1.AC3 encode overview
AC3 encoder的框图如下:
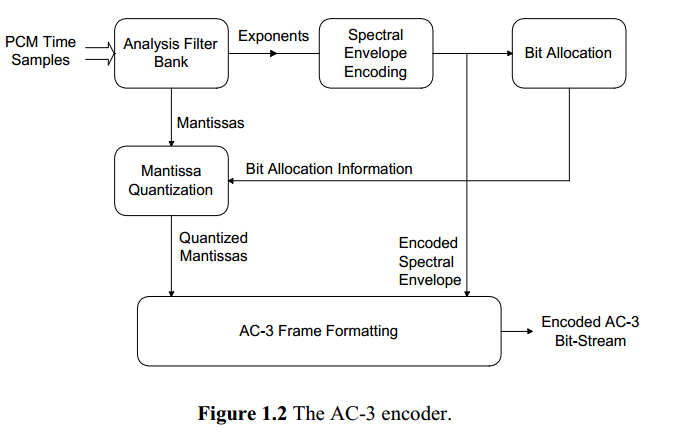
AC3在频域采用粗量化(coarsely quantizing)来获取较高的压缩率。
1).输入PCM 经过MDCT变换到频域,将时域信号转换成频率系数。512个sample 转换成256个频率系数。
2).将每个频率系数表示成二进制的指数(exponent)和尾数(mantissa)形式. exponent代表频率系数的envelop。
3).使用envelop来决定mantissa需要多少bit数来encode
4).6个audioblock (1536 sample)的envelop和mantissa加上header(SI,BSI)和CRC formatted成一个frame.如下:
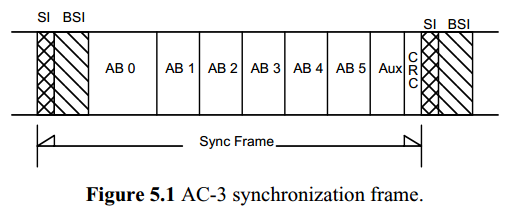
2.AC-3 encode算法overview:
1). exponent coding.
AC-3 bitstream主要包含原始信号的频率系数,频率系数由exponent和mantissa组成。
frequece_coefficient [k] = mantissa[k] >> exponent[k] = mantissa[k]*2^(-exponent[k]).
exponent 是frequence confficient中leading zero 的个数,主要描述频谱的evelop.
exponent采用差分编码, 并非所有的exponent都需要编码,而是可以通过不同的exponent strategy,将多个exponent组成group,用一个group value来表示多个exponent,达到更高的压缩率。
2). Bit allocation
Bit allocation通过人耳masking curve分析音频信号的频率系数的envelop,来确定mantissa需要多少bit 来encode。
3).Coulping
人耳对高频信号相位不敏感的特性,对高频部分采用coupling来由各个channel的高频部分产生coupling channel, coupling channel中包含各个channel的平均频率系数,每个coupled channel的高频部分不压缩,只保留各自的一组coupling coordinates 用以还原出原始channel的频率系数。
4).Rematrix
当两个channel 的信号有很大的相似性(highly correlated)时,rematrix技术并不压缩两个channel的原始信息,而是压缩两个channel的和与差。
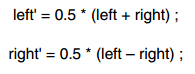
quantization 和data packing都是基于left'和right'.如果left/right很相似的话,right'就几乎为0,那可以使用更少的bit进行压缩。
5).MDCT
采用MDCT进行时频转换,x[n]为时域信号,采用long window时N为512,short window时N为256.
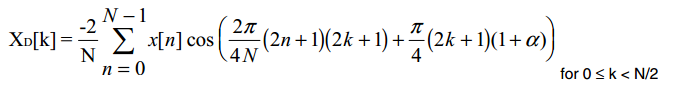

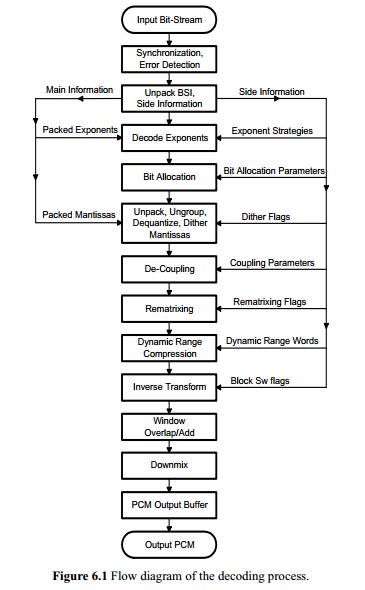
3.AC-3 decode overview.
