一、简介
前面两篇文章我们围绕利用Python进行网络数据采集铺垫了很多内容,但光说不练是不行的,于是乎,本篇就将基于笔者最近的一项数据需求进行一次网络数据采集的实战;
二、网易财经股票数据爬虫实战
2.1 数据要求
在本部分中,我们需要采集的是海南板块中所有股票在2012年6月29日的所有指标数据,我们爬取的平台是网易财经,以其中一个为例:
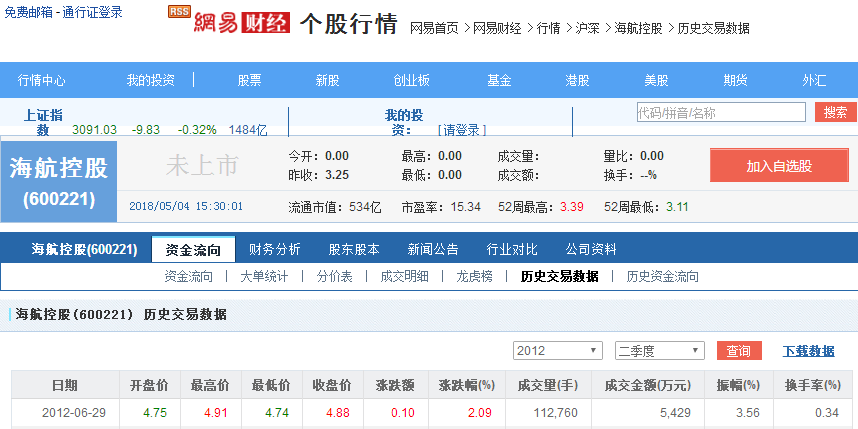
这是海南板块中的一支股票的历史数据页面http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=2,而我们需要的是海南板块所有只股票在2012年6月29日的这十个指标(开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%)),下面,我们分步骤分解及实现整个过程:
2.2 步骤1:获取所有股票代码
既然要利用到爬虫来自动化、批量化地获取数据,那我们需要依次爬取的html地址就需要预先创建好,先来观察网易财经历史数据页面的命名规则:

可以看出,网易财经的历史数据界面的命名规则为http://quotes.money.163.com/trade/lsjysj_ 加 股票代码 加 .html?year=年份&season=季度,因此对应我们的数据时期要求,年份取2012,季度取2,这样规则已经定好,唯一不确定的是股票代码,我从某金融软件下载了海南板块当前所有股票的交易数据(注意,该软件提供的历史交易数据维度不及网易财经网页中提供的丰富,所以我们才会需要爬取网页上的更丰富的内容),这些独立的文件所在文件夹如下:

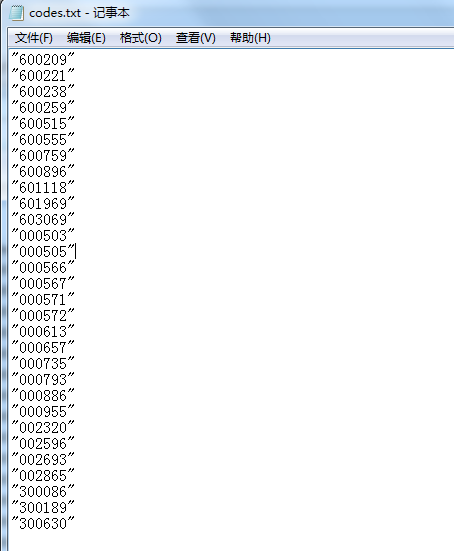
我们利用R来提取所有股票中数字代码部分,然后保存在一个txt文件中,代码如下:
rm(list=ls()) setwd('C:\Users\windows\Desktop\stock') #获取当前目录下所有文件的名称及扩展名(注意该文件夹下不要放除海南股票数据外其他文件) codes <- dir() #提取每一个文件名股票代码部分 C <- c() for(i in 1:length(codes)){ C[i] <- substr(codes[i],3,8) } df <- data.frame(codes=C) #写出为txt文件 write.table(df,file = 'codes.txt',row.names = F,col.names = F)
这样我们就得到了保存当前所有海南板块股票代码的txt文件:
接下来的工作就交给Python喽~
2.3 步骤2:目标网页地址的准备
先来用Python读入codes.txt文件内的股票代码:
'''设置股票代码文件所在路近''' path = 'C:\Users\windows\Desktop\stock\' '''读入股票代码文件,并按行分割为列表形式''' with open(path+'codes.txt') as c: code = c.readlines() '''打印code的内容''' print(code)
运行结果:

可以看出,换行符 ,双引号也被当成字符内容了,这时利用前面介绍的re.sub即可轻松将 和双引号部分删掉:
import re for i in range(len(code)): code[i] = re.sub('\n','',code[i]) code[i] = re.sub('"','',code[i]) print(code)
运行结果:

好了~,现在存放纯股票代码的列表已经生成,接下来需要做的就是生成我们的所有目标网址了:
htmls = [] '''利用字符串的拼接生成所有只股票对应的目标网页地址''' for i in range(len(code)): htmls.append('http://quotes.money.163.com/trade/lsjysj_'+code[i]+'.html?year=2012&season=2') print(htmls)
运行结果:

我们用浏览器随便打开一个网址试试:

2.4 步骤3:单个网址的连接与内容解析测试
我们所有目标网页的网址都生成完毕,下面开始建立与这些网址的连接并进行解析,当然,因为会有很多未知的错误发生,因此我们先以其中一个网址为例先做常规的测试:
from urllib.request import urlopen from bs4 import BeautifulSoup '''与第一个网址建立连接''' html = urlopen(htmls[0]) '''打印BeautifSoup解析后的结果''' print(BeautifulSoup(html))
运行结果:

可以看出,网页内容被成功的解析了出来,接下来我们来观察网页源代码,看看我们需要的内容藏在哪些标签下:

很轻易的就找到了,因为这个界面比较简单,如果遇到比较复杂的界面,可以在界面内ctrl+F的方式定位内容,根据我的观察,确定了变量名称和具体的日交易数据在标签tr下,但其每个数据都被包裹在一对标签内,因此,利用findAll()来对tr定位,得到返回值如下:
from urllib.request import urlopen from bs4 import BeautifulSoup'''与第一个网址建立连接''' html = urlopen(htmls[0]) obj = BeautifulSoup(html,'lxml') '''利用findAll定位目标标签及其属性''' obj.findAll('tr')
运行结果:
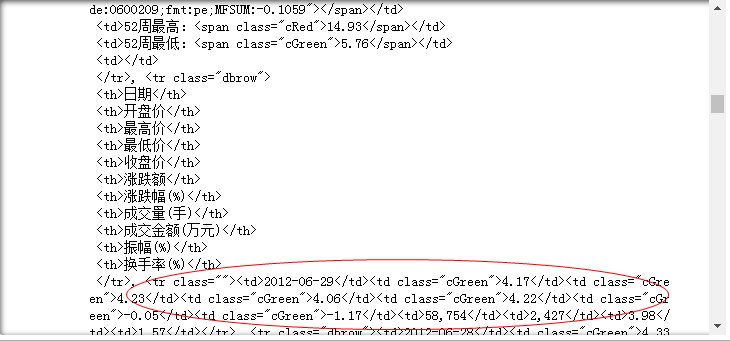
可以看到,我们的确获取到包含目标内容的区块,但是其前后都充斥着大量无关信息,因此需要使用正则表达式来精确地裁剪出我们想要的部分,因为我们需要的是2012-06-29的数据,而日期又是每一行数据的开头部分,因此构造正则表达式:
2012-06-29.*2012-06-28
进行更精确地信息提取:
from urllib.request import urlopen from bs4 import BeautifulSoup import re '''与第一个网址建立连接''' html = urlopen(htmls[0]) obj = BeautifulSoup(html,'lxml') '''利用findAll定位目标标签及其属性并返回其字符形式结果''' text = str(obj.findAll('tr')) '''利用日期间隔为正则表达式规则粗略提取内容''' target = re.findall('2012-06-29.*?2012-06-28',text)[0] print(target)
运行结果:

可以看出,除了<>内的标签内容外,其余的就是我们需要提取的内容,于是乎接下来我们继续利用re中的功能进行细致的提取:
'''将<>及内部标签内容替换为*以便下一步分割数据''' token = re.sub('<.*?>','*',target) '''以至少出现1次的*作为分割依据''' re.split('*+',token)
运行结果:

可以看出,该列表第2个到第11个元素即为我们需要的10个属性的值,
re.split('*+',token)[1:11]
运行结果:

2.5 步骤4:流水线式的全量爬虫任务构造
上面我们已经针对某一个样本基本实现了整个任务的要求过程,下面我们将网络数据采集的过程应用到所有股票上(这里要注意下,因为股票代码是当下获取的,而其中有些股票在2012年6月29日尚未上市,即针对其生成的网址是无效的,下面的程序中我也据此附上了对应的处理方法,请注意):
import re from bs4 import BeautifulSoup from urllib.request import urlopen '''设置股票代码文件所在路近''' path = 'C:\Users\windows\Desktop\stock\' '''读入股票代码文件,并按行分割为列表形式''' with open(path+'codes.txt') as c: code = c.readlines() '''得到干净的股票代码列表''' for i in range(len(code)): code[i] = re.sub('\n','',code[i]) code[i] = re.sub('"','',code[i]) htmls = [] '''利用字符串的拼接生成所有只股票对应的目标网页地址''' for i in range(len(code)): htmls.append('http://quotes.money.163.com/trade/lsjysj_'+code[i]+'.html?year=2012&season=2') '''利用循环完成所有页面的数据爬取任务''' '''创建保存对应股票数据的数据结构,这里选用字典,将股票代码作为键,对应交易数据作为值''' data = {} for i in range(len(code)): '''对2012年6月29日无交易数据的股票(即在爬取过程中会出错的网页)进行相应的处理''' try: '''与每次循环纳入的目标网页建立连接爬回朴素的网页信息''' html = urlopen(htmls[i]) '''对朴素的网页信息进行结构化解析''' obj = BeautifulSoup(html,'lxml') '''利用findAll定位目标标签及其属性并返回其字符形式结果''' text = str(obj.findAll('tr')) '''利用日期间隔为正则表达式规则粗略提取内容''' target = re.findall('2012-06-29.*?2012-06-28',text)[0] '''将<>及内部标签内容替换为*以便下一步分割数据''' token = re.sub('<.*?>','*',target) '''以至少出现1次的*作为分割依据分割为列表并返回需要的数据部分''' content = re.split('*+',token)[1:11] '''将得到的内容保存入字典中''' data[code[i]] = content '''当目标网页不存在2012年6月29日的数据时,传入字典对应的值为错误解释''' except Exception as e: data[code[i]] = '无2012年6月29日数据' '''打印结果''' print(data)
运行结果:

很顺利的,我们得到了字典形式的目标数据,下面利用一些基本操作将其整理为数据框的形式并保存为csv文件:
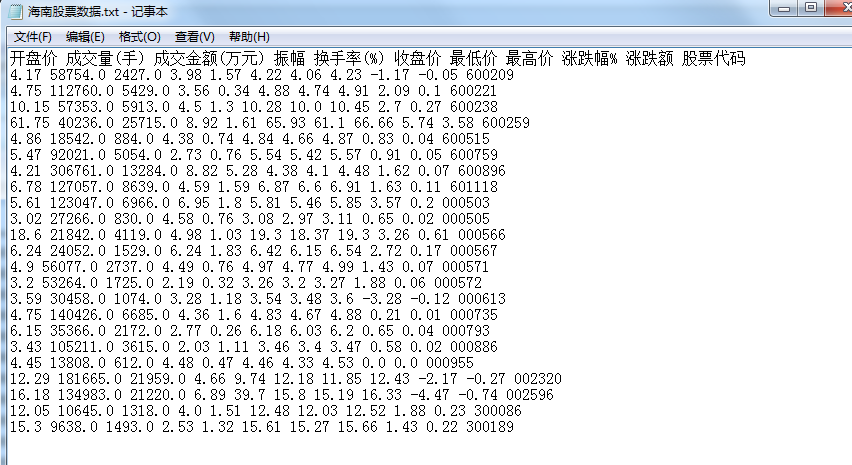
import pandas as pd import numpy as np import re stocks = {} for key,value in data.items(): if type(value) == list: for i in range(len(value)): value[i] = re.sub(',+','',value[i]) stocks[key] = list(map(float,value)) else: pass index = [] df = [[] for i in range(10)] for key,value in stocks.items(): index.append(key) for i in range(len(value)): df[i].append(value[i]) D = pd.DataFrame({'股票代码':index, '开盘价':df[0], '最高价':df[1], '最低价':df[2], '收盘价':df[3], '涨跌额':df[4], '涨跌幅%':df[5], '成交量(手)':df[6], '成交金额(万元)':df[7], '振幅':df[8], '换手率(%)':df[9]}) '''设置保存路径''' path = 'C:\Users\windows\Desktop\stock\' D.to_csv(path+'海南股票数据.txt',encoding='ANSI',sep=' ',index=False) D

生成的txt文件如下:
以上就是本次实战的内容,更多爬虫的技巧和奇妙之处,今后会在更多篇实战中介绍,敬请期待!