案例功能说明
通过socketTextStream读取9999端口数据,统计在一定时间内不同类型商品的销售总额度,如果持续销售额度为0,则执行定时器通知老板,是不是卖某种类型商品的员工偷懒了(只做功能演示,根据个人业务来使用,比如统计UV等操作)。
ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块: 1.事件(event)(流元素)。 2.状态(state)(容错性,一致性,仅在keyed stream中)。 3.定时器(timers)(event time和processing time, 仅在keyed stream中)。
案例代码
使用ValueState记录了状态信息,每次来商品都会进行总额度累加。
商品第一次进入的时候会注册一个定时器,每隔10秒执行一次,定时器做预警功能,如果十秒内商品销售等于0,我们则进行预警。


import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.common.typeinfo.TypeInformation import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.api.scala.typeutils.Types import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.scala._ import org.apache.flink.util.Collector object ProcessFuncationScala { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[String] = env.socketTextStream("localhost", 9999) val typeAndData: DataStream[(String, String)] = stream.map(x => (x.split(",")(0), x.split(",")(1))).setParallelism(4) typeAndData.keyBy(0).process(new MyprocessFunction()).print("结果") env.execute() } /** * 实现: * 根据key分类,统计每个key进来的数据量,定期统计数量,如果数量为0则预警 */ class MyprocessFunction extends KeyedProcessFunction[Tuple,(String,String),String]{ //统计间隔时间 val delayTime : Long = 1000 * 10 lazy val state : ValueState[(String,Long)] = getRuntimeContext.getState[(String,Long)](new ValueStateDescriptor[(String, Long)]("cjcount",classOf[Tuple2[String,Long]])) override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Tuple, (String, String), String]#OnTimerContext, out: Collector[String]): Unit = { printf("定时器触发,时间为:%d,状态为:%s,key为:%s ",timestamp,state.value(),ctx.getCurrentKey) if(state.value()._2==0){ //该时间段数据为0,进行预警 printf("类型为:%s,数据为0,预警 ",state.value()._1) } //定期数据统计完成后,清零 state.update(state.value()._1,0) //再次注册定时器执行 val currentTime: Long = ctx.timerService().currentProcessingTime() ctx.timerService().registerProcessingTimeTimer(currentTime + delayTime) } override def processElement(value: (String, String), ctx: KeyedProcessFunction[Tuple, (String, String), String]#Context, out: Collector[String]): Unit = { printf("状态值:%s,state是否为空:%s ",state.value(),(state.value()==null)) if(state.value() == null){ //获取时间 val currentTime: Long = ctx.timerService().currentProcessingTime() //注册定时器十秒后触发 ctx.timerService().registerProcessingTimeTimer(currentTime + delayTime) printf("定时器注册时间:%d ",currentTime+10000L) state.update(value._1,value._2.toInt) } else{ //统计数据 val key: String = state.value()._1 var count: Long = state.value()._2 count += value._2.toInt //更新state值 state.update((key,count)) } println(getRuntimeContext.getTaskNameWithSubtasks+"->"+value) printf("状态值:%s ",state.value()) //返回处理后结果 out.collect("处理后返回数据->"+value) } } }
案例测试
10秒内输入四条数据
帽子,12 帽子,12 鞋,10 鞋,10
通过我们打印我们会发现统计完成
定时器触发,时间为:1586005420511,状态为:(鞋,20),key为:(鞋)
定时器触发,时间为:1586005421080,状态为:(帽子,24),key为:(帽子)
如果我们10秒内不输入数据,则会提示数据为0,进行预警
定时器触发,时间为:1586005406244,状态为:(帽子,0),key为:(帽子) 类型为:帽子,数据为0,预警 定时器触发,时间为:1586005406244,状态为:(鞋,0),key为:(鞋) 类型为:鞋,数据为0,预警
数据倾斜问题
到这里我们已经实现了定期统计功能,但有没有发现,如果帽子分配在task1执行,鞋在task2执行,鞋一天进来1亿条数据,帽子进来1条数据,我们会出现严重的数据倾斜问题。
我们实际看一下具体问题,计算结果我们就先不看了,直接看数据分配问题
三个task阶段 , Socket是单并行的source,我们将并行度改为4

输入数据:1条 帽子,10 ;50条 鞋,10
我们看Map阶段,数据是均衡的,因为这里还没有进行keyby
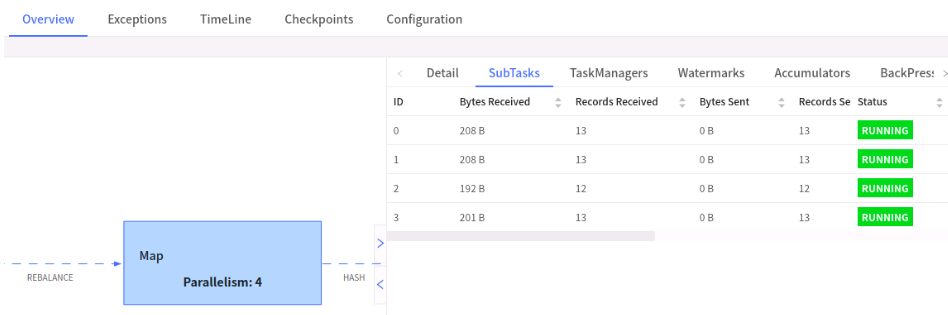
我们再看keyby后的task
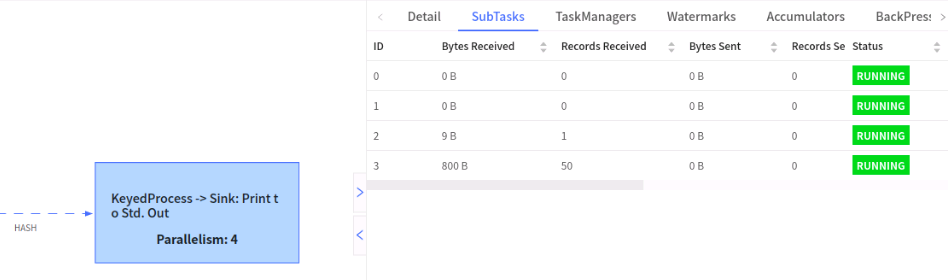
我们发现50条数据都在ID为3的subtask中,出现了严重数据倾斜问题。
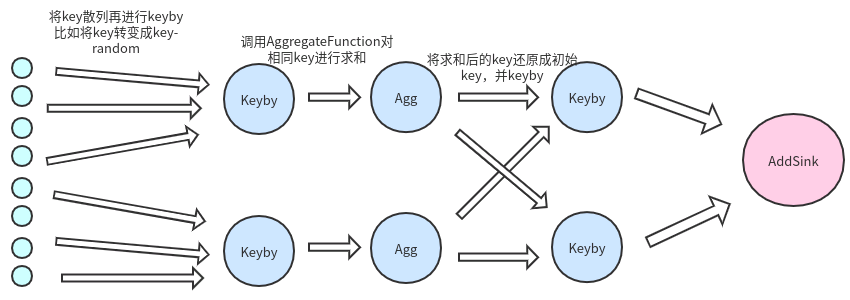
这种问题我们可以进行两阶段keyby解决该问题。
两阶段keyby方法
数据倾斜如左图所示。而我们期望的是如右图所示。
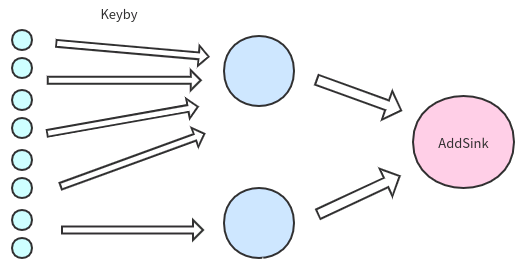
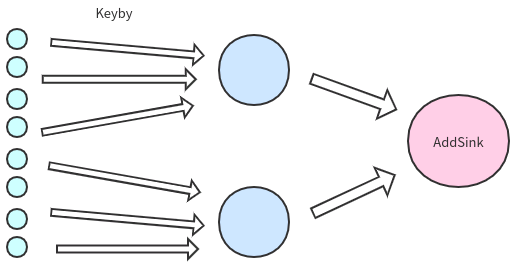
但我们的需要根据key进行聚合统计,那么把相同的key放在不同的subtask如何统计?
