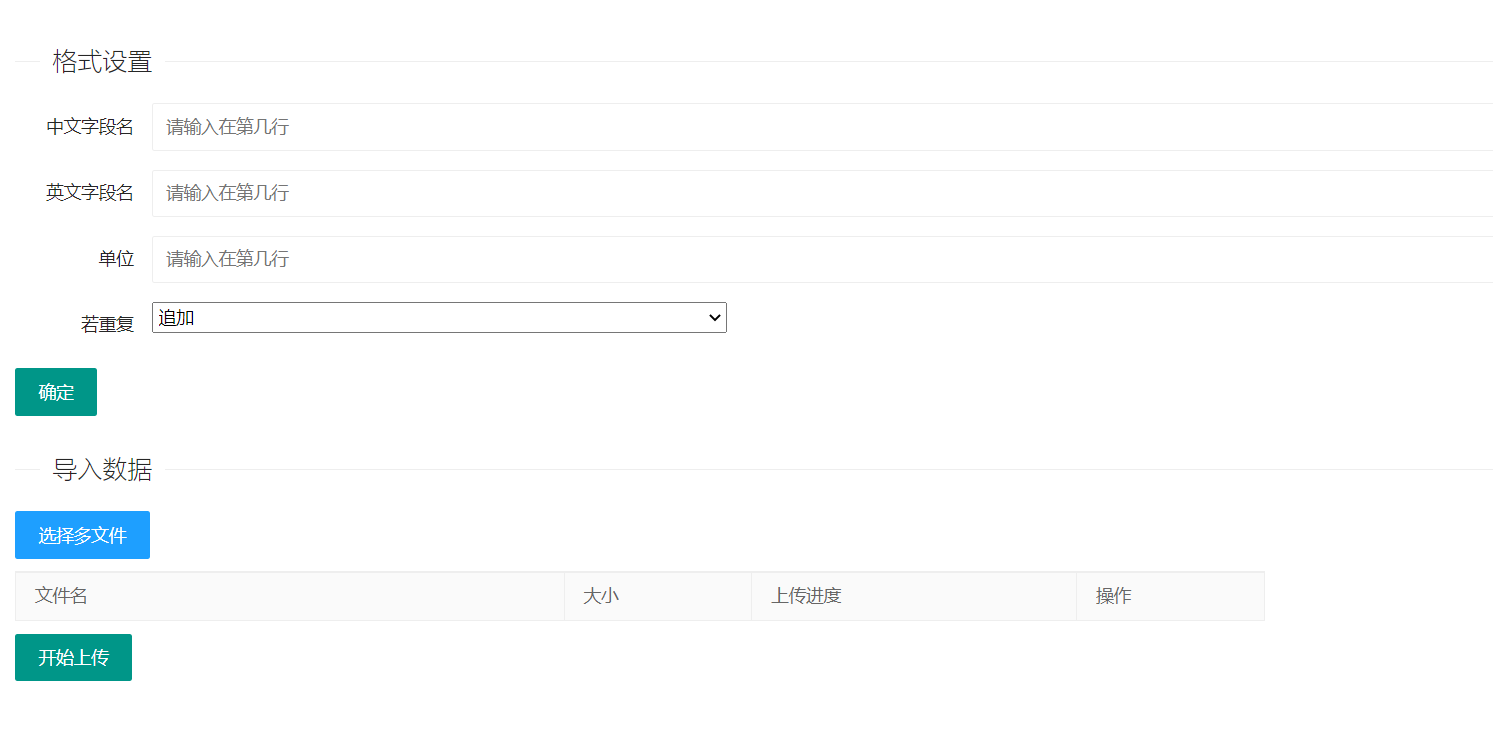
@app.route('/import_data', methods=['POST', 'GET']) def import_data(): #用户 user_id=session['user_id'] #设置flag以确定是否写入成功 flag=0; #返回码含义:0上传失败,1上传成功,2上传类型不符,但是还会上传,传到test_data,3文件名重复已覆盖,4文件名重复以追加5填写格式 #获取文件 the_file = request.files.get("file") # 判断文件类型 file_type=the_file.filename.split(".")[1] file_name=the_file.filename.split(".")[0] file_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") file_data = fileroot.find_filedata_filename(file_name) #判断格式是否设置 if(china_row_0==english_row_0==unit_row_0==0):#判断文件格式是否填写 return jsonify({"code": 5, "msg": "", "data": ""}) else:#填写后根据文件类型上传 #使用全局变量 china_row_flag=china_row_0 english_row_flag = english_row_0 unit_row_flag = unit_row_0 type_flag=type_0 flag_came=0#判断文件是否重复 if(fileroot.find_filedata_filename(file_name)==()): flag_came=0 else: flag_came=1 print("文件上传配置:") print(china_row_flag,english_row_flag,unit_row_flag,type_flag) if(file_type=="csv" or file_type=="txt"):#1.保存文件2.写入文件状态表3.导入数据库4.修改状态 # 保存文件到指定路径 the_file.save("score_table/" + the_file.filename) file_size=os.path.getsize("score_table/"+the_file.filename) # 记录文件基本信息 if(flag_came==0): fileroot.file_root(file_name,file_time,file_type,""+hum_convert(file_size),user_id) fileroot.file_update_state(file_name,"已上传") print("文件类型:"+file_type+",文件大小:"+""+hum_convert(file_size)+",上传时间:"+file_time+",文件名:"+file_name+",上传用户:"+user_id) #将文件存入数据库 flag=connectsql.read_csv(the_file.filename,china_row_flag,english_row_flag,unit_row_flag,type_flag)#将文件存入数据库、 #修改状态 fileroot.file_update_state(file_name, "已导入数据库") #excel_example文件夹xlsx,xls elif(file_type=="xlsx" or file_type=="xls"): # 保存文件到指定路径 the_file.save("excel_example/" + the_file.filename) file_size=os.path.getsize("excel_example/"+the_file.filename) # 记录文件基本信息 if (flag_came == 0): fileroot.file_root(file_name,file_time,file_type,""+hum_convert(file_size),user_id)#记录文件基本信息 fileroot.file_update_state(file_name, "已上传") print("文件类型:" + file_type + ",文件大小:" +""+hum_convert(file_size)+ ",上传时间:" + file_time + ",文件名:" + file_name+",上传用户:"+user_id) # 将文件存入数据库 flag = connectsql.read_example(the_file.filename,china_row_flag,english_row_flag,unit_row_flag,type_flag) # 修改状态 fileroot.file_update_state(file_name, "已导入数据库") #word_data文件夹docx,doc elif(file_type=="docx" or file_type=="doc"): # 保存文件到指定路径 the_file.save("word_data/" + the_file.filename) file_size=os.path.getsize("word_data/"+the_file.filename) # 记录文件基本信息 fileroot.file_root(file_name,file_time,file_type,""+hum_convert(file_size),user_id)#记录文件基本信息 fileroot.file_update_state(file_name, "已上传") print("文件类型:" + file_type + ",文件大小:" +""+hum_convert(file_size)+ ",上传时间:" + file_time + ",文件名:" + file_name+",上传用户:"+user_id) else: # 保存文件到指定路径 the_file.save("test_data/" + the_file.filename) file_size=os.path.getsize("test_data/"+the_file.filename) # 