decode 流程如下:
1)dialog norm
当音频来源于不同的source,在平台端接收到音频信号时会有很明显的loudness变化。比如说movie和广告间切换,不同电视频道的切换,节目的loudness会变化较大。
AC-3使用dialog normalization来标识当前bitstream的loudness.
dianorm存在于BSI信息中,占用5个bit,范围为1~31 db,标识当前bitstream中正常人声对话的level。
AC-3 decoder并不直接使用dianorm. 接收音频信号的平台端的音量调节系统会利用dianorm来调节音量。
通常音量调节系统会根据用户的输入来使得平台达到期望的loundess或者SPL(sound pressure level),调节系统的gain来达到用户期望的音量.
但是如果是AC-3 bitstream, 系统的gain值与用户期望的dialog 的SPL和bitstream中dianorm同时相关联。
例如,如果用户想要调节音量(节目中dialog level)达到67 db SPL(利用dianorm,对任何source的AC-3 bitstream,音量调节系统都能达到准确的SPL),
当播放一个high quality的娱乐节目时,dianorm为25 db。调节系统的gain值使得full scale signal(信号的最大level)达到92 db SPL (92 - 25 =67 db).
当播放一个广告节目时,dianorm为15db,调节系统的gain值使得100%的digital level (信号最大level)达到82 db SPL,那么广告中的dialog 的level为82-15 = 67 db SPL.
2)DRC
一个high quality的节目(比如film),通常音频会由wide dynamic range 的声音mix在一起。以dialog level 作为reference,爆炸声比dialog level高20db以上,风吹动树叶的声音比dialog level低50db以上。
在大部分听众而言,如果声音非常大,会有不好的听觉体验。而听众会想要听到非常微弱的声音,所以需要将loudest sound做compress downward,而quiet sound做bring upward.那么wide dynamic range 将会被compress.
AC-3 coding技术将dynamic range control value(dynrng)压到bitstream中,使得听众获得更好的听觉体验。AC-3 encoder产生一系列的dynrng,每个dynrng在decoder端用于一个或多个audio block作为gain来进行DRC.
对于听众来说,希望将loudest信号往dialog level方向往下调,而quiet信号往dialog level方向向上调。而对于那些与dialog level具有相同loudness的信号不做调节。
例如:对于一部电影,dialog level为-25 db,爆炸声达到0db,微弱的声音低于dialog level 50 db为-75db. AC-3 encoder将产生一组dynrng, audio level高于dialog level时, dynrng 标识负的gain. audio level低于dialog level时, dynrng标识正的gain. 0db的信号,对应dynrng标识降低15db。微弱的声音dynrng标识增加20db。
当用户想要听到所有的声音,并且希望不影响到其他人,AC-3 decoder可以使用默认的full compression方式做DRC。当用户将dialog level调节到 60 db SPL时,爆炸声为70 db SPL(本来是高于dialog level 25 db(80db SPL),但是dynrng降低15 db).微弱的声音为30 db SPL(本来是低于dialog level 50 db (10 db SPL), 但是dynrng提高20 db).那么原本的dynamic range变为70-30 = 40 db。
3)downmix
在解码的平台端,通常speaker的数目与bitstream的channel并不匹配。比如说bitstream是5.1 ch,但是平台只有两个speaker.这时候需要做downmix.
5.1 ch到2ch 做LoRo downmix:
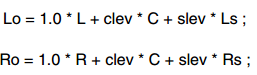
clev 和slev是由BSI信息中的cmixlev和surmixlev字段标识的downmix 系数。
为了防止downmix 后信号的overflow,实际的downmix系数需要乘以一个scale.例如:clev和slev都是0.707时,每个downmix 系数需要乘以1/(1+0.707+0.707)=0.4143
4 ch到2ch做LoRo downmix
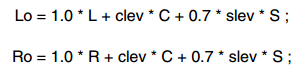
5.1 ch到2ch做LtRt downmix:
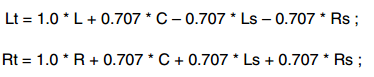
为了防止overflow, downmix系数都需要乘以1/(1+0.707+0.707+0.707)=0.3204
4ch到2ch做LtRt downmix:
