1 Postgre安装
Postgre安装
sudo apt-get update
sudo apt-get install postgresql
启动psql服务
sudo /etc/init.d/postgresql start
查看版本号,检查是否安装成功
psql --version
修改密码、选择postgres用户后,进入数据库命令行
lx@DESKTOP-AJIBU6Q:~$ passwd postgres
lx@DESKTOP-AJIBU6Q:~$ su postgres
postgres@DESKTOP-AJIBU6Q:/home/lx$ psql
psql (12.12 (Ubuntu 12.12-0ubuntu0.20.04.1))
Type "help" for help.
在命令行中查看数据存放地址
postgres=# SHOW data_directory;
data_directory
-----------------------------
/var/lib/postgresql/12/main
(1 row)
创建数据库testdb
postgres=# CREATE DATABASE testdb;
CREATE DATABASE
显示数据库表,检查是否创建成功。
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+---------+-----------------------
postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
(4 rows)
连接testdb
postgres=# \c testdb
You are now connected to database "testdb" as user "postgres".
2 Gist性能分析
2.1 B-tree
创建表t_test
testdb=# CREATE TABLE t_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE
生成随机数据并插入表
testdb=# insert into t_test SELECT generate_series(1,1000000) as key,repeat( chr(int4(random()*26)+65),4), (random()*(6^2))::integer,null,(random()*(10^4))::integer;
INSERT 0 1000000
查询AGE>30的数据项
testdb=# explain (analyze, costs off) select t.ID,t.NAME,t.AGE from t_test as t where t.AGE>30;
QUERY PLAN
-----------------------------------------------------------------------
Seq Scan on t_test t (actual time=5.941..370.128 rows=152324 loops=1)
Filter: (age > 30)
Rows Removed by Filter: 847676
Planning Time: 8.677 ms
Execution Time: 373.739 ms
(5 rows)
加载btree_gist插件,在AGE列上创建gist索引
testdb=# CREATE EXTENSION btree_gist;
testdb=# create index gist_btree on t_test using gist(AGE);
CREATE INDEX
再次以相同条件查询
testdb=# explain (analyze, costs off) select t.ID,t.NAME,t.AGE from t_test as t where t.AGE>30;
QUERY PLAN
----------------------------------------------------------------------------------------
Bitmap Heap Scan on t_test t (actual time=12.835..46.569 rows=152324 loops=1)
Recheck Cond: (age > 30)
Heap Blocks: exact=6370
-> Bitmap Index Scan on gist_btree (actual time=12.288..12.289 rows=152324 loops=1)
Index Cond: (age > 30)
Planning Time: 0.134 ms
Execution Time: 49.932 ms
(7 rows)
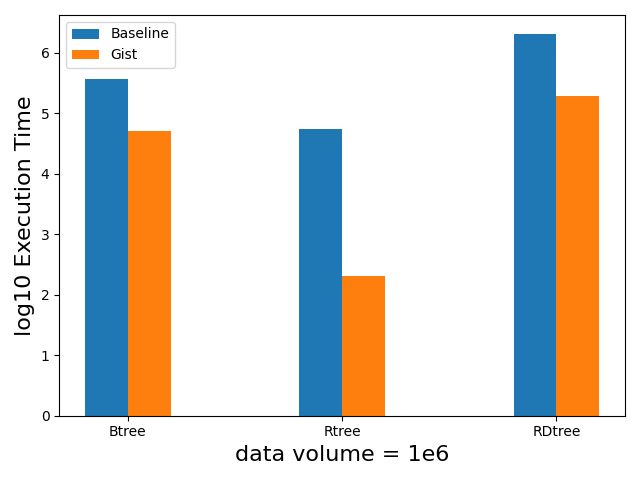
性能分析
2.2 R-tree
创建points表,随机生成point数据
testdb=# create table points(ID INT PRIMARY KEY NOT NULL, p point);
CREATE TABLE
testdb=# insert into points SELECT generate_series(1,1000000) as key, point((random()*(10^6))::integer,(random()*(10^6))::integer);
INSERT 0 1000000
查询矩形中包含的点的个数
testdb=# explain(analyse, costs off) select * from points where p <@ box '(1,1),(5000,5000)';
