在AAC编码器内部,使用huffman coding用于进一步减少scalefactor和量化频谱系数的冗余。
从individual_channel_stream层提取码流进行huffman解码,码流信息包括解码量化频谱数据部分(global_gain,section_data(),section_scalefactor(),spectra_data())和解码脉冲数据部分(pulse_data_present, pulse_data())。
global_gain编码成一个8位的无符号整数,第一个scalefactor与global_gain进行差分编码后再使用scalfactor codebook进行huffman编码。后续的各scalefactor都与前一个scalfactor进行差分编码。
量化频谱系数来自码流中spectral_data()。AAC的huffman编码算法对量化频谱系数有两步分组处理.如上所述,第一步分组是分出scalefactor band中的量化频谱系数个数是4的倍数.目的是进行4个量化频谱系数一起编码.第二步分割是标准中把1个或几个scalefactor band合并成一个section.同一个section内的所有scalefactor band的谱线使用同一个huffman码表.所以,如果要进行huffman解码,section的宽度信息和码本号作为side information附加在section data中传输.解码端要先解出这些信息才能进行huffman解码.而section的长度小于scalefactor band的个数而大于scalefactor windows band的个数. 为了最大限度的匹配量化谱线的统计特性,Huffman为了使量化频谱系数的统计特性最大化的匹配huffman码本,section的数量允许和scalefactor band的数量一样大. Section个数的最大值是max_sfb.但注意section的边界要与scalefactor band的边界重合. 用huffman编码的4个一组的量化频谱系数和2个一组量化频谱系数的传送顺序是从低频系数到高频系数. 对于每个frame有多个windows的情况,要注意有分组和交织情况,系数的集合需要解交织,
量化频谱系数存储在数组x_quant[g][win][sfb][bin]。

对于4个一组的量化频谱系数(w,x,y,z):
x_quant[g][win][sfb][bin]=w;
x_quant[g][win][sfb][bin + 1]=x;
x_quant[g][win][sfb][bin + 2]=y
x_quant[g][win][sfb][bin + 3]=z;
AAC的huffman解码一共有15个码本(codebook),除了一个码本专用于scalefactor解码.11个码本用于量化频谱系数的解码.1个码本表示传输的系数全位零,是0码本,不需解码.2个码本是intensity码本,也是0码本.在为量化频谱系数解码的11个码本中,每个码本有自己可以编码的最大量化量化频谱系数的绝对值,用LAV表示. 用于量化频谱系数的解码的11个码本中最后一个码本可以解码出谱线系数的最大值是16.但当解码出谱线系数的值大于0小于16的时候.解码出的值就是实际的量化频谱系数的绝对值,当解码锄地谱线系数是16时,表示退出huffman解码,使用其他方式解码.所以在该码本中解码出的值16被定义成ESC_FLAG.unsigned_cb[i]标志位表示该码本是有符号码本还是无符号码本,unsigned_cb[i]=0时表示该码本是有符号码本, unsigned_cb[i]=1时表示该码本是无符号码本.解码有符号数时,先按照无符号解码再从输入的解码比特流中提取符号位,若解码出的量化频谱系数非零,则其符号位紧跟在被该量化频谱系数的码字(codeword)的后面。
Codebook Number,i:码本的索引,即码流中sect_cb值。
unsigned_cb[i]:表示码本i是有符号码本还是无符号码本。
Dimension of Codebook:即4个一组量化频谱系数还是2个一组。
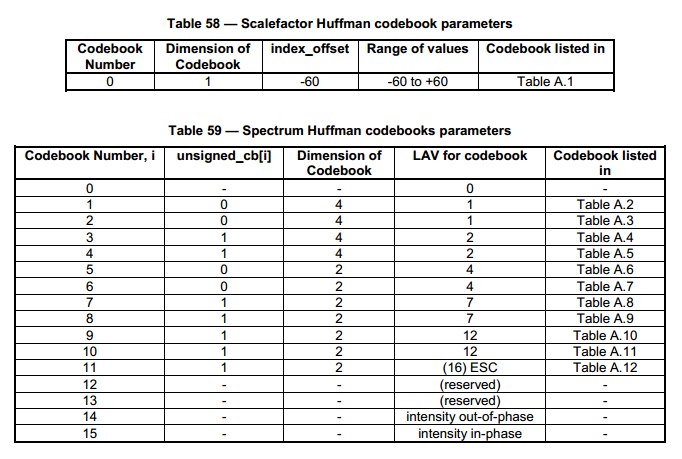
Table A.1~12为huffman codebook,下面只给出TableA.2示例:(length为codeword的bit数)
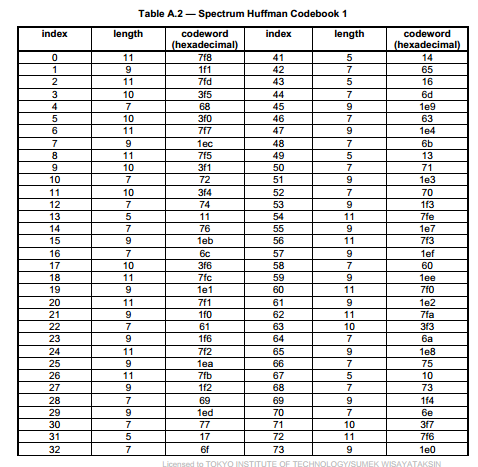
Huffman解码就是从spectral_data中读出huffman codeword,然后在对应的huffman codebook中查找出codeword所对应的index,根据index计算出4/2个量化频谱系数。每个量化频谱系数对应一个频率,最后通过量化频谱数据查找出对应的频率,最终乘以scalefactor得到真正的频率数据。
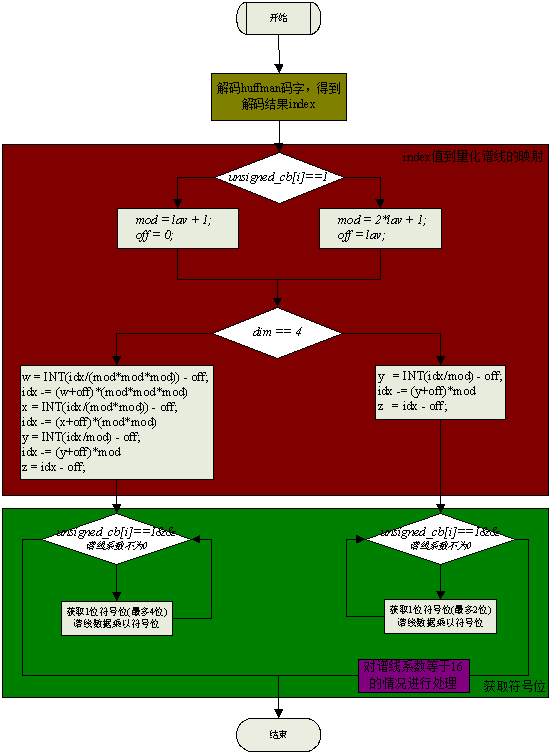
index到4个量化频谱系数的计算方法如下:

如果huffman codebook是unsigned的,那么需要huffman解码完成index到量化频谱系数的映射后,根据spectral_data()查找到codeword的紧接着的0~2个bit,来加上符号。
例如,hcod[7][y][z]表示第7个codebook的频谱系数(y,z)对应的codeword
紧接着的为0~2bits为pair_sign_bits,
那完成index到(y,z)的映射后,做如下处理:

huffman 解码流程图如下:
参考:
http://www.cnblogs.com/gaozehua/archive/2012/05/15/2500864.html
;