传统的日志查看方式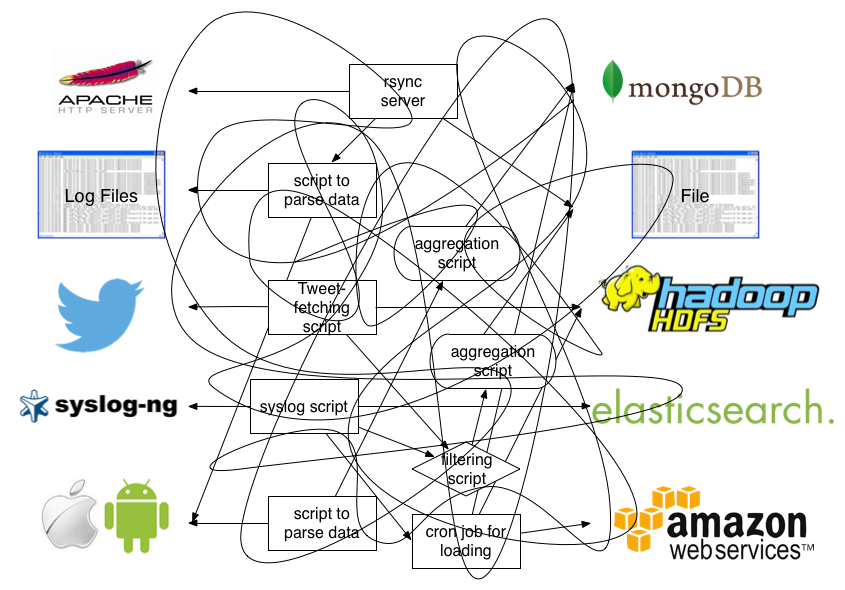
使用fluentd之后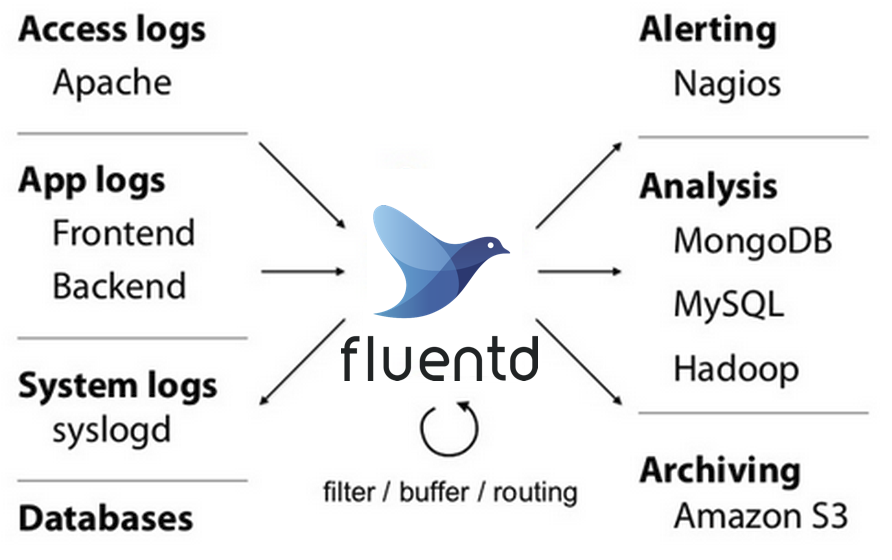
一、介绍
Fluentd是一个开源的数据收集器,可以统一对数据收集和消费,以便更好地使用和理解数据。
几大特色:
使用JSON统一记录
简单灵活可插拔架构
最小的资源需求
内置可靠性
1. JSON统一记录
Fluentd尽可能地将数据结构转化为JSON格式,这样可以使Fluentd统一处理日志数据的各个方面:收集,过滤,缓冲和输出多个源和目的地(Unified Logging Layer)的日志。JSON格式对于下游数据处理容易得多,因为它具有足够的结构可访问,同时保留灵活的模式。(在我们的日志集群架构中,fluentd担任了一个转发者角色。)
2. 可插拔架构
Fluentd有一个灵活的插件系统,允许社区扩展其功能。社区提供了500多个的插件连接数十个data sources 和 data outputs,利用这些插件,我们可以更好的处理日志消息流。
3. 最小的资源需求
Fluentd是用C语言和Ruby语言编写的,需要很少的系统资源。一个运行实例 使用30-40MB的内存,可以处理13,000个事件/秒/核心。Fluentd以Ruby编写,具有灵活性,性能敏感部分用C编写。(另外Fluentd还有一个mini版本叫Fluent Bit io。程序只有几十kb的大小,由于暂不支持输出消息到kafka。所以暂未考虑使用。)
4. 内置可靠性
Fluentd支持基于内存和文件的缓冲(推荐配置文件中可添加buffer选项为file/production、memory/test),以防止节点间数据丢失。Fluentd还支持强大的故障切换功能(standby),可以设置高可用性。
二、插件介绍
Fluentd有6种类型的插件:input,Parser,Filter,Output,Formatter和Buffer。
1. Input Plugins
概述:Fluentd从外部来源检索和拉取日志事件,input 插件通常会创建一个线程socket和一个监听socket,它也可以从被定期写入的数据源中提取数据(如tail file_name)。
支持的input插件列表:
in_udp
in_tcp
in_forward
in_secure_forward
in_http
in_unix
in_tail
in_exec
in_syslog
in_scribe
in_multiprocess
in_dummy2. Output Plugins
概述:输出插件又可分为三种类型:非缓冲、缓冲和时间切片(time sliced)
Non-Buffered 输出插件不会缓冲数据并立即写出结果
Buffered 输出插件维护一个队列(一个chunk是一个事件的集合),并且它的行为可以通过“chunk limit” 和 “queue limit”参数进行调整
Time Sliced 输出插件实际上是一种Bufferred插件,但是这些块是按时间键入的
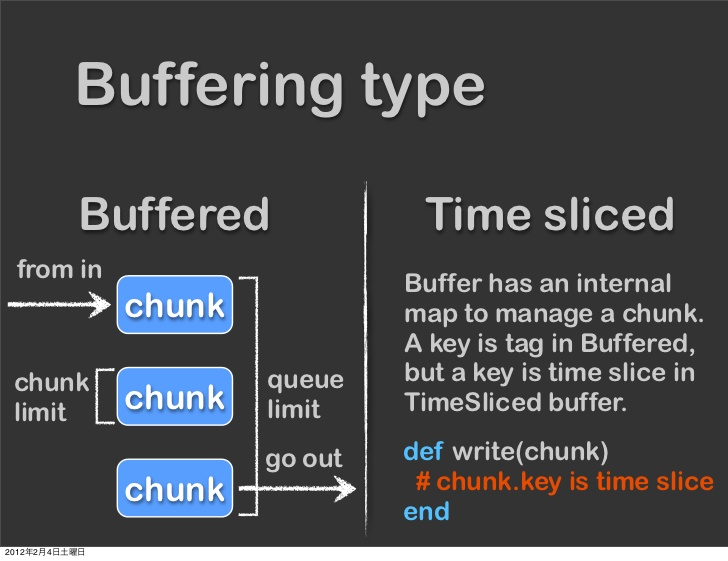
输出插件的缓冲区行为(如果有),可以由一个单独的缓冲区插件定义。即为每个输出插件可以选择不同的缓冲区插件。有一些输出插件是完全定制的,不要使用缓冲区。
Non-Buffered 输出插件列表
out_copy
out_null
