前段时间做SEO的优化,使用的是GoogleChrome/rendertron,发现这个安装部署的时候还是会有一些要注意的地方,做个记录
为什么要使用rendertron
目前很多网站都是使用 vue、recat等框架开发的网站,一般都是在服务器上只有一个index.html,index.html引入JS,通过JS在客户端的浏览器上渲染出页面。
如果是搜索引擎的爬虫,它不像浏览器可以直接渲染,它只能拿到一段无意义的JS代码,这些代码对SEO的收录没有任何意义。
所以Google就做了rendertron。流程就变成这样了。
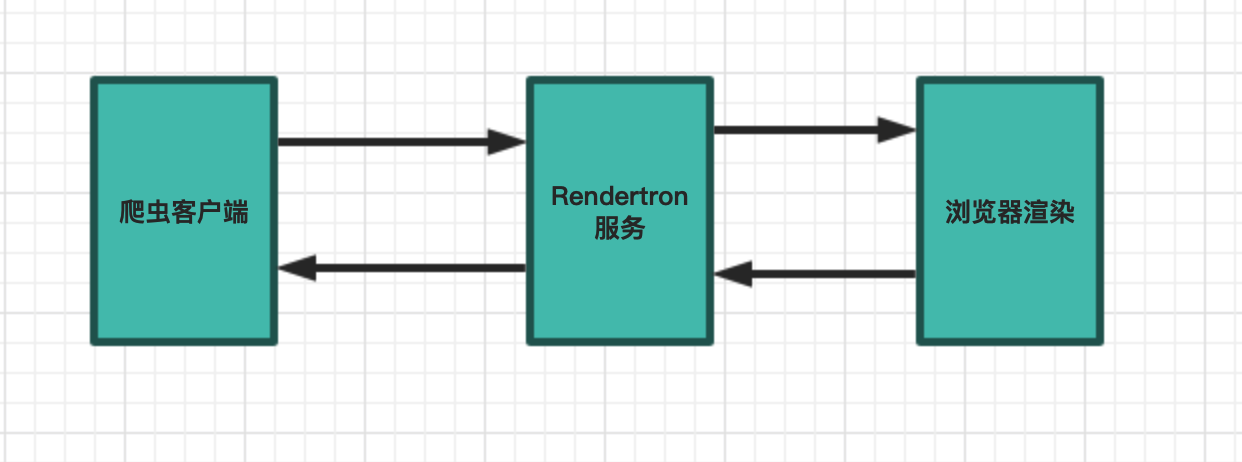
rendertron服务会调用Chromium浏览器,浏览器会将渲染结果返回给rendertron,然后rendertron会将结果返回给爬虫客户端
rendertron安装
安装流程
git clone https://github.com/GoogleChrome/rendertron.git
cd rendertron
npm install
安装的时候发现rendertron安装浏览器的时候,有时候由于墙的原因,有时候由于网络时长的问题,非常容易安装失败,所以需要忽略浏览器的安装,安装完rendertron的依赖之后再安装浏览器。
env PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true
npm install --loglevel verbose
安装完其他依赖之后再去安装浏览器。
先找到Chromium的版本
在以下文件中
node_modules/puppeteer/lib/esm/puppeteer/revisions.js
export const PUPPETEER_REVISIONS = {
chromium: '818858',
firefox: 'latest',
};
需要chromium 的版本号 818858
然后去 https://npm.taobao.org/mirrors/chromium-browser-snapshots/
下载现在相应的版本。
我的系统是centos,所以我下载的就是
https://npm.taobao.org/mirrors/chromium-browser-snapshots/Linux_x64/818858/chrome-linux.zip
下载完成之后解压,拷贝到相应系统的地址,我这边的地址就是这里
node_modules/puppeteer/.local-chromium/linux-818858/chrome-linux
win64的可能是这样的
node_modules/puppeteer/.local-chromium/win64-818858/chrome-win32
规则是这样的
node_modules/puppeteer/.local-chromium/系统-版本号/下载解压后的文件夹
这些都做完之后直接编译运行
npm run build
npm run start
具体的使用和安装可以看下官方的说明
https://github.com/GoogleChrome/rendertron
也可以先试用下网页版的
https://render-tron.appspot.com/