1.1基于贝叶斯决策理论的分类方法
我们称之为“朴素”,是因为整个形式化过程只做最原始、最简单的假设。
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
贝叶斯决策理论的核心思想:选择具有最高概率的决策。
1.2条件概率
条件概率,就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
条件概率的计算公式:
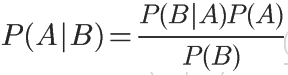
对条件概率公式进行变形,可以得到如下形式:
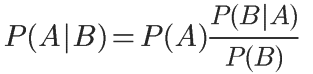
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件个概率分布做了条件独立性的假设。
比如下面的公式,假设有n个特征:
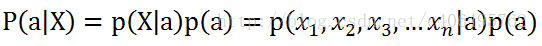
由于每个特征都是独立的,我们可以进一步拆分公式:

贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
朴素贝叶斯分类器通常有两种实现方式:一种基于贝努利模型实现,一种基于多项式模型实现。
代码
1 #词表到向量的转换函数 2 def loadDataSet(): #LoadDataSet()创建一些实验样本,切分的词条 3 postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], 4 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 5 ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 6 ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 7 ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 8 ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 9 classVec = [0, 1, 0, 1, 0, 1] #类别标签向量,1代表侮辱性词汇,0代表不是 10 return postingList, classVec 11 """ 12 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 13 Parameters: 14 vocabList - createVocabList返回的列表 15 inputSet - 切分的词条列表 16 Returns: 17 returnVec - 文档向量,词集模型 18 """ 19 def setOfWords2Vec(vocabList, inputSet): 20 returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量 21 for word in inputSet: #遍历每个词条 22 if word in vocabList: #如果词条存在于词汇表中,则置1 23 returnVec[vocabList.index(word)] = 1 24 else: print("the word: %s is not in my Vocabulary!" % word) 25 return returnVec #返回文档向量 26 """ 27 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 28 Parameters: 29 dataSet - 整理的样本数据集 30 Returns: 31 vocabSet - 返回不重复的词条列表,也就是词汇表 32 postingList是原始的词条列表,myVocabList是词汇表。 33 myVocabList是所有单词出现的集合,没有重复的元素 34 词汇表它是用来将词条向量化的,一个单词在词汇表中出现过一次, 35 那么就在相应位置记作1,如果没有出现就在相应位置记作0。trainMat是所有的词条向量组成的列表。 36 它里面存放的是根据myVocabList向量化的词条向量。 37 """ 38 def createVocabList(dataSet): 39 vocabSet = set([]) #创建一个空的不重复列表 40 for document in dataSet: 41 vocabSet = vocabSet | set(document) #取并集 42 return list(vocabSet) 43 44 if __name__ == '__main__': 45 postingList, classVec = loadDataSet() 46 print('postingList: ', postingList) 47 myVocabList = createVocabList(postingList) 48 print('myVocabList: ', myVocabList) 49 trainMat = [] 50 for postinDoc in postingList: 51 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) 52 print('trainMat: ', trainMat) 53 54 # if __name__ == '__main__': 55 # postingLIst, classVec = loadDataSet() 56 # for each in postingLIst: 57 # print(each) 58 # print(classVec) 59 60 import numpy as np 61 """ 62 函数说明:朴素贝叶斯分类器训练函数 63 Parameters: 64 trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 65 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec 66 Returns: 67 p0Vect - 侮辱类的条件概率数组 68 p1Vect - 非侮辱类的条件概率数组 69 pAbusive - 文档属于侮辱类的概率 70 """ 71 def trainNB0(trainMatrix, trainCategory): 72 numTrainDocs = len(trainMatrix) #计算训练的文档数目 73 numWords = len(trainMatrix[0]) #计算每篇文档的词条数 74 pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率 75 p0Num = np.ones(numWords); p1Num = np.ones(numWords) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑 76 p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑 77 for i in range(numTrainDocs): 78 if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· 79 p1Num += trainMatrix[i] 80 