out_roundrobin
out_stdoutBuffered 输出插件列表
out_exec_filter
out_forward
out_mongo or out_mongo_replsetTime Sliced 输出插件列表(我们用到了kafka)
out_splunk
out_file
out_forward
out_secure_forward
out_exec
out_exec_filter
out_copy
out_geoip
out_roundrobin
out_stdout
out_null
out_s3
out_splunk
out_kafka
out_mongo
out_mongo_replset
out_relabel
out_rewrite_tag_filter
out_webhdfs3. Buffer Plugins
概述:Buffer plugins 被缓冲输出插件使用,如 out_file, out_forward等等。用户可以选择最适合系统架构性能和可靠性需求的缓冲区插件。
Buffer 结构
queue
+---------+
| |
| chunk <-- write events to the top chunk
| |
| chunk |
| |
| chunk |
| |
| chunk --> write out the bottom chunk
| |
+---------+如上面所示,当顶部块超过指定的大小或时间限制时(分别为buffer_chunk_limit 和 flush_interval),一个新的空块将被推到队列的顶部。当新的块被推出时,底部块被立即写出。
如果底部的块未能写出,它将保留在队列中,并且Fluentd将在等待几秒钟后重试(等待时间,根据retry_wait参数设置)。如果重试限制尚未禁用(disable_retry_limit is false),并且重试次数超过指定的限制(retry_limit),这个块将被删除。每次重试等待时间加倍(1.0秒, 2.0秒, 4.0秒, …),直到达到max_retry_wait。如果队列长度超过指定的限制(buffer_queue_limit),则新事件将被拒绝。
所有的缓冲输出插件都支持以下参数:
<match pattern>
# omit the part about @type and other output parameters
buffer_type memory
buffer_chunk_limit 256m
buffer_queue_limit 128
flush_interval 60s
disable_retry_limit false
retry_limit 17
retry_wait 1s
max_retry_wait 10s # default is infinite
</match>buffer_type指定要使用的缓冲区插件,默认情况下使用内存缓冲区插件。您还可以将缓冲区类型指定为file,使用buffer_path指定file路径. 生产环境建议使用file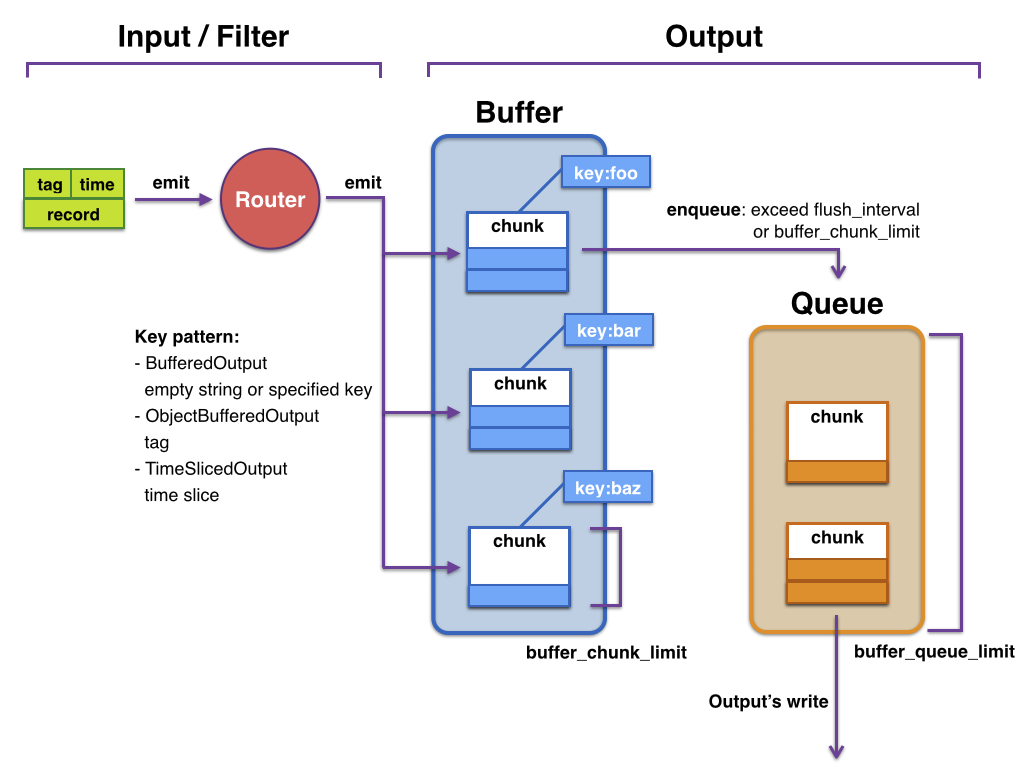
Secondary output:当重试计数超过retry_limit时就使用备份的目的地。目前,当primary 插件类型为file 插件时可以工作。这是很有用的,当primary 目的地或网络条件不稳定时。相当于B方案。
buff 可用的插件列表