1.首先将key打散,我们加入将key转化为 key-随机数 ,保证数据散列 2.对打散后的数据进行聚合统计,这时我们会得到数据比如 : (key1-12,1),(key1-13,19),(key1-1,20),(key2-123,11),(key2-123,10) 3.将散列key还原成我们之前传入的key,这时我们的到数据是聚合统计后的结果,不是最初的原数据 4.二次keyby进行结果统计,输出到addSink
打散key代码实现
import org.apache.flink.api.common.functions.AggregateFunction import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.api.scala.typeutils.Types import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.functions.windowing.WindowFunction import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector object ProcessFunctionScalaV2 { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.enableCheckpointing(2000) val stream: DataStream[String] = env.socketTextStream("localhost", 9999) val typeAndData: DataStream[(String, Long)] = stream.map(x => (x.split(",")(0), x.split(",")(1).toLong)) val dataStream: DataStream[(String, Long)] = typeAndData .map(x => (x._1 + "-" + scala.util.Random.nextInt(100), x._2)) val keyByAgg: DataStream[DataJast] = dataStream.keyBy(_._1) .timeWindow(Time.seconds(10)) .aggregate(new CountAggregate()) keyByAgg.print("第一次keyby输出") val result: DataStream[DataJast] = keyByAgg.map(data => { val newKey: String = data.key.substring(0, data.key.indexOf("-")) println(newKey) DataJast(newKey, data.count) }).keyBy(_.key) .process(new MyProcessFunction()) result.print("第二次keyby输出") env.execute() } case class DataJast(key :String,count:Long) //计算keyby后,每个Window中的数据总和 class CountAggregate extends AggregateFunction[(String, Long),DataJast, DataJast] { override def createAccumulator(): DataJast = { println("初始化") DataJast(null,0) } override def add(value: (String, Long), accumulator: DataJast): DataJast = { if(accumulator.key==null){ printf("第一次加载,key:%s,value:%d ",value._1,value._2) DataJast(value._1,value._2) }else{ printf("数据累加,key:%s,value:%d ",value._1,accumulator.count+value._2) DataJast(value._1,accumulator.count + value._2) } } override def getResult(accumulator: DataJast): DataJast = { println("返回结果:"+accumulator) accumulator } override def merge(a: DataJast, b: DataJast): DataJast = { DataJast(a.key,a.count+b.count) } } /** * 实现: * 根据key分类,统计每个key进来的数据量,定期统计数量 */ class MyProcessFunction extends KeyedProcessFunction[String,DataJast,DataJast]{ val delayTime : Long = 1000L * 30 lazy val valueState:ValueState[Long] = getRuntimeContext.getState[Long](new