p1Denom += sum(trainMatrix[i]) 81 else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· 82 p0Num += trainMatrix[i] 83 p0Denom += sum(trainMatrix[i]) 84 p1Vect = np.log(p1Num/p1Denom) #取对数,防止下溢出 85 p0Vect = np.log(p0Num/p0Denom) 86 return p0Vect, p1Vect, pAbusive #返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率12345678910111213141516171819 87 88 # def trainNB0(trainMatrix, trainCategory): 89 # numTrainDocs = len(trainMatrix) #计算训练的文档数目 90 # numWords = len(trainMatrix[0]) #计算每篇文档的词条数 91 # pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率 92 # p0Num = np.zeros(numWords); p1Num = np.zeros(numWords) #创建numpy.zeros数组,词条出现数初始化为0 93 # p0Denom = 0.0; p1Denom = 0.0 #分母初始化为0 94 # for i in range(numTrainDocs): 95 # if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· 96 # p1Num += trainMatrix[i] 97 # p1Denom += sum(trainMatrix[i]) 98 # else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· 99 # p0Num += trainMatrix[i] 100 # p0Denom += sum(trainMatrix[i]) 101 # p1Vect = p1Num/p1Denom 102 # p0Vect = p0Num/p0Denom 103 # return p0Vect, p1Vect, pAbusive #返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率 104 105 if __name__ == '__main__': 106 postingList, classVec = loadDataSet() 107 myVocabList = createVocabList(postingList) 108 print('myVocabList: ', myVocabList) 109 trainMat = [] 110 for postinDoc in postingList: 111 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) 112 p0V, p1V, pAb = trainNB0(trainMat, classVec) 113 print('p0V: ', p0V) 114 print('p1V: ', p1V) 115 print('classVec: ', classVec) 116 print('pAb: ', pAb) 117 118 #使用分类器进行分类。 119 from functools import reduce 120 """ 121 函数说明:朴素贝叶斯分类器分类函数 122 Parameters: 123 vec2Classify - 待分类的词条数组 124 p0Vec - 侮辱类的条件概率数组 125 p1Vec -非侮辱类的条件概率数组 126 pClass1 - 文档属于侮辱类的概率 127 Returns: 128 0 - 属于非侮辱类 129 1 - 属于侮辱类 130 """ 131 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 132 p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1) 133 p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) 134 if p1 > p0: 135 return 1 136 else: 137 return 0 138 139 # def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 140 # p1 = reduce(lambda x, y: x*y, vec2Classify * p1Vec) * pClass1 #对应元素相乘 141 # p0 = reduce(lambda x, y: x*y, vec2Classify * p0Vec) * (1.0 - pClass1) 142 # print('p0:', p0) 143 # print('p1:', p1) 144 # if p1 > p0: 145 # return 1 146 # else: 147 # return 0 148 """ 149 函数说明:测试朴素贝叶斯分类器 150 Parameters: 151 无 152 Returns: 153 无 154 """ 155 def testingNB(): 156 listOPosts, listClasses = loadDataSet() #创建实验样本 157 myVocabList = createVocabList(listOPosts) #创建词汇表 158 trainMat=[] 159 for postinDoc in listOPosts: 160 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #将实验样本向量化 161 p0V, p1V, pAb = trainNB0(np.array(trainMat), np.array(listClasses)) #训练朴素贝叶斯分类器 162 testEntry = ['love', 'my', 'dalmation'] #测试样本1 163 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化 164 if classifyNB(thisDoc, p0V, p1V, pAb): 165 print(testEntry, '属于侮辱类') #执行分类并打印分类结果 166 else: 167 print(testEntry, '属于非侮辱类') #执行分类并打印分类结果 168 testEntry = ['stupid', 'garbage'] #测试样本2 169 170 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化 171 if classifyNB(thisDoc, p0V, p1V, pAb): 172 print(testEntry, '属于侮辱类') #执行分类并打印分类结果 173 else: 174 print(testEntry, '属于非侮辱类') #执行分类并打印分类结果 175 176 if __name__ == '__main__': 177 testingNB()