记录文件基本信息 fileroot.file_root(file_name,file_time,file_type,""+hum_convert(file_size),user_id)#记录文件基本信息 fileroot.file_update_state(file_name, "已上传") print("文件类型:" + file_type + ",文件大小:" +""+hum_convert(file_size)+ ",上传时间:" + file_time + ",文件名:" + file_name) return jsonify({"code": 2, "msg": "", "data": ""}) if(flag==1): print("导入成功") if(flag_came==0): return jsonify({"code": 1, "msg": "", "data": ""}) else: print("相同文件上传") print(fileroot.find_filedata_filename(file_name)) if (type_0 == "0"): return jsonify({"code": 3, "msg": "", "data": ""}) else: return jsonify({"code": 4, "msg": "", "data": ""}) else: print("导入失败") return jsonify({"code": -1, "msg": "", "data": ""})
#读取样表生成数据字典type_flag 1 追加,2 覆盖 def read_example(path,china_row,english_row,unit_row,type_flag): flag=1 conn, cursor = get_conn_mysql() #将excel转换为csv文件 data = pd.read_excel('excel_example/'+path, 'Sheet1') data.fillna('', inplace=True) print(data) csv_name = path.split(".")[0] # data.to_csv("excel_data/"+csv_name+'.csv', encoding='utf-8') # data_csv=pd.read_csv("excel_data/"+csv_name+".csv") # 编写表创建语句(字段类型就设为string) # 表名 table_name = path.split(".")[0] ###################################################### #获取数据三种情况各自为keys if(china_row=="1"): key_china = data.keys() key_0 = data.values.tolist()[(int)(english_row)-2] key_unit=data.values.tolist()[(int)(unit_row)-2] if(english_row=="1"): key_china = data.values.tolist()[(int)(china_row)-2] key_0 = data.keys() key_unit=data.values.tolist()[(int)(unit_row)-2] if(unit_row=="1"): key_china = data.values.tolist()[(int)(china_row)-2] key_0 = data.values.tolist()[(int)(english_row)-2] key_unit=data.keys() key="" for i in key_0: key=key+","+i key=key[1:] if (type_flag=="0"): delete_sql = "drop table " + csv_name try: cursor.execute(delete_sql) except: traceback.print_exc() flag = 0 print("表删除失败") #建表及插入数据 sql = "CREATE TABLE IF NOT EXISTS " + csv_name + " (" # 循环加入key值 j=0 for i in key_0: sql = sql + i + " VARCHAR(45) NOT NULL DEFAULT '#' comment '"+key_china[j]+","+key_unit[j]+"'," j=j+1; creat_sql = sql[0:-1] + ") ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 COLLATE = utf8_bin;" print(creat_sql) # 获取%s s = ','.join(['%s' for _ in range(len(data.columns))]) # 获取values values=[] for i in data.values.tolist()[2:]: values.append(i) print(values) # 组装insert语句 insert_sql = 'insert into {}({}) values({})'.format(table_name, key, s) print(insert_sql) # print(key_china)#中文字段名 # print(key_unit)#中文单位 # print(key)#英文字段名 # print(values)#数据 #创建表 try: cursor.execute(creat_sql) except: traceback.print_exc() flag=0 print("表创建失败") # 插入数据 try: for i in values: cursor.execute(insert_sql, i) print(insert_sql) print(i) conn.commit() except: traceback.print_exc() flag=0 print("写入错误") close_conn_mysql(cursor, conn) return flag