QUERY PLAN
------------------------------------------------------------------------------
Gather (actual time=1.492..45.785 rows=24 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on points (actual time=7.741..28.928 rows=8 loops=3)
Filter: (p <@ '(5000,5000),(1,1)'::box)
Rows Removed by Filter: 333325
Planning Time: 0.069 ms
Execution Time: 54.865 ms
(8 rows)
创建gist-rtree索引并再次以相同条件查询
testdb=# create index on points using gist(p);
CREATE INDEX
testdb=# explain(analyse, costs off) select * from points where p <@ box '(1,1),(5000,5000)';
QUERY PLAN
---------------------------------------------------------------------
---------------
Bitmap Heap Scan on points (actual time=0.021..0.074 rows=28 loops=1)
Recheck Cond: (p <@ '(5000,5000),(1,1)'::box)
Heap Blocks: exact=28
-> Bitmap Index Scan on points_p_idx (actual time=0.013..0.013 rows=28 loops=1)
Index Cond: (p <@ '(5000,5000),(1,1)'::box)
Planning Time: 0.108 ms
Execution Time: 0.092 ms
(7 rows)
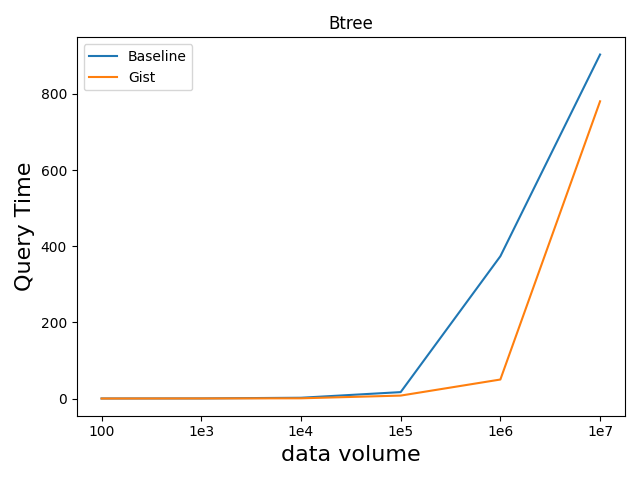
性能分析
2.3 RD-tree
导入数据、插入转化的词向量
数据集大小4430342,来源:https://www.kaggle.com/datasets/mikeortman/wikipedia-sentences
testdb=# \copy public.ts(doc) FROM 'data/wikisent2.txt'
COPY 4430342
testdb=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 4430342
查询文档中包含'database'的数据项
testdb=# explain(analyse, costs off) select * from ts where doc_tsv @@ to_tsquery('database');
QUERY PLAN
---------------------------------------------------------------------------------
Gather (actual time=165.833..2024.513 rows=3794 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on ts (actual time=131.282..1976.072 rows=1265 loops=3)
Filter: (doc_tsv @@ to_tsquery('database'::text))
Rows Removed by Filter: 1475516
Planning Time: 4.951 ms
Execution Time: 2027.597 ms
(8 rows)
在doc_tsv上创建gist-RDtree索引,并再次以相同条件查询
testdb=# create index on ts using gist(doc_tsv);
CREATE INDEX
testdb=# explain(analyse, costs off) select * from ts where doc_tsv @@ to_tsquery('database');
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on ts (actual time=172.624..192.250 rows=3794 loops=1)
Recheck Cond: (doc_tsv @@ to_tsquery('database'::text))
Rows Removed by Index Recheck: 1
Heap Blocks: exact=3264
-> Bitmap Index Scan on ts_doc_tsv_idx (actual time=172.305..172.305 rows=3795 loops=1)
Index Cond: (doc_tsv @@ to_tsquery('database'::text))
Planning Time: 6.457 ms
Execution Time: 195.731 ms
(8 rows)
3 实验总结
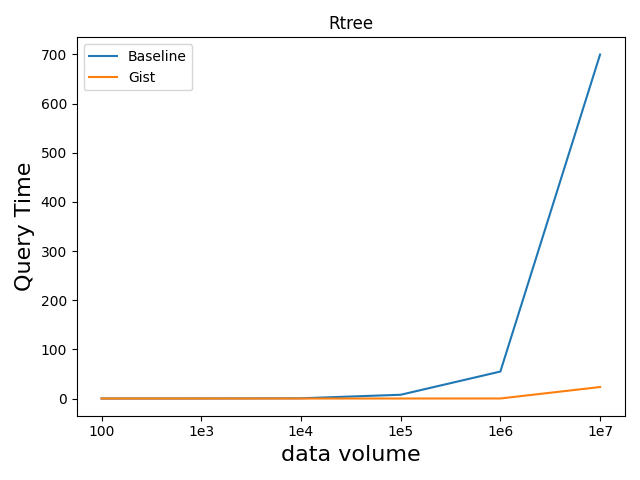
gist作为通用框架,能根据数据类型自动创建相应索引结构。在百万级别的数据上,有gist索引的查询相较于无索引直接查询有约10倍的性能提升,但创建索引会产生额外的空间开销,因此建议在被频繁查询的列上创建gist索引。