本文主要讲解如下内容:
- 为什么要使用分布式锁?
- 分布式锁特性!
- 分布式锁的实现方式有哪些?
- Curator分布式锁原理
- Curator分布式锁实现类UML及相关类的介绍
- 基于Redis,数据库实现分布式锁
为什么要使用分布式锁?
在传统的单机应用中,我们使用JAVA提供的synchronized、ReentrantLock、Semaphore、AtomicInteger等解决多线程并发问题,达到同步目的。单机应用所有的请求都会分配到当前服务器的JVM内部,线程间是可以共享某一个变量的。当随着业务的发展,单机演变成集群,一个JVM扩展到多个甚至数十个JVM的时候,就不能共享同一变量了。如下图所示:

上图中同样的业务部署在多台服务器上,但是又要操作同一个数据的时候,JAVA的synchronized等关键字也就无力回天了,这是分布式锁正式登场。
分布式锁特性!
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
分布式锁的实现方式有哪些?
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。
|
1
2
3
|
基于数据库实现分布式锁;基于缓存(Redis等)实现分布式锁;基于Zookeeper实现分布式锁; |
这三种方案之间没有最好只有更适合,具体要看业务场景
Curator分布式锁原理
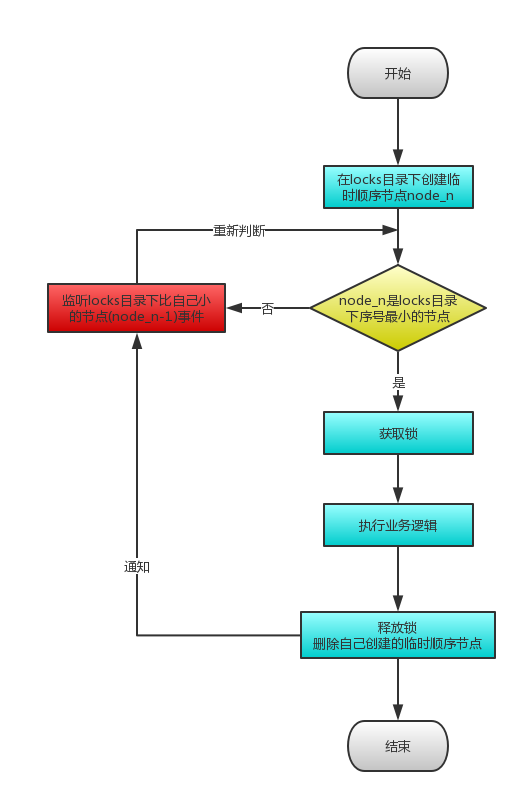
注意:判断自己是否是locks目录下序号最小的节点,只会和比自己序号小的那个相邻节点进行比较,这样大大提高了效率。比如N节点只会和N-1几点比较,不会和N+1,N-2节点比较。
另外zookeeper有效解决了下面的问题(重点重点重点):
锁释放:
使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
阻塞锁
使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
可重入锁
使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
单点问题
使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
Curator分布式锁实现类UML及相关类的介绍

接口InterProcessLock作为神一般的存在,其它类均实现了这个接口。
看一下这个接口定义
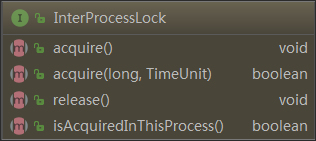
接口中定义了四个方法:
public void acquire();//获取锁
public boolean acquire(long time, TimeUnit unit);//获取锁,可以指定阻塞时间
public void release();//释放锁
boolean isAcquiredInThisProcess();//判断当前是否持有锁,实际使用中,如果持有锁,可以进行锁的释放。
实现类:
InterProcessMultiLock 将多个锁作为单个实体管理的容器
InterProcessMutex 分布式可重入排它锁
InterProcessReadWriteLock 分布式读写锁
InterProcessSemaphoreMutex 分布式排它锁
InterProcessSemaphoreV2 信号量
基于Redis,数据库实现分布式锁
基于redis和数据库实现的分布式锁大家可以参考以下文章: