标题:KnowRob: A knowledge processing infrastructure for cognition-enabled robots
KnowRob:支持认知的机器人的知识处理基础架构
作者:Moritz Tenorth and Michael Beetz
0.摘要
自主服务机器人将必须理解模糊描述的任务,例如“摆桌子”或“清理”。要执行预期的任务,需要机器人充分,精确并适当地设置其低级控制程序的参数。我们建议将知识处理作为一种计算资源,以使机器人能够弥合模糊的任务描述与实际以预期方式执行这些任务所需的详细信息之间的鸿沟。在本文中,我们介绍了KNOWROB知识处理系统,该系统专门设计用于为自主机器人提供执行日常操纵任务所需的知识。该系统允许实现“虚拟知识库”:知识片段的集合未明确表示,而是根据机器人的内部数据结构,感知系统或外部信息源的需要进行计算的。本文概述了各种知识,不同的推理机制以及从外部资源(例如,机器人的感知系统,对人类活动的观察,Internet上的网站以及基于Web的知识库)获取知识的接口。用于机器人之间的信息交换。我们评估了该系统的可扩展性,并提供了各种集成实验来证明其多功能性和全面性。
1.介绍
未来的服务机器人有望成为机器人助手,同伴和(同事)同事(Bicchi等,2007; Bischoff和Guhl,2009; Hollerbach等,2009),这些机器人将执行诸如设置餐桌, 清理,做煎饼。 为了理解和执行诸如“摆桌子”之类的非正式命令,他们需要推断这些模糊的说明中未明确指出的缺失信息。 例如,要设置桌子,机器人必须确定餐所需的物品,在厨房的什么地方可以找到它们以及应该将它们放置在哪里。
我们期望这种从所描述的内容中推断出什么意思的能力将成为直观上可行的未来机器人代理的普遍前提。 在某种意义上,人类给出的大多数指令是不完整的,因为人类希望交流伙伴具有一定程度的常识。 要有能力检测这些信息差距并决定如何获取丢失的信息以及如何在任务执行环境中利用它,将需要机器人代理具有大量的知识体系和强大的知识处理机制。
为了将这些推理技术包括在任务执行中,我们建议以一种支持知识的方式实施机器人的控制程序。 这意味着决策被制定为推理任务,可以由机器人的知识库来回答。 图1给出了一个用于提取对象的例程的示例,该例程紧凑地指定为:“在最可能的存储位置查找该对象。 如果物体在容器内,请使用容器物体的铰接模型以适当的方式打开容器。 编写计划时,程序员通常知道做出决定所需的信息,因此可以决定这些查询的结构,例如前面示例中对最可能的对象位置的查询。 虽然查询的结构和结果是已知的,但实际的结果集将基于执行时机器人的知识来确定。
使用对知识库的查询作为界面,可以创建自动更改机器人知识的机器人计划。如果示例中的机器人探索了周围的环境并发现了一个装有米饭和意大利面的橱柜,则应从那时起考虑在计算搜索通心粉面食时应考虑的信息。额外的知识也可能导致选择不同的推理技术:在考虑相似距离的地方(Schuster等,2012),在存储相似对象的地方搜索对象需要有关环境中其他对象的信息。到这些位置(Kunze等人,2012)需要有关机器人位置的信息。因此,只有相应的信息可用时,这些方法才会生成假设。除了提高适应性之外,启用知识的计划还较少依赖于具体的域或环境,因为有关对象属性,这些对象在环境中的空间排列以及基于此来计算可能位置的推理规则的知识无需调整机器人计划即可独立更改所有知识。
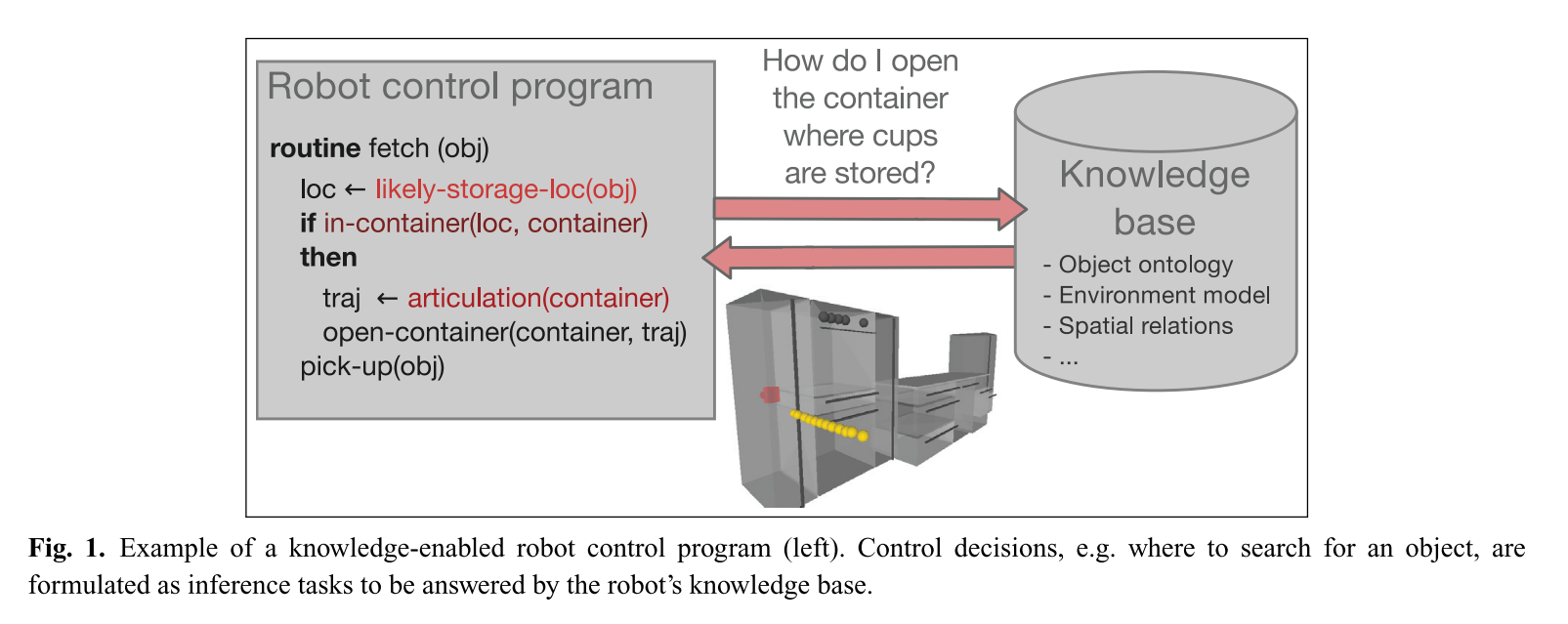
使用对知识库的查询作为界面,可以创建自动更改机器人知识的机器人计划。如果示例中的机器人探索了周围的环境并发现了一个装有米饭和意大利面的橱柜,则应从那时起考虑在计算搜索通心粉面食时应考虑的信息。额外的知识也可能导致选择不同的推理技术:在考虑相似距离的地方(Schuster等,2012),在存储相似对象的地方搜索对象需要有关环境中其他对象的信息。到这些位置(Kunze等人,2012)需要有关机器人位置的信息。因此,只有相应的信息可用时,这些方法才会生成假设。除了提高适应性之外,启用知识的计划还较少依赖于具体的域或环境,因为有关对象属性,这些对象在环境中的空间排列以及基于此来计算可能位置的推理规则的知识无需调整机器人计划即可独立更改所有知识。
但是,为了在任务执行过程中利用这些推断结果,机器人的知识库需要与其感测和作用组件紧密集成。 需要对从外部世界感知的信息进行推断,并已将其抽象到最合适的水平,同时仍保持与原始感知的联系。 这种集成,包括诸如传感器数据中的符号知识的扎根或处理定期更新的(有时是错误的)信息的能力之类的问题,是使机器人知识处理与常见的(不具体的)基于知识的系统区分开来的一个重要方面。
在本文中,我们介绍了KNOWROB,这是专门为自主机器人设计的知识库。 作为CRAM框架的一部分(Beetz等,2010a),它与机器人的控制程序及其感知系统集成在一起,以实现具有知识功能的控制程序。 KNOWROB是迄今为止机器人最全面的知识处理系统之一,它提供了最多样化的知识类型集,推理方法以及与控制程序的集成(有关相关系统的比较,请参阅第11节)。 我们相信,是在一致的框架中多种方法的结合,使我们更接近为机器人配备完成复杂的现实任务所需的全部知识。 我们看不到任何一种方法可以涵盖此类系统的所有必需方面,同时仍然可以作为机器人控制程序的一部分有效,也就是说,在机器人操作过程中计算速度足够快。
这项工作的主要贡献如下:我们描述了KNOWROB的体系结构和设计决策,这些知识和构想形成了一个知识处理系统,该系统可以作为机器人控制系统的一部分在实际应用中运行。广泛的KNOWROB本体将机器人技术和家庭领域概念化,并提供词汇表以连贯的格式描述事件,时间信息,动作,复合任务,动作参数,对象,时空信息,过程以及机器人组件,以及能力。我们提出了“虚拟知识库”的概念,将其作为在机器人内部数据结构及其感知信息之上创建符号层的技术。它允许逻辑推理,同时将原始数据结构保留在后台,以确保抽象概念基于较低级别的数据。我们进一步提出了不同的知识获取技术,以利用从人类活动的观察结果或Internet上的来源获得的信息来填充知识库。
为了评估其性能,我们将知识处理系统视为可以使机器人控制程序做出更好决策的资源。 因此,我们根据其可以回答的查询范围,结果的重要性以及在机器人操作上引起的延迟来衡量其质量。 系统应该能够回答启用机器人的查询类型
- 为成功执行模糊任务(例如“摆好桌子”)提供知识前提;
- 在给定情况下,为特定任务链接适当的感知,推论和执行机制;
- 确定执行任务需要哪些信息以及如何获取它们。
系统的所有软件组件,本体和模型均已作为开源代码1发布,并已在其他多个研究机构中使用。 KNOWROB系统已用于多个集成实验中,例如,为机器人提供了制作薄煎饼所需的信息(Beetz等,2011),以推断在不完整的桌面设置中缺少了哪些对象(Pangercic等,2011)。 (2010年),或者用于在机器人之间交换有关饮料服务任务的信息(Tenorth等,2012)。
本文的目的是深入解释如何将不同的组件集成到KNOWROB系统中以及导致该体系结构的设计决策。 因此,我们不考虑诸如计划的生成和执行,运动的计算或生成机器人将站立或放下物体的合适位置等方面。 这些问题由我们的CRAM机器人体系结构的其他组件解决,Beetz等人对此进行了更详细的描述。 (2012)。 其他相关论文讨论了从互联网(Tenorth等,2011)和对人类活动的观察(Beetz等,2010b)中获取知识。 为了使本文的长度合理,我们无法提供每个方面的详细技术说明,但是请参考有关单个组件的先前出版物以及所发布源代码的文档,以获取更深入的技术信息。
在本文的其余部分中,我们进行如下操作。首先,以一个示例场景来说明如何在我们的系统中使用知识库,因为许多设计决策都受此影响。然后,我们讨论设计注意事项,并介绍构成KNOWROB系统基础的“虚拟知识基础”范式。以下各节概述了KNOWROB的主要组件,解释了选择Prolog作为知识表示和推理的语言,并描述了百科知识如何提供一般词汇,从而提供了从各种来源链接知识的框架。我们继续使用不同的推理技术以及将感知信息集成到知识库中的技术。对在机器人之间交换知识的知识获取方法和技术的简要概述补充了本文的介绍。最后,我们将对使用该系统的综合实验进行说明,并与相关工作进行比较,并讨论KNOWROB的优缺点。
2. 机器人的知识处理
在本节中,我们首先说明对机器人知识基础有很大影响的用例,这些知识对系统的整体设计有很大的影响。 然后,我们在介绍作为系统基础的“虚拟知识库”范式之前,讨论有关知识表示和机器人应用推理的一般设计注意事项。
2.1 知识处理的示例用例
让我们考虑一个需要在饭后清理厨房的机器人。 由于这是家用机器人的常见任务,因此我们希望机器人将配备各种计划,使它们能够在各种情况下可靠地执行这些任务。 CRAM系统中的计划以非常通用的方式指定,并制定控制决策,这些决策需要作为推理任务,由机器人的知识库在执行时回答。
整理计划的总体结构可以描述为:“对于桌子上的所有对象,请将它们放在它们所属的位置”。 下面的伪代码计划说明了此示例; 对知识库的查询突出显示:

虽然非常笼统,但这样的说明也很模糊,并且包含许多未指定的方面。 但是,丢失的信息通常只能在任务执行期间获取:例如,在机器人查看桌面之前,不会知道要放置的实际对象集。 这些对象的目标位置需要根据对象的类型,它们的状态(例如干净或肮脏)和任务的此步骤(例如饭前或饭后)的环境来选择。 如果根据机器人的知识库和信念状态推断出任务参数和控制决策,则可以基于最新信息。
在此示例中,机器人将开车到桌子上,检测一瓶牛奶,然后推断这是需要丢弃的“桌子上的物体”之一。 这将导致物体放置在适当的位置,并得出结论,牛奶需要冷却,因此属于冰箱。 由于目标位置在容器内部,因此放置对象的例程需要从语义环境图中读取的有关容器手柄及其关节模型的信息。
由于特定于域和环境的方面不在机器人计划之列,因此使用相同查询的相同任务定义可用于各种整理任务,例如在厨房,超级市场或机械车间。控制程序提出的问题始终是相同的:哪些东西需要收起? 该对象属于哪儿? 如何打开那个容器? 变化的是会影响结果集以及如何生成这些结果的上下文(例如,用于推断食物,书籍或手工工具的目标位置的不同规则集)。
结果,当程序员设计一个计划时,查询的类型和结构是已知的,这具有几个含义:首先,可以优化查询,例如查询。 通过以连接的限制性最强的部分首先出现的方式对它们进行排序(类似于数据库查询优化中的联接重新排序); 其次,可以通过选择适当的查询谓词来选择要使用的推理机制,以便程序员可以决定是否使用昂贵的技术,例如概率推理。 最后,可以使用例如索引技术针对常见查询类型优化知识库的内部表示。
因此,与其他知识库(例如SQL)(ISO / IEC,2008)或数据日志(Ceri等,1989)类似,我们将知识库主要用作信息检索的工具,以推断操作参数的值。 例如ORO(Lemaignan等,2010),它定期计算可用知识的完整演绎闭合,其主要任务是检查状态的属性,即状态是否属于某个类别。
这种方法导致更可预测的使用模式,并且回溯通常很浅。 这可能导致大量的加速,从而有可能在(实时)实时设置中将知识库用作机器人控制程序的一部分,并且还允许对选定的问题使用昂贵的推理技术,因为程序员可以控制要使用哪种技术来回答查询。
2.2 设计注意事项
在下文中,我们将确定我们认为对于知识处理系统具有重要意义的几个属性,以便成为自主机器人的有用资源,并说明我们如何解决这些问题。 本文着重于与架构有关的问题以及知识库与机器人控制系统的集成。 自主服务机器人的知识处理系统应满足以下条件。
- 它必须提供一个询问服务,机器人可以在其中记录经验和信念,并可以从中查询从存储的知识推断出的信息。 Ask接口在任务执行期间用于决策和推断动作参数化,而Tell接口则用作语义记忆,使机器人能够推理其经验。 由于机器人的知识不是静态的,因此系统必须支持知识库的定期更新。
- 它必须作为机器人控制系统的一部分而有效地运行。一方面,这是指将从机器人组件获得的数据与知识库中的抽象信息进行集成。另一方面,这也意味着产生足够快的答案而不会减慢机器人的操作。为了实现这些(软)实时功能,推理方法的表达性和有效性需要仔细权衡,这通常意味着牺牲表达性以利于实用。例如,我们选择了概率推断技术与(否则为确定性)知识库的较浅的集成(有关详细信息,请参见第6.3节)。虽然成熟的混合推理将允许概率知识与机器人具有的所有确定性知识的灵活组合,但它也是一个非常棘手的问题,无法在实时环境中有效使用。因此,我们选择了表达较少,但更为实用的方法来从KnowRob系统中读取信息,在这个平坦的知识库中进行概率推断,然后将结果传递回KnowRob。
- 它必须提供自然任务规范所提供的信息与机器人成功完成任务所需的知识之间的区别。例如,要正确执行使用刮铲翻转薄煎饼的命令,机器人必须知道要握住刮铲的手柄,仅将其刀片推到薄煎饼下,并且必须运动参数化后可以安全地提起煎饼。所有这些信息都是隐式的,因此必须由机器人进行推断。尽管在动作和物体之间的这种知识在某种程度上类似于提供能力(Gibson,1977),但它还包括有关物体部分的符号知识,用于选择抓握的几何知识,用于识别物体的感性知识以及与体验和动作相关的知识。选择合适参数的知识。除了象征性知识外,机器人还需要连续值的信息:通常不足以推断可以到达某个物体,但是机器人需要驱动坐标才能到达该物体。所有这些信息都是相互关联的,需要结合起来以回答机器人的查询,因此需要以连贯的格式表示。
- 它必须提供一个百科全书知识库,该知识库定义并指定了自主机器人控制所需信息的适当概念。在包括哪些概念以及如何描述它们方面,概念化与主要为自然语言解释创建的其他概念化不同。 Cyc(Lenat,1995)和SUMO(Niles and Pease,2001)等高级本体将鸡蛋指定为鸟类和鱼类的产品,也许包括其营养成分,但是缺乏操纵所必需的知识,例如鸡蛋容易破碎的信息。 。机器人的知识表示必须包括此类与动作有关的知识。因此,用于自主机器人的知识表示必须特别丰富,它们表示动作,事件,过程,情况,动作效果和后果,失败,动作的知识前提等的方式。从网络自动提取本体的最新方法,例如例如NELL(Carlson等,2010)和TextRunner(Banko等,2007),或来自百科全书,例如Wikipedia,例如YAGO(Suchanek等人,2007)和DBpedia(Auer等人,2007)面临着相同的问题,因为这种知识对人类来说常常是显而易见的,以至于没有被明确指出,因此不在网络上。尝试通过问卷调查从互联网用户那里收集常识知识(Gupta和Kochenderfer,2004年)在某些方面很有用,但仍然不够全面也不够深入。
- 它必须为机器人提供自我知识。 自我知识包括有关机器人身体及其传感器和执行器,能力,动作和计划的知识。 给定一个动作说明,机器人应该能够决定它是否有能力执行该动作,如果发现某项能力缺失,则可以以任何方式获得。 与在没有初始知识的情况下对传感器模型(Pierce和Kuipers,1997)或机器人的运动学配置(Sturm等,2009)进行自下而上的学习相反,我们尝试在可能的情况下利用现有信息。 对于许多机器人,都存在详细的工程模型,可以非常精确地描述其运动学结构(Arnaud和Barnes,2006年; Meeussen等人,2009年)。 Kunze等人(2011年)提出了一种将几何描述与语义注释相结合的方法,以使其可用于抽象推理。
- 它必须使机器人了解其动作。 这包括用于预测动作结果的前向模型,以及动作的先决条件和效果的声明性说明。 这些模型将支持机器人计划其动作,预测未来的世界状态以及对动作所造成的变化进行推理(Tenorth和Beetz,2012b)。 他们需要包括有关如何执行操作,可能发生的故障以及如何检测和解决这些故障的知识。 这方面与行动计划的工作有关,但是大多数计划系统集中于确定要执行的行动序列以达到指定的目标状态,而确定如何执行行动以及如何从不完整的指令中确定目标状态的问题 通常需要更多的推论和更多的知识。
- 它必须使机器人能够将其控制系统和感知系统用作知识源。 通常,抽象推理所需的信息已经以某种形式在机器人的内部数据结构中提供,例如机器人的姿态估计,或者可以从其组件(例如感知系统)中获取。 为了重用这些信息,机器人可以“监听”控制程序并将动态数据结构记录为动态和虚拟的知识库(Mösenlechner等人,2010)。 知识处理系统因此充当一种“寄生虫”,它正在重复使用和抽象化出于推理目的而最初创建用于动作执行的数据结构。 由于知识是从用于控制机器人的数据结构中及时生成的,因此抽象表示固有地基于这些数据结构。
- 它需要提供用于(半)自动获取和整合来自不同来源的知识的方法。我们希望手动编码为现实应用扩展所需的大量知识将不可行,因此翻译和导入现有知识的工具将非常重要。可能的知识来源包括人类活动的观察和解释(Beetz等,2010b),机器人活动的日志记录(Mösenlechner等,2010),网络上的任务说明和产品目录等资源(Tenorth等,2011)。 ,常识性知识的集合,例如“开放思维室内常识”数据库Kunze等。 (2010年),以及机器人知识共享技术,例如RoboEarth系统(Waibel等人,2011年)。为了确保高质量的数据,可能需要某种程度的人工监督和适应,才能对齐导入的本体,更正任务描述中的错误以及选择要导入的数据源;但是,与完全手动获取知识相比,我们希望此工作量少得多。
- 它应该利用问题属性使推理变得容易。 机器人需要解决的许多推理问题,即使不是不可行的,也很难以其最一般的形式解决。 尽管许多问题可以用表达形式主义来描述,例如马尔可夫逻辑(Richardson和Domingos,2006)或部分有序的马尔可夫决策过程(POMDP)(Kaelbling等,1998),但通常,可以使用利用特定问题属性的专用推理方法来更有效地解决它们。 因此,我们将通用推理方法与专用推理和过程附件相结合,并使用Prolog作为语言。 面向查询的处理和循环推理模式允许创建优化的数据结构,以支持对常见问题的快速推理。
2.3 虚拟知识库范式
在KnowRob中,在数据进入知识库之前不会将数据抽象为符号概念,因为这是文献中的常见方法(Daoutis等,2009; Lemaignan等,2010)。取而代之的是,一旦需要抽象查询就可以按需计算抽象表示。这使我们能够基于最新信息(在查询时)执行抽象,并达到这种情况下最合适的级别。为此,我们可以使知识库根据需要计算信息,或者使用知识库中已经存在的信息,也可以将查询转发给希望提供更好答案的其他机器人组件。例如,感知系统可以提供有关哪些对象当前在机器人前面的最新信息。通过包含此类外部知识源,在查询时,机器人的知识将扩展到其知识库之外,从而进一步包括可以从可用知识中计算出或可以从外部资源中获取的那些语句。
我们将那些未明确存储但按需计算的知识部分称为“虚拟知识库”。 外部世界可视为机器人可以根据感知任务向其发送“查询”的“虚拟知识库”。 机器人的内部数据结构也可以用作虚拟知识库:推理所需的许多信息已经以某种形式在用于控制机器人的数据结构中可用。 该信息被集成到推理过程中,以便从基础数据结构中透明地提取符号知识。
让我们考虑一下图2中的示例。机器人以概率分布的形式对其位置进行了估算,但是它可能需要根据符号概念进行评估,例如,当决策取决于当前位置估算的可靠性时 。 在KnowRob中,这是通过使用知识库中称为“可计算内容”的类和属性的过程附件来实现的,这些过程附件描述了如何评估基础数据结构上的各个概念。 由于抽象概念是直接从这些数据结构中计算得出的,因此它们是固有的基础,即抽象和子符号表示形式紧密耦合且不能分开。 第6.2节更详细地描述了可计算元素如何集成到推理过程中。
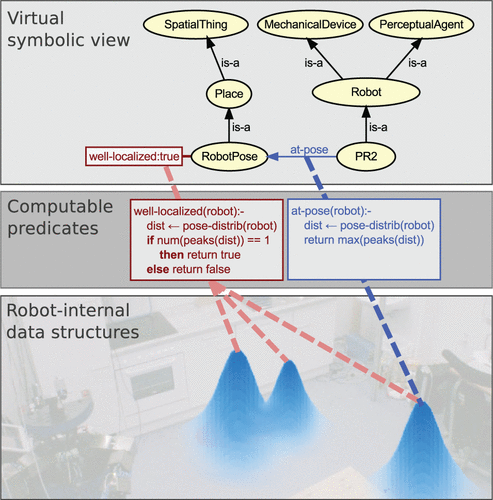
图2。通过在连续数据之上定义“虚拟知识库”,可以将来自机器人控制程序的信息(例如位置估计)集成到符号知识库中。
此概念类似于数据库设计中的视图概念,可以将其定义为简化对复杂数据表的访问。 在我们的案例中,符号知识是原始数据结构的抽象视图,可以进行逻辑推理。 这种方法的一个结果是,我们并不认为知识库中总是存在世界的完整公理化,因为只有在推理过程要求时才会计算大量信息。
3. KnowRob知识处理系统
KnowRob核心系统的知识内容和功能可以通过不同的模块进行扩展。 图3概述了系统结构。 它的核心组件是知识库,该知识库提供了用于存储和检索有关动作,对象,过程,时间事件,其属性和关系的信息的机制。 我们使用开源SWI Prolog(Wielemaker等人,2012)作为中央知识库。 KnowRob本体在此核心系统中表示,并提供通用词汇和表示形式,其他表示形式和推理方法也可以纳入其中。
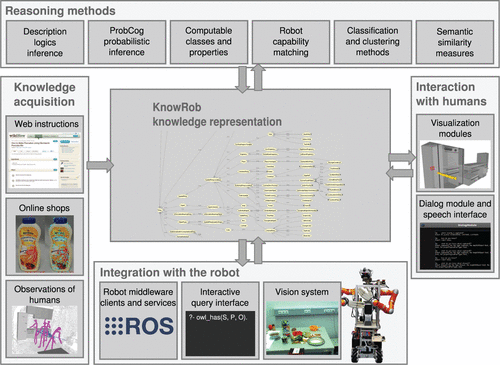
图3. KnowRob系统为知识的获取和表示,知识的推理以及在机器人的感知和动作系统中扎根提供了多个组件。
核心系统可以通过提供各种功能的扩展来扩展。首先,它们可以包含有关“微观理论”的其他知识,这是KnowRob本体的扩展,提供了更多的词汇和谓词定义。微观理论例如用于使系统适应新的应用领域,或包括诸如测量单位之类的新型信息。其次,对推理系统进行了扩展,提供了新的推理技术。它们指定如何描述查询,如何表示上下文,如何返回结果以及调用哪些过程来执行实际推断。第三,存在知识获取的扩展,即用从其他来源提取的信息填充知识库。进一步的扩展为机器人的控制系统提供了接口,以更新知识库中的置信状态并提供知识和推理服务。用于可视化知识并与人类交流的工具可以对知识库内容进行自省和调试。
4. Prolog作为机器人知识处理的国际语言
KnowRob使用Prolog来存储和推理有关机器人的知识。有多种描述一阶关系的逻辑语言,从通用谓词逻辑(Frege,1879),逻辑编程语言(如Prolog,Sterling和Shapiro,1994),到将逻辑与概率表示相结合的语言(Getoor和Taskar,2007)。 )。所有这些逻辑方言都可以描述什么,以及如何优雅地表达各种不同事实。选择具有正确表达能力的表示形式是知识表示和推理系统的重要设计决策。通常,RDF(Becket,2004)或OWL-lite(W3C,2009)等更简单,表达较少的表示方式可以使推理更有效,通常可以保证可判定性等理想属性。它们的缺点是,更复杂的关系可能无法用这些语言表达,或者至少不能以优雅的方式表达。另一方面,CycL(Matuszek等,2006),Scone(Fahlman,2006)或Topic Maps(ISO / IEC,1999)等非常有表现力的表示能够对几乎所有可以用自然语言表达的内容进行建模,但是通常对自动推理的支持不佳。
在KnowRob中,我们选择了Prolog作为具有中等表现力的语言,该语言将过程解释与声明性阅读相结合,使程序员能够检查知识库的内容。在Prolog中编写过程的可能性可以极大地加快推理速度,并扩展纯逻辑推理之外可以计算的范围。它还促进了外部信息源或推理引擎的集成。另一个优点是Prolog是一种相当广泛使用的标准化语言,该语言存在教科书,课程材料和行业实力的实现。由于KnowRob中的大多数推理任务都是对动作参数的查询,因此我们在Prolog中的使用在某种程度上类似于查询语言,例如SQL(ISO / IEC,2008)或Datalog(Ceri等,1989)。这意味着许多用例不需要很深的回溯和复杂的搜索过程,这就是Prolog可以在机器人的控制回路中有效使用的原因之一。
5. 机器人百科知识
百科知识是字典中常见的一种知识:对动作和对象类型的定义,例如杯子是一种容器,有提手并用于饮用液体。 从系统的角度来看,百科全书知识提供了通用,形式化,定义明确的词汇表,用于表示可以被机器人的不同组件使用的知识。 必须共享一个通用表示,以确保由一个组件生成的信息可以被另一个组件使用和解释。
百科知识是常识性知识的补充,常识性知识提供了大多数人可以立即与该概念相关联的其他信息,例如,如果整杯杯子移动得太快,杯子可能会破裂或咖啡可能会倒出。 由于这些事实看起来如此明显,因此通常不会明确列出它们。 但是,有一些举措,例如开放式室内常识(OMICS)项目,试图从自愿的互联网用户那里收集这些知识。 Kunze等人(2010年)描述了将信息从自然语言转换为逻辑表示的技术,这些信息可用于形式化知识库(例如KnowRob)中。
在KnowRob中,我们选择了描述逻辑(DL)作为表示百科全书和常识性知识的形式,特别是Web本体语言(OWL)(W3C,2009),它以基于XML的文件格式存储DL公式。 OWL最初是为了在语义网中表示知识而开发的(Lee等人,2001),但此后已成为一种常用的知识表示格式。 DL背后的概念的广泛概述可以在Baader等人(2007年)中找到,而对Baader等人(2008年)的介绍则简短一些。 OWL文件被加载到基于Prolog的表示中,并且可以使用Prolog谓词进行查询(有关KnowRob中OWL三元组的内部表示的详细信息,请参见第6.1节)。
DL区分术语知识(即所谓的TBOX)和断言知识(即ABOX)。 TBOX包含概念的定义,例如动作,SpatialThing,PickingUpAnObject或TableKnife。 这些概念使用子类定义按层次结构排列,即所谓的分类法,这些子类定义描述了TableKnife是SilverwarePiece的一种特殊化。 ABOX包含作为这些概念的实例的个人,例如,刀作为概念TableKnife的实例。 在机器人应用中,ABOX通常描述检测到的对象实例,观察到的动作和感知到的事件。 相比之下,TBOX描述了对象的类别和动作的类型。
角色描述一个人的属性或两个人之间的关系。 它们可以用于概念定义中,以将类的范围限制为具有某些属性的个人。 例如,概念OpeningABottle可以描述为OpeningSomething的子类,但要限制objectActedOn必须是Bottle的某些实例:

由概念分类法和这些概念之间的关系组成的知识表示称为“本体论”。 OpenCyc本体采用了KnowRob本体的上层布局,包括许多类,它们的层次结构和属性(Lenat,1995)。 OpenCyc已经成为我们保持兼容的机器人知识库的准标准,从而促进了与其他系统的知识交换。 OpenCyc与其他知识库之间还有许多工具和链接,例如Tenorth等人(2010b)使用的WordNet词汇数据库链接。 这些链接可以帮助集成来自不同来源的知识,这些知识涉及不同的上层本体。
但是,由于OpenCyc是为了理解自然语言而开发的,它是一种通用的上层本体,因此它涵盖了广泛的人类知识,但通常缺少机器人所需的特定领域知识,例如在移动操纵和人类日常活动。 因此,我们对Cyc进行了更详细的描述,例如日常任务,家用物品和机器人零件。 图4展示了KnowRob本体的最高级。 最重要的分支是TemporalThings,其中包含事件(黄色)的描述,并且作为重要的子类,包括Actions(绿色)和SpatialThings(蓝色),它们描述了抽象的空间概念,例如Places和Object类。 机器人环境中的大多数对象以及家具或身体部位都包含在HumanScaleObject类下。 其他值得注意的分支是MathematicalObjects,例如Vector或CoordinateSystems(红色)。
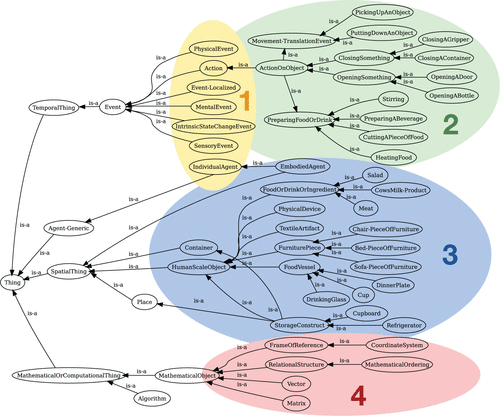
图4. KnowRob上层本体的布局,包括事件和时间事物(1),动作(2),空间事物(3)和数学概念(4)的主要类别。
6. KnowRob中的推理机制
KnowRob使用混合系统体系结构,该体系结构结合了多种通用和专用推理方法。乍一看,使用一种非常具有表现力的技术来存储所有知识并得出所有推论可能看起来更优雅。不幸的是,没有一种通用技术能够同时适用于所有类型的问题,同时又具有足够的表现力来为机器人提供有用的信息,具有足够的可伸缩性以存储大量知识并具有足够的速度来有效地应对各种问题。机器人高级控制回路的一部分。统计关系模型Getoor等人(2007),例如马尔可夫逻辑网络(Richardson和Domingos,2006)和贝叶斯逻辑网络(Jain等人,2009)在单个知识库中结合了概率和确定性信息,但是在这些知识和方法中学习和推论模型通常过于复杂,以至于无法将它们用作大型机器人知识库的唯一表示方法。另一方面,机器人技术中的许多问题都需要概率表示,因此完全确定性表示将在许多意义上受到限制。
因此,我们决定将多种技术集成到一个一致的框架中,并仅将较昂贵的计算技术用于选定的问题。由于KnowRob中的大多数推理是为了回答程序员与机器人计划一起设计的查询,因此可以选择对查询的哪一部分应使用哪种推理技术,并优化其结构以进行快速推理。在系统中,DL知识库用作所有推理方法的域和主干的概念化。其他推理技术也嵌入其中,即它们接受根据DL知识库中的概念描述的参数,并以这种格式返回其结果。可计算的类和属性允许将外部计算的结果透明地注入到DL推理过程中。概率推断方法可以从DL知识库中读取证据数据。可以使用专门的查询谓词(在DL基础结构之外)调用它们,也可以使用可计算函数嵌入它们。
6.1 使用Prolog进行DL推理
DL中的许多推论都可以归结为分类(计算哪些类是其他类的子类)和实现(计算个人所属的最具体类)的问题。 这些任务通常由DL推理程序执行,例如Racer(Haarslev和Müller,2001),Pellet(Sirin等,2007)或HermiT(Shearer等,2008),它们在内存中维护了完全分类的知识库。 对于机器人应用而言,问题在于知识的变化需要重新分类,这对于大型知识库而言可能会花费大量时间。 由于机器人的知识库不断变化,因此可能导致严重的可扩展性问题。 另一方面,将不再需要许多推断的关系,因此根本不应计算这些关系。
因此,我们选择了使用Prolog的基于规则的推理方法:OWL语句在内部表示为Prolog谓词,可以将常用的Prolog推理方法应用于该谓词。 OWL推理模式以Prolog谓词的形式实现,例如,可以检查个人是否遵守在类上定义的所有限制。 由于Prolog中基于搜索的推理不受知识库无关部分更改的影响,因此它可以优雅地处理知识更新。 作为解决方案树中的新分支,Prolog的回溯机制自动涵盖了来自“虚拟知识库”的外部信息,可以轻松地将其包含在推理中。
KnowRob中的实现基于SWI Prolog语义Web库(Wielemaker等,2003)用于加载和存储RDF三元组,以及Thea OWL解析器库(Vassiliadis等,2009),该库在这些之上提供OWL推理。表示形式。高效的内部三元存储构成了语义Web库的主干。它结合了几种索引方案(按主题,谓语,宾语及其组合),并且可以很好地扩展到大型知识库(根据Wielemaker(2009年),在具有64GB GB内存的计算机上,大约三亿个三元组)。一组越来越复杂的查询谓词在内部三元存储的顶部运行,并为每一层添加功能。逐步增加复杂性的好处是,可以通过选择适当的谓词来选择要包含的推理量。特别是,将查询转发到诸如感知系统之类的组件的可计算项可能会减慢推理过程,因此应格外小心。通常,例如在查询开始时仅一次查询感知系统可能就足够了,而随后的部分(例如,检查感知对象的属性)将在知识库的(然后更新的)静态内容上运行。以下谓词层次结构允许查询个人及其属性。我们使用rdf_triple谓词扩展了内置谓词集,以便将可计算项包括在推理过程中。

与常见的DL推理器的重要区别是KnowRob采用Prolog的封闭世界假设:所有未知的真实假设都为假,而通常的DL语义则是开放世界的假设,即所有未明确已知的东西都为假。 如果为假,则认为是真实的。 事实证明,这对于实现机器人程序非常有用,在机器人程序中,一条信息的不可用性本身就是重要的信息。 使用封闭世界语义,不必广泛描述某事物的不存在,而可以从无法证明其存在(否定为失败)这一事实得出结论。 例如,如果机器人必须决定是可以执行任务还是缺少某些组件,它可以简单地检查是否知道所有必需组件都可用,否则拒绝。
6.2 可计算的类和属性
可计算对象是OWL类或属性的过程附件。 它们被实现为可以附加外部推理方法的基于DL的推理的钩子。 它们接受的参数和它们生成的结果都是DL知识库的一部分,这导致了DL推理的完全透明的集成。 有两种可计算对象:可计算类和可计算属性,可计算类创建目标类的实例,可计算属性计算实例之间的关系。
可计算对象可以附加到任何OWL关系,而无需更改其语义描述。 在图5中,将ActionOnObject链接到SpatialThing的关系objectActedOn由其域和范围照常建模。 通过将二进制Prolog谓词指定为命令,可以将一个或多个可计算属性链接到要由其目标属性计算的属性,从而定义如何计算此关系。 通过目标属性附加可计算项将要计算的OWL关系的语义属性与定义如何最终计算这些关系的实现方面分开。 它也有助于系统的模块化,因为可计算定义可以在运行时轻松地加载和卸载。
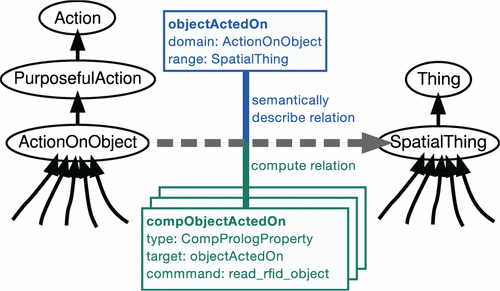
图5.可计算的属性computeObjActOn附加到OWL属性objectActedOn上,并在程序上描述如何计算此关系。
可计算产品的一个重要用例是从现有信息中计算新语句,例如定性的时间或空间关系,例如“期间”或“之上”。在内部,KnowRob将对象的姿势和时间实例存储为数值。可以使用计算机根据这些值计算定性关系。由于仅计算了回答查询所需的那些关系,因此该方法避免了由于存储对象之间所有可能的成对关系而引起的组合爆炸,同时仍然允许对时间和空间信息进行定性推理。另一个用例是外部数据源和知识获取方法的透明集成,例如用于从Web读取任务指令(第8.1节)或从感知系统读取对象检测(第7节)。如果存在适当的可计算定义,则当查询涉及各个概念时,将自动查阅这些外部信息源。
尽管在大多数情况下自动包含计算和知识获取非常有帮助,但可能并不总是希望如此。 因此,我们允许用户通过从第6.1节中引入的查询谓词层次结构中进行选择,来决定是否包括可计算内容来回答查询。 另外,可以在运行时通过(卸载)它们的定义来全局(取消)激活某些可计算项。
6.3 概率推断
机器人经常遇到的事实要么不确定,例如不确定的传感器信息,要么仅在一定程度上真实,例如不确定的人类喜好。统计模型已成为表示此类不确定信息的机器人技术中不可缺少的工具(Thrun等人,2005),例如,通过使用粒子滤波器表示机器人位置上的概率分布,从而解决了定位和制图问题。尽管这些模型非常适合描述有关具体实体的概率信息,但是通用原理的表示以及关于对象类型或对象之间关系的知识要求一阶表示具有更大的表现力。统计关系模型(Getoor和Taskar,2007)将一阶逻辑表示的表达能力与统计模型表示不确定信息的能力结合在一起。迈向关系模型的过程相当于从命题逻辑到一阶逻辑的过渡:这些模型能够从领域中的具体实体中抽象出来,并代表也可以在不同情况下应用的一般关系知识。为了有效地进行推理,概率模型需要紧凑地表示概率分布。图形模型是已建立的解决方案的问题。因此,许多统计关系模型被实现为无向的扩展(例如,马尔可夫逻辑网络(Richardson和Domingos,2006))或有向图形模型(例如,多实体贝叶斯网络(Laskey,2008)或贝叶斯逻辑网络(Jain等, 2009)),因此可以利用针对这些基本表示形式开发的推理方法。
高表达能力与不确定性表示的结合使统计关系模型非常适合自主机器人所处的不确定,部分可观察和动态环境,当模型变大并且包含许多实例之间的复杂关系时,此类模型的推论可能会变得非常困难,甚至难以解决。 精确的推论极难处理,尽管存在各种近似的推论技术(有关介绍,请参见Bishop(2006)),但其适用性取决于推论问题和模型结构。 由于这些原因,KnowRob中的统计关系模型仅用于需要表示不确定关系的选定问题。 程序员的任务仍然是设计和训练合适的模型,选择和测试合适的推理算法,并在查询中指定应使用概率模型。
通过集成ProbCog库,可以在KnowRob中实现统计关系学习方法。 ProbCog为集成在通用框架中的Markov逻辑网络和Bayes逻辑网络提供了多种学习和推理算法。图6描述了如何从技术上实现集成。 ProbCog中的统计关系模型各自形成一个概率知识库,可以从KnowRob进行访问。将这些知识库与KnowRob集成是一项艰巨的任务:系统需要确定使用哪种统计模型来回答哪个查询(谓词可能出现在不同的模型中,尽管某些谓词可能更适合于推断其价值)。两个知识库中的谓词可能具有不同的标识符和语义,并且推理结果需要以某种方式进行处理以在KnowRob上下文中使用,例如,通过选择最可能的解决方案或迭代按其概率排序的所有结果。在提出的解决方案中,可以使用Prolog谓词以灵活的方式定义这些方面。每个ProbCog模型都有一个对应的KnowRob模块,模型设计人员可以在其中编码可以回答哪些查询,在系统之间如何转换谓词,要使用哪种模型以及是否应使用开放世界或封闭世界推断。在一个简单的情况下,两组谓词之间的映射可能都是微不足道的,并且默认模型可用于所有推断。在更复杂的情况下,映射可能会变得非常复杂,并且选择合适的模型时会考虑到查询谓词集和执行上下文。
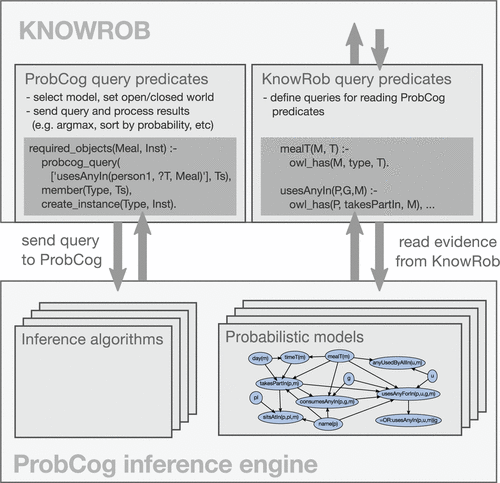
图6.将ProbCog推理系统集成到KnowRob知识库中。 两组查询谓词在两个系统中的谓词之间转换,定义概率推断的参数并确定如何进行结果处理。
使用probcog_query谓词(图6的左上方)发送来自KnowRob的查询。在开始推理之前,使用具体域实例化抽象统计关系模型,并设置证据值。使用包装谓词从KnowRob读取此信息,该谓词将ProbCog模型中的谓词转换为对KnowRob知识库的查询。这些谓词可以利用KnowRob的所有功能,包括DL推理或可计算属性。在第10.4节所述的实验中,例如,我们使用了KnowRob的界面来识别对象的方法,以读取表上感知到的对象集作为概率推断的证据。然后,在概率知识库中完全执行推断。完成后,结果将作为具有相关概率的值列表传递回KnowRob。然后,可以进一步处理这些结果,以在知识库的确定性部分(例如,知识库)中使用。选择最可能的解决方案,或返回按其概率排序的所有解决方案。
概率推理方法也可以包装到可计算的内容中,以便在需要相应的信息时自动执行它们。 虽然可以存储推断出的概率(例如,作为对象应该在桌子上的概率),但它们不会通过后续的(非概率)推断步骤进一步传播。
7. 界面感知
每当机器人与对象交互时,它们都需要推理其属性,推断在何处找到它们,如何操纵它们或将它们放置在何处。 做出这些决定需要机器人将其有关对象类型的抽象知识应用于环境中存在的物理对象。 因此,知识库需要链接到感知系统,以便被告知在哪种姿势下已检测到哪种类型的物体。
存在以不同方式接口的不同种类的机器人感知系统:某些感知方法按需执行识别,其他感知方法对传入的传感器数据流进行连续操作。 在前一种情况下,与知识库的通信是使用基于请求-响应的方案同步执行的,在后一种情况下,是通过被动侦听已发布的对象检测来异步进行的。 实现这些接口的方法可以在knowrob_perception包中找到。
图7可视化了两种界面。 在同步通信的情况下(左上),使用可计算解决了与KnowRob的集成:定义了具有适当目标的可计算类,只要查询涉及相应类型的对象,该类就会自动调用。 然后,可计算组件将请求查找此类对象的请求发送给感知系统,并为结果集中返回的所有检测到的对象创建对象表示。 尽管可计算对象通常是相当通用的类,可用于一次检测几种不同类型的对象,但生成的对象实例将具有由对象识别系统确定的特定类型。 例如,Willow Garage使用这种接口从tabletop_object_detector5中读取信息。
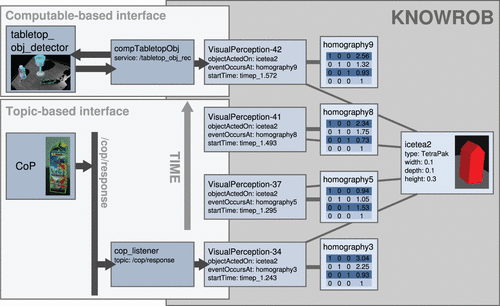
图7.基于可计算和同步通信(左上)或通过侦听对象检测(异步通信,左下)的知识库和感知系统之间的两种接口。 两种系统都在知识库(右侧)中创建相同的对象姿态表示,该表示形式存储了每次检测对象的感知方法,时间点和姿态。
第二种接口,使用异步通信,侦听所有感知结果并将其添加到知识库中。 该侦听器在与KnowRob引擎并行的单独线程中运行,接收在该主题上发布的所有对象检测,并为它们创建各自的感知实例(图7的左下方方框)。 例如,第二种界面用于从CoP视觉系统(Klank等,2009),K-CoPMan系统(Pangercic等,2010)和RoboEarth对象识别组件(Marco等,2012)中读取信息。
除了识别对象的姿势外,知识库还应该提供有关所有对象都可以被识别的信息,即机器人具有适当识别模型的对象。 KnowRob维护一组可用的对象识别模型的内部表示,该模型允许推理出可以识别哪些对象。 意识到这些识别功能对于评估计划是否可以成功执行或是否需要获取其他模型非常重要。
请注意,KnowRob不会触发要求机器人移动的感知机制。 我们决定,只有机器人的执行人员才可以调用更改机器人物理状态的动作,因为它可以最佳地评估某个动作的副作用是否会干扰正在执行的另一个动作。 例如,在执行重要的操作任务时,不应命令机器人将视线移开。 尽管KnowRob无法主动启动这种主动的感知动作,但它仍可以处理执行者启动的动作的结果(如果以可访问的方式发布这些动作的结果),并将其包含在知识库中。
8. 获取知识
前面的部分介绍了KnowRob的知识处理基础结构及其表示和推理方法。 为了将这些方法用于机器人应用,必须用内容填充表示形式,并提供机器人胜任地完成日常操纵任务所需的大量知识。 对于要在现实条件下运行的大规模系统手动编码此知识将是一项艰巨的任务。 因此,我们探索了从现有资源中自动获取知识的方法。
一种有用的资源是最初为人类创建的网页,可以从中提取信息。 例如,wikihow.com和ehow.com提供了成千上万的分步说明,适用于从清理到设置表格的各种日常任务。 食谱数据库(例如epicurious.com)包含大量烹饪食谱。 在线商店提供有关对象外观和属性的信息。 使机器人能够利用这些知识源将帮助他们更快地朝自然人类环境中的实际任务扩展。 在本节中,我们将简要描述在KnowRob中实现的一些技术,并参考相应的出版物以获取更详细的描述。
8.1 导入自然语言任务说明
Tenorth等人(2010b)描述了一种将自然语言任务指令转换为机器人计划的方法,该方法包括以下步骤。 首先,使用通用的自然语言解析器(Klein和Manning,2003)对句子进行解析,以生成指令的语法树。 然后将树的分支递归合并为更复杂的描述,以创建指令的内部表示,这些指令描述了动作,所涉及的对象,位置,时间限制,要使用的配料量等。通过首先在WordNet词汇数据库中查找其含义(Fellbaum,1998年),然后利用WordNet与Cyc之间的映射关系(Lenat,1995年),将原始文本中的单词解析为机器人知识库中的概念。 KnowRob分类法的大部分都与Cyc本体兼容,因此可以直接利用这些映射将自然语言单词链接到KnowRob中的概念。
任务规范的自动导入有助于快速获取执行任务所需的动作和对象的形式描述。 尽管在许多情况下,指令结构通常与命令性语句相似,这有助于自动处理,但是,对这些指令的完整理解将需要解决(非常困难)一般的自然语言理解问题。 特别是长句子和复杂的语法结构仍然会在初始解析步骤以及后续处理阶段引起问题。 因此,我们认为这些方法主要是为了帮助程序员从现有资源中快速生成最初的规范草案,然后可以对其进行扩展和调试。 在这种情况下,程序员还可以选择要导入哪些网站和哪些指令以确保数据质量。 系统的源代码位于comp_ehow软件包中。
8.2 生成产品知识库
为了执行这些抽象的任务描述,机器人需要将所包含的对象引用与环境中的物理对象相结合。 这需要有关其外观的信息以用于识别,还需要有关其属性的信息,以便在环境中定位它们并正确处理它们。 可以从在线商店提取有关对象外观及其属性的信息,这些商店的产品目录中列出了大量带有图片和结构化描述的对象。 Pangercic等人(2011)描述了基于产品图片的物体识别方法,Tenorth等人(2011)描述了从在线商店创建产品本体。 通常需要进行一些手动调整,以将生成的本体与现有本体进行对齐,但是至少对于创建现有类的详细分支的用例而言,这仅包括添加一些子类声明。
8.3 从人类观察中提取知识
虽然万维网对于可以口头表达的信息非常有用,但是还需要从其他来源获得其他类型的知识,这些知识位于更远的位置(例如,特定环境中的位置)或具有连续价值的知识(例如,运动)。 通常,对人类在环境中执行类似活动的观察可以提供此类信息。 通过机器人的动作和与之交互的对象,机器人可以了解他们如何执行任务,使用的位置或动作期间的移动方式。 图8示例性地示出了可以提取的信息,例如人的姿势,被分割和分类的手轨迹,在任务中起特定作用的位置或人与之交互的对象。 要将观察结果与其他知识整合在一起,必须将其与机器人知识库中的符号信息相关联进行设置。
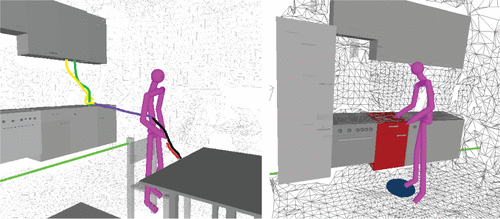
图8.观察人类活动的示例用例 左:运输任务的分段轨迹和分类轨迹。 右:语义标注的数据,例如人类用来拾取物体的姿势和位置。
Beetz等人(2010b)提出了跟踪人体运动并将其细分为片段的技术,这些片段在机器人知识库中表示为动作类的实例。 通过应用有关动作组成的知识,创建观察到的活动的结构化和语义注释的表示,可以将这种正式的动作表示抽象为分层的任务模型。 由于观察结果是使用与机器人动作相同的本体描述的(作为用于机器人计划的动作类的实例),因此它们可以很容易地被机器人用作计划其动作的知识来源。 查询可以组合符号和子符号信息,例如用于读取在给定任务上下文中用左手到达的所有轨迹。
9. 交换知识
尽管在上一节中做了很多努力,但是知识的获取仍然是一个复杂的过程,通常只能部分自动化。 但是,一旦以机器人可以理解的格式获得了一些知识,就应该可行地进行交换以使其可用于其他机器人。 建立一个可用于在机器人之间交换信息的基于Web的知识库是RoboEarth项目的目标(Waibel等,2011)。 KnowRob知识库是该系统提供知识表示和推理服务的核心组件。 与RoboEarth系统进行交互的库也可以作为开源软件获得。
需要表达表示以使信息的自主交换成为可能:首先,它们需要对要交换的信息进行编码,即对动作或对象类的描述。此外,他们还需要支持机器人查找和选择信息:下载任务描述之前,机器人应确保它具有所有必需的功能,并检查是否需要其他组件,例如对象识别模型。要使该信息选择过程自动化,需要形式化的表示和注释,这些描述和注释描述了要使一条信息可用需要满足哪些条件。机器人可以将RoboEarth中任务说明的要求与其自身组件和功能的形式模型进行匹配,以验证所有必需组件是否可用。如果缺少软件组件,则机器人可以例如加载更详细的任务规范,对象模型或环境图。尽管此过程不能保证成功执行任务(由于各种原因仍然可能失败),但它至少可以基于与可用任务有关的所有信息来计算机器人是否具有所有必需的信息。
10. 评估和实验
评估机器人的知识处理系统是一项复杂的任务,到目前为止,既没有基准,也没有评估方法。 在机器人上使用知识处理技术有其特定的挑战,这些挑战通常不同于人工智能研究中通常研究的经典的,纯粹的符号推理问题。 这些挑战的一部分与在物理系统上使用方法有关,其他挑战则由复杂的场景提出。
由于机器人在现实世界中行动,因此它们的知识库必须实时运行并足够快地计算结果,以免减慢机器人的其他组件的运行速度。符号知识库需要以机器人的感应和致动方法为基础,以使机器人能够推理出其感知到的物体及其执行的动作。知识库中抽象定义的动作需要链接到机器人上可执行动作组件的参数化,并且机器人必须能够处理其传感器提供的不确定和不完整的信息。在复杂现实场景中的应用程序在可伸缩性,表达性,全面性和实用性方面都具有挑战性。知识表示需要具有足够的可伸缩性,以在类级别(例如,级别)上处理大量知识。用于在实例级别上描述大量对象类型,例如存储长时间记录的所有物体观测值。
很难以几个总数来捕获所有这些方面。 因此,我们通过不同方法的组合来评估系统的质量:对系统的可伸缩性及其响应时间进行定量评估。 描述了三种复杂的使用场景,以显示我们系统的不同组件如何有助于解决现实任务。 然后,我们将开发的系统与文献中的其他机器人知识库进行比较,以了解它们的功能,并讨论我们当前实施方式的局限性。
10.1 可扩展性和响应能力
为了评估系统的可扩展性,我们使用内部对象表示进行了测试。 对象的表示是更复杂的描述之一,因为它由对象实例组成,并且对于对象的每次检测都包含一个4××4的姿态矩阵和一个描述感知事件的实例。 同时,它是最重要的信息之一,因为对物体的新颖检测是在机器人操作期间不断出现的一种信息。 我们创建了一个测试程序,该程序在循环中创建大量对象检测,对应于对该对象的数千(虚拟)感知。
我们用多达65,000个感知实例对系统进行了测试,这些实例对应于整整一周的时间,在此过程中,机器人每十秒钟连续检测一次物体。 图9可视化了创建新实例(蓝色方形标记)所需的时间。 它与它们的数目成线性比例,可以在大约2.88秒内创建65,000个对象检测。 因此,用于创建对象实例的最大帧速率约为每秒22,000次检测,对应于每秒170,000次三元组。 作为比较,有关ORO知识库的论文(Lemaignan等人,2010年)给出了每秒7,245个三联的速率。
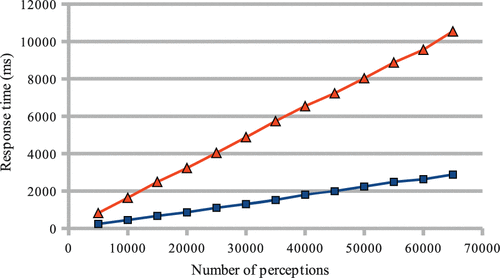
图9.大量物体感知(蓝色方形标记)的创建与物体的数量成线性比例,并且即使在65,000次观察中也处于几秒钟的范围内。 对于最新感知(橙色三角形)的查询对于线性实施而言是线性的,但是可以使用优化的数据结构在恒定时间内实现。
橙色三角形描述查询对象的最新检测所需的时间。 对于这些测试,我们使用了一个简单的实现,该实现将一组在不同时间点的对象检测附加到对象实例。 虽然这是以逻辑形式描述关系的直接方法,但是优化的实现将感知存储在链接列表中,并带有指向其头部的指针,可以将查询最新检测的时间减少到10-20的恒定时间 多发性硬化症。 这显示了对常见查询模式(例如,最新检测到的对象)进行优化的潜力。
65,000个对象感知对应于知识库中的490,000个三元组。 我们已经在普通笔记本电脑(Intel Core 2 Duo P8600、2.4 GHz,4GB GB PC3-8500 RAM,Ubuntu 10.10 32位)上测试了大约700万个三元组,而没有明显减慢其他程序的速度或创建新的三元组。 490,000个三元组将整个Prolog过程的内存消耗从16.5 MB增加到47.8 MB。 根据底层三元组商店的作者的说法,在高端商品硬件上,它可以扩展到几亿个三元组(Wielemaker等,2012)。
尽管这些实验表明可以存储和处理扩展实验室实验所需的合理数量的知识而不会出现问题,但当前系统的可伸缩性仅限于单台计算机可以处理的内容。 还有一些推理任务比底层三重存储的可扩展性差。 时空索引技术将有助于对大量知识进行更有效的推理。 诸如内存中短期内存和基于磁盘的长期内存之类的内存级别层次结构将提高存储方面的可伸缩性。 将信息移到长期存储器中时,也可以将其压缩,例如仅记住信息何时已更改。 为了进一步扩展,随着我们开始在RoboEarth项目(第9节)中进行调查,可以将基于云的知识库添加为另一层背景知识。
10.2 基于知识的任务执行
在Beetz等人(2011)提出的实验中,两个机器人使用wikihow.com的指令制作了煎饼,以生成机器人计划。 KnowRob知识处理系统用于从Web指令生成计划,并将抽象指令置于机器人的感知和动作系统中。 为了执行指令,将动作映射到机器人上的计划,将对象规范解析为物理对象,然后由机器人决定在哪里搜索这些对象。
10.2.1 根据Web指令生成计划
说明中指定了成分,牛奶和准备好的煎饼混合物,以及一系列操作步骤:
1. 从冰箱里取出薄煎饼混合物;
2. 加400毫升牛奶(至标线),摇晃瓶头1分钟; 让煎饼混合物静置2-3分钟,然后再摇一摇;
3. 将混合物倒入煎锅;
4. 等待3分钟;
5. 将薄煎饼翻转过来;
6. 等待3分钟;
7. 将薄煎饼放在盘子上。
使用前面描述的将指令转换为机器人计划的技术,生成了正式的任务规范,然后将其转换为以下机器人计划:

上面的代码显示了从Web指令生成的CPL计划语言的粗略计划(Beetz等,2010a)。 声明部分为指令中引用的对象创建实体指示符。 指示符由文章(确定的或不确定的),实体类型(对象,位置,东西等)和一组属性-值对组成。 填充物是指均质的东西,例如水,牛奶等。反引号运算符指示后面的块不应视为代码,而逗号(在该块内部)则相反。 然后,将指示步骤本身指定为要实现的目标序列,这些目标是指先前定义的指示符。 因此,该计划不是指定采取煎饼混合物的动作,而是指定将煎饼混合物放在手中的目标作为其相应的计划步骤。
从Tenorth等人(2010b)的评估中可以看出,进口商正确地翻译了48%至80%的说明。 主要问题是由解析器无法正确处理的复杂句子引起的,或者与具有多种含义的单词错误消除歧义有关。 因此,我们将这种技术视为对程序员的一种帮助,该技术将以半自动方式而不是完全自动化的程序来使用。
10.2.2 推断在哪里搜索对象
在家庭环境中,对象通常存储在诸如橱柜或抽屉之类的容器中,因此机器人必须先搜索它们才能使用。 为了快速找到所需的对象,机器人应该首先在最可能的位置搜索对象。 我们的机器人使用环境的语义3D对象图,其中对象的结构化模型(例如由容器,门,把手和铰链组成的橱柜)与对象的一阶符号描述相关联,这些描述主要来自于 机器人的百科全书知识库(Pangercic等,2012)。
有多种可能性来推断对象的可能存储位置。 如果机器人知道某些对象的位置,则可以基于它们与已知对象的语义相似性来计算新颖对象类型的位置(Schuster等,2012)。 如果没有此类信息,则可以使用抽象规则,例如“冰箱是易腐烂物品的存放场所”。 通过将其有关对象属性的知识(以推断手头的对象是否易腐烂)与语义环境图(以定位冰箱的实例)相结合,知识处理系统可以计算在哪里搜索对象。 图10可视化了这些推断步骤。 如第8.2节所述,右侧的本体部分是由germandeli.com在线商店生成的。
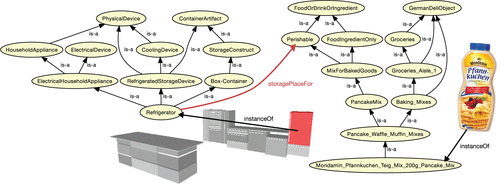
图10.推理步骤来推断一瓶煎饼混合物的可能存储位置。 此示例基于类级别的断言,即冰箱是用于易腐物品的storagePlaceFor。 右侧的本体片段是从在线杂货店的网站自动生成的。
尽管这些不同的方法可以共存于知识库中并独立生成位置假设,但是不同推理机制的结果的集成仍然是一个悬而未决的问题,尤其是当它们产生冲突的结果时。 一种直接的选择是信任某些方法,例如,一种使用有关相似对象的信息的方法,而不是例如基于通用类级别规则的方法。 另一种选择是像Kunze等人(2012年)那样使用基于实用程序的方法来组合结果,以决定首先要搜索的位置。
10.2.3 以知识为基础的方法的重要性
尽管使用常规控制程序的“知识贫乏”机器人系统可以在特定任务上产生类似的行为,但使用知识支持方法的优势在于灵活性和适应性的提高:可以将现有原始动作组合起来轻松创建新颖的任务,并根据环境模型自动推断其参数。 如果环境发生变化,则无需修改计划,因为与环境相关的推理在知识库中集中进行,并由空间环境模型进行参数化。
10.3 机器人之间交换信息
我们进一步研究了交换任务相关知识的技术如何使机器人能够在以前未知的环境中执行移动操作任务(另请参见Tenorth和Beetz(2012a))。 实验是在两个地点使用两个不同的机器人平台(PR2和Amigo机器人)进行的。 机器人将在医院病房的床上为患者提供饮料,即首先在环境中找到一个瓶子,打开封闭柜,将其捡起,移交给患者,然后移交给瓶子 。 PR2首先执行任务,从而估计包含瓶子的橱柜的铰接模型。 然后,此信息与Amigo机器人共享,后者可以使用该模型在不同位置打开相同类型的机柜。
仅向这两个机器人发出了“提供饮料”命令以及它们在其中工作的环境的地址。仅基于此信息,这些机器人就成功下载了任务所需的所有信息。 另外,他们还配备了诸如导航或抓握之类的基本动作的计划,以及用于例如识别物体的软件。 但是,在实验之前,没有任何涉及对象的模型,也没有任何环境图,也没有任何可用的特定于任务的信息。 这些信息需要从RoboEarth知识库中下载,并且必须以机器人的感知和动作系统为基础。 KnowRob系统在实验的以下部分中做出了贡献:
- 任务说明,环境模型和对象模型的正式表示形式,包括有关它们的组成部分和连接特性的信息;
- 从中心RoboEarth知识库下载任务说明和其他信息;
- 使“喝一杯”规范的要求与机器人的功能相匹配,识别并下载缺少的组件;
- 运行时知识库将执行人员与感知和世界建模组件接口,为执行人员提供有关要执行的动作及其参数,对象位置的信息。
图11的上部显示了从RoboEarth下载的环境图。 根据这些地图,机器人(图11的底部)可以导航到适当的位置并找到任务所需的对象。 根据给定的命令下载了任务说明,然后将其与机器人的功能进行了匹配:结果是所有必需的功能都可用,但是缺少任务中提到的某些对象的识别模型(即瓶子和床) ),已下载,包括图11所示的CAD模型。

图11.顶部:根据地址和房间号从RoboEarth下载的两个医院房间的语义环境图。 底部:PR2和Amigo机器人打开橱柜并拿起要饮用的饮料。
到目前为止,RoboEarth系统仅用于交换符号任务描述,这些描述不提供有关运动,力或加速度的信息。 在我们目前的研究中,我们致力于将表示形式扩展到可以由运动控制器解释的约束条件下的较低层信息(Kresse和Beetz,2012年)。 工作的另一个方向是如何将其他机器人创建的本体片段合并到知识库中,尤其是在与局部修改有重叠的情况下。 在当前环境下,此类本体对齐技术(Euzenat等,2011)尚未成为系统的一部分。
10.3.1 以知识为基础的方法的重要性
特别是在知识交流的背景下,明确的表示非常重要。 常规控制程序不会“知道”它在内部数据结构中拥有的知识,并且无法将该知识提取为其他机器人可以使用的格式,除非已针对此任务进行了明确修改。 没有明确知识的机器人也无法检测到丢失的知识,无法“解释”基于Web的知识库以下载这些信息的确切缺失(就搜索查询而言)。 如果控制程序是编译代码,则无法下载和执行新任务的计划。 简而言之,如果没有基于知识的方法,则只能在相同的机器人平台之间交换二进制程序。
10.4 推断表上缺少哪些对象
另一个展示机器人如何利用其知识完成复杂任务的综合实验是推断不完整表格设置中缺少哪些对象。10要完成该任务,机器人必须首先找出要进行哪顿饭以及需要哪些对象它。因此,它需要有关在不同餐点中使用的食物和餐具的类型以及参与人员的偏爱的详细知识。该场景还演示了KnowRob中的不同组件如何可以共同用于解决复杂的任务。 Pangercic等人(2010年)对系统进行了更详细的描述。 KnowRob充当集成平台,用于提供有关当前可以在桌子上看到的对象的感知信息以及所学习的统计关系模型的信息,这些统计关系模型关于哪些对象通常由不同的人用于不同的用餐。使用第7节中描述的技术,将视觉系统检测到的对象添加到知识库中。通过将检测到的对象姿势与环境信息相结合,系统可以基于用于定性空间关系的可计算项来计算给定表上的对象。
这组对象是6.3节中所述的统计关系推断方法的证据。 推论是基于对人类进餐(模拟)观察所得的模型进行的,该模型描述了进餐的类型,参加者以及谁使用哪种餐具食用了哪种食物。 图12显示了贝叶斯逻辑网络的依存关系结构,在对这些数据进行训练后,该依存结构有效地代表了人类膳食不同方面的联合概率分布。 在执行过程中,机器人控制程序向KnowRob发送查询,询问缺少的对象集,KnowRob将该查询转发给ProbCog推理引擎,然后ProbCog推理引擎加载相应的模型,从KnowRob中读取证据(在 表格)并进行推断。 示例查询及其结果如下所示:

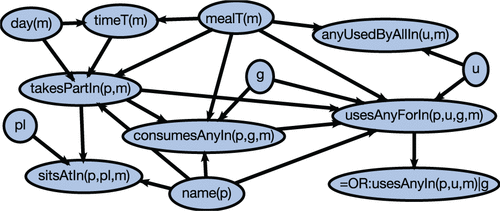
图12.膳食准备上下文的贝叶斯逻辑网络,描述了参与膳食的人们与他们所使用的食品和器皿之间的关系(由Dominik Jain提供,来自Pangercic等人(2010年))。
推论的结果是一组具有指定概率的对象类型,这些概率指示应该在表上放置哪些对象。 减去已经存在的对象后,KnowRob确定哪些对象仍然丢失,并根据其感知内存和对环境中存储位置的了解来推断从何处搜索它们。
图13可视化了一些示例性场景的结果。 上排显示了输入图像,其中已识别出不同的对象。 这些对象在表格下方的下部图像中以红色显示。 推理结果表明桌子上哪些物体被认为是丢失的,色相值对应于从低(蓝色)到高(红色)的概率。 在左图中,系统推断出肯定缺少刀和玻璃杯:这是合理的,因为有果汁,但没有饮水器,也没有刀来切蛋糕和香肠。 中间的图像显示了已经在桌上放置银器的设置,但是显然缺少杯子和盘子。 在右图中,再次是喝水和果汁所需的玻璃杯。

图13.缺少对象的查询结果。 上排:输入摄像机图像(由Deanger Pangercic提供,来自Pangercic等人(2010))。 下排:可视化推断结果,其中色相指示推断出对象丢失的概率(蓝色:低;红色:高)
10.4.1 以知识为基础的方法的重要性
使用人类饮食行为的显式模型,我们可以通过一个非常通用的控制程序来实现此任务,该程序主要由以下语句组成:“对于所有丢失的对象,将它们放到表中”。 根据型号,此控制程序将适用于不同国家/地区的不同餐点以及非餐点环境。 在经典程序中,必须使用if-then-else语句对规则进行手工编码,如果情况变得复杂,则可能会非常困难:手动编码大量对象类型之间的关系并取决于因素 例如,由哪个人吃饭,是一项复杂的任务,需要对问题进行彻底的分析,而贝叶斯逻辑网络学习到的联合概率分布隐式地处理了这些情况。
11. 相关工作
在机器人上使用知识表示和推理技术的历史由来已久:早在机器人技术时代,诸如Shakey(Nilsson,1984)之类的机器人就已经配备了世界模型,这些世界模型使用谓词逻辑描述了环境并支持自动推理。 。但是,这些模型的扩展范围并没有超出Shakey所从事的人工区块世界,并且在随后的几十年中,机器人技术和人工智能(AI)的研究相当独立地进行。在知识表示中,与本文最相关的AI研究领域包括诸如情境演算(McCarthy和Hayes,1969),事件演算(Kowalski和Sergot,1986)和流利演算(Thielscher,1998)之类的技术。诸如Cyc(Lenat,1995)或WordNet(Fellbaum,1998)之类的知识库收集了大量知识,最近,万维网的兴起催生了从结构化源(如Wikipedia(Auer)中自动提取知识库的研究。等人,2007年; Suchanek等人,2007年)或Internet上的非结构化信息(Banko等人,2007年; Carlson等人,2010年)。但是,这些知识库没有具体体现,没有扎根于机器人的控制系统中,并且通常无法提供机器人所需的各种信息。如果有关知识表示的文章使用机器人技术作为应用场景,那么这些方法通常会过于形式化,而缺少现实场景中所需的功能。例如,题为“代表机器人的知识”的论文(Thielscher,2000年)未考虑诸如时间推理,详细的空间表示,有关对象类型的信息,环境中的过程,接地或与机器人控制系统集成等方面。
另一方面,机器人技术的工作通常集中在诸如有效的本地化和地图创建以及忽略高级语义方面之类的问题上。然而,对象识别的最新进展导致了对语义图的更多研究,从而在机器人应用程序中更广泛地使用了高级语义知识,尽管“语义级别”的范围从单纯的分类分为不同的部分和对象类型(Rusu 2008)。 )或对象(Vasudevan和Siegwart,2008)与DL中的环境表示(Zender等,2008),统计关系环境模型(Limketkai等,2005)并存以及将空间信息嵌入到百科全书和常识中知识库(Tenorth等,2010a)。 Galindo等人(2008年)已经研究了使用语义图作为任务计划的知识源。机器人技术中使用的其他AI技术包括自然语言在感知和动作方面的基础Mavridis和Roy(2006); Kollar等。 (2010年),动作和动作的计划(Wolfe等,2010年; Kaelbling和Lozano-Perez,2011年)以及根据逻辑约束生成机器人控制器(Kress-Gazit等,2009年)。
尽管这些系统在各自的领域都非常成功,但它们专注于知识的单个维度,例如知识领域。环境图或机器人动作。但是,自主地与对象交互的机器人通常会面临涉及多个维度的推理任务,例如,以推理任务中涉及的对象及其在环境中的最可能位置。因此,我们认为需要更全面的知识库和更多样化的推理技术来应对这些挑战。当设计一个完整的,集成的系统时,通常需要在针对特定问题进行了优化的技术与集成了各个组件的一致表示之间进行权衡。专为自主机器人设计的知识库(例如本文所述的KnowRob系统)试图解决这一挑战。在以下各段中,我们讨论了过去几年中为机器人开发的类似的集成知识处理系统。
ORO本体(Lemaignan等人,2010)专注于人机交互,并解决对话中的歧义。 例如,Ros等人(2010)描述了此功能,在此基础上,机器人根据对环境中的对象及其属性的了解推断出该机器人应询问的命令以消除歧义。 ORO使用OWL作为表示格式,并使用标准的DL推理器进行推理。 底层的三维几何环境表示可用于计算空间信息并更新有关对象位置的内部置信状态(Siméon等,2001)。
Daoutis等人(2009)提出的知识库是PEIS生态项目(物理嵌入式智能系统)的核心组成部分。 PEIS研究了分布式智能系统,这些系统既包括移动机器人,也包括嵌入环境的传感器,这些传感器都集成到一个通用框架中。 PEIS知识库是Cyc推理引擎的扩展。 一方面,这使系统可以完全访问大型Cyc本体,但是这样做的代价是推理速度较慢,本体的多个分支中不相关的知识以及在诸如机器人或移动操纵等领域缺乏知识。 作者专注于接地和锚固方面(另见Daoutis等人(2012))。