ValueStateDescriptor[Long]("ccount",classOf[Long])) override def processElement(value: DataJast, ctx: KeyedProcessFunction[String, DataJast, DataJast]#Context, out: Collector[DataJast]): Unit = { if(valueState.value()==0){ valueState.update(value.count) printf("运行task:%s,第一次初始化数量:%s ",getRuntimeContext.getIndexOfThisSubtask,value.count) val currentTime: Long = ctx.timerService().currentProcessingTime() //注册定时器 ctx.timerService().registerProcessingTimeTimer(currentTime + delayTime) }else{ valueState.update(valueState.value()+value.count) printf("运行task:%s,更新统计结果:%s " ,getRuntimeContext.getIndexOfThisSubtask,valueState.value()) } } override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, DataJast, DataJast]#OnTimerContext, out: Collector[DataJast]): Unit = { //定时器执行,可加入业务操作 printf("运行task:%s,触发定时器,30秒内数据一共,key:%s,value:%s ",getRuntimeContext.getIndexOfThisSubtask,ctx.getCurrentKey,valueState.value()) //定时统计完成,初始化统计数据 valueState.update(0) //注册定时器 val currentTime: Long = ctx.timerService().currentProcessingTime() ctx.timerService().registerProcessingTimeTimer(currentTime + delayTime) } } }
对key进行散列
val dataStream: DataStream[(String, Long)] = typeAndData
.map(x => (x._1 + "-" + scala.util.Random.nextInt(100), x._2))
设置窗口滚动时间,每隔十秒统计一次每隔key下的数据总量
val keyByAgg: DataStream[DataJast] = dataStream.keyBy(_._1) .timeWindow(Time.seconds(10)) .aggregate(new AverageAggregate()) keyByAgg.print("第一次keyby输出")
还原key,并进行二次keyby,对数据总量进行累加
val result: DataStream[DataJast] = keyByAgg.map(data => { val newKey: String = data.key.substring(0, data.key.indexOf("-")) println(newKey) DataJast(newKey, data.count) }).keyBy(_.key) .process(new MyProcessFunction())
我们看下优化后的状态
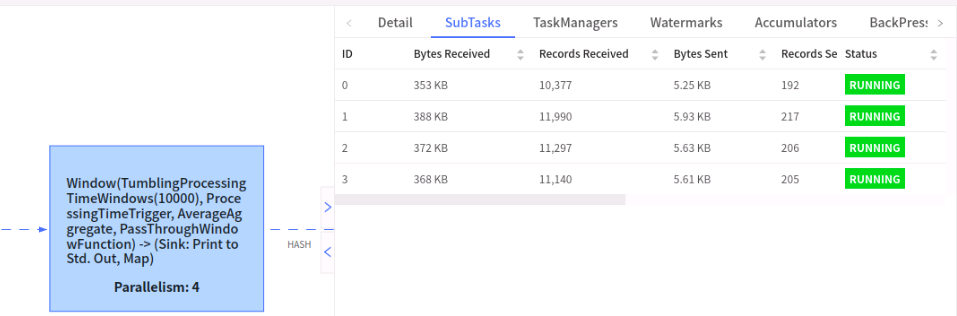
先看下第一map,直接从端口拿数据,这不涉及keyby,所以这个没影响

再看下第一次keyby后的结果,因为我们散列后,flink根据哈希进行分配,所以数据不是百分之百平均,但是很明显基本上已经均衡了,不会出现这里1一条,那里1条这种状况。
再看下第二次keyby,这里会发现我们ID的2的subtask有820条数据,其他的没有数据;这里是正常现象,因为我们是对第一次聚合后的数据进行keyby统计,所以这里的数据大小会非常小,比如我们原始数据一条数据有1M大小,1000条数据就1个G,业务往往还有其他操作,我们再第一次keyby 散列时处理其他逻辑(比如ETL等等操作),最终将统计结果输出给第二次keyby,很可能1个G的数据,最终只有1kb,这比我们将1个G的数据放在一个subtask中处理好很多。
上面我们自定义了MyProcessFunction方法,设置每30秒执行一次,实际业务场景,我们可能会设置一小时执行一次。
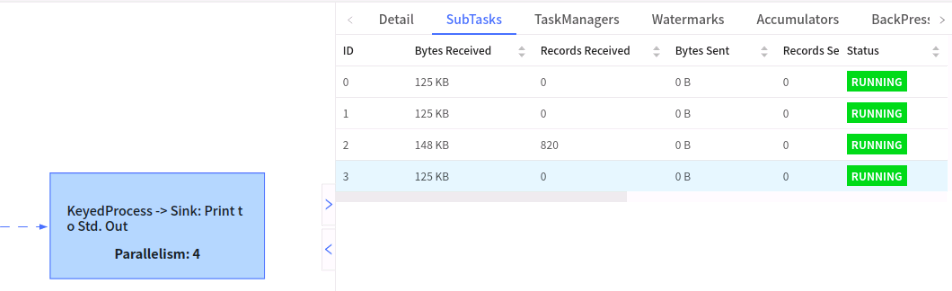
至此我们既保证了数据定时统计,也保证了数据不倾斜问题。
https://blog.csdn.net/zhangshenghang/article/details/105322423