背景
前段时间在测试docker的网络性能的时候,发现了一个veth的性能问题,后来给docker官方提交了一个PR,参考set tx_queuelen to 0 when create veth device,引起了一些讨论。再后来,RedHat的网络专家Jesper Brouer 出来详细的讨论了一下这个问题。
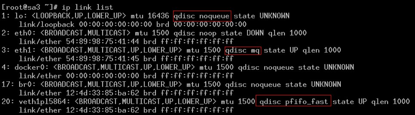
可以看到,veth设备qdisc队列,而环回设备/桥接设备是没qdisc队列的,参考br_dev_setup函数。
内核实现
在注册(创建)设备时,qdisc设置为noop_qdisc, register_netdevice -> dev_init_scheduler
void dev_init_scheduler(struct net_device *dev)
{
dev->qdisc = &noop_qdisc;
netdev_for_each_tx_queue(dev, dev_init_scheduler_queue, &noop_qdisc);
dev_init_scheduler_queue(dev, &dev->rx_queue, &noop_qdisc);
setup_timer(&dev->watchdog_timer, dev_watchdog, (unsigned long)dev);
}
打开设备时,如果没有配置qdisc时,就指定为默认的pfifo_fast队列: dev_open -> dev_activate,
void dev_activate(struct net_device *dev)
{
int need_watchdog;
/* No queueing discipline is attached to device;
create default one i.e. pfifo_fast for devices,
which need queueing and noqueue_qdisc for
virtual interfaces
*/
if (dev->qdisc == &noop_qdisc)
attach_default_qdiscs(dev);
...
}
static void attach_default_qdiscs(struct net_device *dev)
{
struct netdev_queue *txq;
struct Qdisc *qdisc;
txq = netdev_get_tx_queue(dev, 0);
if (!netif_is_multiqueue(dev) || dev->tx_queue_len == 0) {
netdev_for_each_tx_queue(dev, attach_one_default_qdisc, NULL);
dev->qdisc = txq->qdisc_sleeping;
atomic_inc(&dev->qdisc->refcnt);
} else {///multi queue
qdisc = qdisc_create_dflt(dev, txq, &mq_qdisc_ops, TC_H_ROOT);
if (qdisc) {
qdisc->ops->attach(qdisc);
dev->qdisc = qdisc;
}
}
}
static void attach_one_default_qdisc(struct net_device *dev,
struct netdev_queue *dev_queue,
void *_unused)
{
struct Qdisc *qdisc;
if (dev->tx_queue_len) {
qdisc = qdisc_create_dflt(dev, dev_queue,
&pfifo_fast_ops, TC_H_ROOT);
if (!qdisc) {
printk(KERN_INFO "%s: activation failed
", dev->name);
return;
}
/* Can by-pass the queue discipline for default qdisc */
qdisc->flags |= TCQ_F_CAN_BYPASS;
} else {
qdisc = &noqueue_qdisc;
}
dev_queue->qdisc_sleeping = qdisc;
}
创建noqueue
开始尝试直接删除设备默认的pfifo_fast队列,发现会出错:
# tc qdisc del dev vethd4ea root
RTNETLINK answers: No such file or directory
# tc -s qdisc ls dev vethd4ea
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 29705382 bytes 441562 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
后来看到Jesper Brouer给出一个替换默认队列的方式,尝试了一下,成功完成。
替换默认的qdisc队列
# tc qdisc replace dev vethd4ea root pfifo limit 100
# tc -s qdisc ls dev vethd4ea
qdisc pfifo 8001: root refcnt 2 limit 100p
Sent 264 bytes 4 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
# ip link show vethd4ea
9: vethd4ea: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo master docker0 state UP mode DEFAULT qlen 1000
link/ether 3a:15:3b:e1:d7:6d brd ff:ff:ff:ff:ff:ff
修改队列长度
# ifconfig vethd4ea txqueuelen 0
删除qdisc
# tc qdisc del dev vethd4ea root
# ip link show vethd4ea
9: vethd4ea: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT
link/ether 3a:15:3b:e1:d7:6d brd ff:ff:ff:ff:ff:ff
可以看到,UP的veth设备成功修改成noqueue。
小结
总之,给虚拟网络设备创建默认的qdisc,是不太合理的。这会让虚拟机(或者容器)的网络瓶颈过早的出现在qdisc,而不是真实的物理设备(除非应用需要创建qdisc)。更多详细参考这里。
本文转自https://hustcat.github.io/veth/