Lim等人(2011)的OUR-K系统是OMRKF框架Suh等人(2007)的继承者。 OUR-K是一个广泛的系统,描述了围绕五种主要知识的各个方面:上下文,对象,空间,动作和特征。 与KnowRob本体相比,OUR-K缺少流程,机器人自模型的概念,并且使用更简单的动作描述。 它也基于通用的OWL推理机,该推理机将推理功能限制为DL推理。
12. 讨论
现在让我们讨论我们做出的一些设计决策,其原理以及对机器人知识处理能力的影响。 也许,最具争议的决定可能是我们基于Prolog编程语言实现KnowRob的实现。
我们选择Prolog作为实用且可扩展的解决方案,用于在执行机器人计划的过程中“编程”查询答案和信息检索功能。即使存在更高级的知识表示语言和推理机制,也有多个原因使Prolog尤其具有吸引力。首先,因为我们希望KnowRob供机器人程序员和研究生使用,所以我们选择了一种成熟的语言,并为其提供了许多教科书。从我们的角度来看,第二个优点是Prolog的搜索机制,即具有回溯功能的深度优先搜索,使程序员能够通过对查询和规则的子句进行排序来控制搜索。程序员可以使用它来提高搜索效率,这是在计划执行期间执行查询回答的重要因素。对我们来说,另一个重要因素是外语界面的存在。从一开始就很明显,知识处理应该直接访问底层机器人控制系统的数据结构和计算过程。一个次要因素是OWL扩展包的可用性以及与高级智能系统基础结构(例如非结构化信息管理体系结构(UIMA))的接口(Ferrucci和Lally,2004年)。 SWI Prolog提供了大量接口和扩展库,到目前为止,满足了我们的需求,尽管还有其他一些系统,例如YAP(Costa等人,2012)或XSB(Swift和Warren,2012)在某种程度上更有效和可扩展。
选择Prolog还会带来一些后果。例如,Prolog缺乏专用的推理机制,例如不确定性推理,时间和空间推理,仅举几例。 KnowRob提供了这些推理功能,但仅在原子组合内。因此,为了进行一阶概率推理,KnowRob提供了一个谓词,该谓词将概率查询转换为马尔可夫逻辑问题,解决马尔可夫逻辑推理问题,并提取解决方案以实例化带有答案的查询谓词。马尔可夫逻辑推理通过过程附件集成在一起。这意味着马尔可夫逻辑推理机目前在推理不确定性时不进行其他任何推理,例如DL推理。 KnowRob方法的优势在于简单性,我们认为这在机器人控制方面至关重要。缺乏表现力通常可以通过精心设计查询来弥补,例如在设置不确定的推理问题之前解决所需的推论。
另一个问题是,Prolog的搜索策略(具有回溯功能的深度优先搜索)不完整。 这意味着即使答案存在,Prolog也可能永远搜索而不返回答案。 这个问题是一个理论上更大的问题,因为在实践中,必须仔细设计和优化机器人计划中的Prolog查询,以便它们在可用资源范围和时间限制内提供答案。
原则上,Prolog可用于实施完整的机器人控制程序。 例如,我们可以说Prolog规则是,如果打开瓶子后机器人看冰箱时机器人能看见瓶子,那么瓶子就在冰箱中。 因此,当被问及冰箱中是否有瓶子时,Prolog规则将要求机器人去冰箱,打开冰箱,然后寻找瓶子。 尽管这非常优雅,但它意味着该机器人将在不执行能够指定灵活和健壮行为的计划的控制下执行困难和复杂的操作。 为避免此问题,我们在计划中而不是在Prolog查询和规则中指定所有感知,导航和操纵操作。
在我们的用例中,我们很少遇到Prolog表达不足的情况。 这是因为过程附加方法允许程序员使用任意计算语义来指定谓词。 但是,在通过过程附件定义谓词的情况下,可能会发生谓词不能模块化且透明地表示其语义的情况。
最近,聘请了一批专家的软件体系结构证明了自己能够成功地扩展到现实世界的复杂性。 沃森系统(Ferrucci等人,2010)非常出色地展示了此类体系结构的潜力,沃森系统是赢得美国测验节目《危险! 我们计划探索向KnowRob添加一组基于专家的查询应答机制的可行性。 然后,系统将采用专家查询应答机制来检测它们可以处理的子查询,并假设这些子查询的答案。 在第二步中,查询答案机制将组合各个答案假设并以最高置信度计算答案。 这样的系统将有助于克服基于Prolog的推理的局限性,并包括其他推理机制。
未来几年最大的挑战之一将是使机器人能够理解并胜任模糊,未指定的任务指令。 这样的指令在人际交流中无处不在,因为当人们向另一个人解释任务时,他们通常会忽略他们认为是显而易见的常识的信息。 如果要自然地指导机器人,则他们将需要能够首先识别指令中丢失或模棱两可的信息,必须推理从何处获取此信息,以及如何将其集成到任务描述中。
这项挑战的主要部分是如何生成为机器人提供所需的各种信息所需的全面而多样的知识库。这将需要对学习进行更彻底的整合,而这在KnowRob系统中目前还不能很好地解决。尽管统计关系模型仍然面临可伸缩性问题,但它们是一个非常有前途的研究方向,因为它们将允许从数据中学习关系知识库。学习概率关系模型(Getoor等人,2003年)是一个非常活跃的研究领域,最近取得的成就的例子是在马尔可夫网络中进行结构学习的方法(Davis和Domingos,2010年),学习马尔可夫逻辑网络(Kiddon和Domingos, 2011年)和学习关系依赖网络(Natarajan等人,2012年)。虽然通常在马尔可夫逻辑网络中进行推理是很棘手的,但有希望的工作是找到一个易于处理的马尔可夫逻辑子集,同时仍将有用的领域划分为多个部分并将关系限制为部分的子部分。为统计关系模型开发可处理大量数据并作为机器人(软)实时高级控制回路一部分的学习和推理技术,将是重要的研究课题,也是我们研究议程的一部分。
这些学习技术很可能必须与其他知识获取方法相辅相成,这取决于要获取,表示和推理的信息类型。有关对象的知识库将需要表示它们的属性,其外观,它们的成分,有关易碎性或适当抓握点的信息,它们(功能)部分的组成以及与其他对象的关系。活动描述需要更好地表示任务上下文以及这些动作的符号或自然语言描述与人类演示和机器人体验的观察之间的关系。描述单个动作的知识库应提供有关动作属性和参数的信息,包括动作,对象,工具,位置和抓握类型之间的确切关系(Nyga和Beetz,2012年)。在较低的层次上,机器人需要可以从经验中学到的运动模型,如果新信息施加了额外的约束,可以由机器人的高级控制程序对其进行参数化,可以组成并适应变化的世界状态并进行抽象推理。这些方面尚未由KnowRob或我们知道的任何其他集成知识库处理,但实现这些模式的适当表示,学习和推理方法并向其填充内容对于构建智能机器人助手和同事至关重要。
13. 总结
在本文中,我们介绍了KnowRob作为自主机器人的实用知识处理系统。 它的主要概念之一是“虚拟知识库”,可以定义为亚符号数据之上的符号层。 在查询时,使用语义类和属性的过程附件将所需信息加载并抽象到适当的级别。 符号层用作集成不同知识源的语言,例如机器人的感知系统,控制程序的内部数据结构或来自Internet的信息。 如果知识库需要回答有关未知事物的查询,则可以将查询转发给其他组件以获取所需的信息。
KnowRob基于Prolog并在内部存储以DL表示的知识,该格式允许以非常结构化的方式表示信息,并且在充分的表现力和对自动推理的良好支持之间做出了很好的折衷。 关于对象和动作的类别的知识以本体的形式表示。 它提供了用于描述有关动作,事件,对象,空间和时间信息的知识的词汇表。 第3节中介绍了集成在KnowRob系统中的整体系统架构和知识获取,自动推理,可视化和信息查询的主要组件,以及可以使用的不同知识来源。
KnowRob集成了三种主要的推理技术,每种技术都适合于不同种类的知识:DL推理形成整个系统的主干,并用于所有确定性信息,包括大型本体。 对于概率信息的推理,我们集成了ProbCog工具箱,该工具箱提供了统计关系模型中各种推理方法,这些推理方法将一阶逻辑的表达能力与表示不确定性的能力相结合。 6.2节中描述的“可计算内容”允许在推理过程中按需进行语义信息的程序计算。 它们是从感知系统加载信息以及基于知识库中的信息计算实体之间关系的主要工具。
知识库和机器人感知组件之间的紧密集成允许基于对物体的检测来生成物体实例。 对于主动的,任务导向的感知系统以及记录所有感知结果的被动侦听器,存在两种接口。 提出的从Internet和人类观察中获取知识的技术以及在机器人之间交换知识的方法减少了构建大型知识库所需的时间。
在正在进行的研究中,我们正在努力开发能够在人类环境中执行实际任务的知识渊博,智能化的自主服务机器人。 对于这些任务,为机器人控制程序提供推理服务的综合知识库是重要的资源。 从机器人的知识推断控制决策会导致更健壮,灵活和可重复使用的行为,因为环境配置等方面是与控制流程分开描述的。 可以使用提出的(半)自动获取方法来获取以这种方式执行复杂任务的大量知识。
Notes
1.See http://ros.org/wiki/knowrob
2.See http://ias.in.tum.de/research/probcog
3.See http://ros.org/wiki/mod_probcog
4.See http://ros.org/wiki/knowrob_perception
5.See http://ros.org/wiki/tabletop_object_detector
6.See http://ros.org/wiki/comp_ehow
7.See http://ros.org/wiki/comp_germandeli
8.See http://ros.org/wiki/roboearth