buf_memory
buf_file4. Filter Plugins
概述:Filter插件使Fluentd 可以修改事件流,例如下面的场景:
- 通过刷新一个或多个字段的值来过滤事件。
- 通过添加新的字段丰富事件。
- 删除或屏蔽某些字段的隐私和合规性。
拓展:“脱敏”
<filter foo.bar>
@type grep
regexp1 message cool
</filter>上面的意思就是:将事件与tag(标签)为“foo.bar”进行匹配,并且如果message字段的值包含 cool,则事件将通过其余的配置。
像output插件中的指令一样,对标签进行匹配。一旦事件被filter处理,事件将从上到下进行配置,因此,如果同一个标签有多个过滤器,则按降序应用。通过下面的例子看下:
<filter foo.bar>
@type grep
regexp1 message cool
</filter>
<filter foo.bar>
@type record_transformer
<record>
hostname "#{Socket.gethostname}"
</record>
</filter>一旦messages 字段中有包含cool 的事件,将会继续匹配。将以机器的主机名作为其值来获取新字段“hostname”。
filter 过滤插件可用的列表
grep
record-transformer
filter_stdout5. Parser Plugins
概述:有时,用于输入插件的 format 参数(如:in_tail,in_syslog,in_tcp 和 in_udp)无法解析用户的自定义数据格式.(例如,上下文相关语法不能用正则表达式来解析)。为了解决这种情况,Fluentd有一个可插拔系统,使用户能够创建自己的解析器格式。
内置的Parsers 列表
regexp
apache2
apache_error
nginx
syslog
csv
tsv
ltsv
json
multiline
none支持使用Parsers 核心的Input plugins 列表(带 format参数的)
in_tail
in_tcp
in_udp
in_syslog
in_http6. Formatter Plugins
概述:有时,输出插件的输出格式不能满足自己的需要。Fluentd有一个名为Text Formatter的可插拔系统,使用户可以扩展和重新使用自定义的输出格式。
对于支持Text Formatter的输出插件,format参数可用于更改输出格式。
内置Formatters列表
out_file
json
ltsv
csv
msgpack
hash
single_value支持文本格式化程序支持的输出插件列表(很遗憾,暂不支持kafka)
out_file
out_s3三、生产环境的建议
1. high-availability
高可用配置参考链接:http://docs.fluentd.org/v0.12/articles/high-availability
2. performance-tuning
性能优化配置参考链接:http://docs.fluentd.org/v0.12/articles/performance-tuning
本文原文出自飞走不可,如有转载,还请注明出处,如 飞走不可:http://www.cnblogs.com/hanyifeng/p/7260327.html