简要
在今天的数据中心的网络中,涉及到的网络设备是极其复杂多样的。一个大型的数据中心都有成百上千的节点,网卡,交换机,路由器以及无数的网线,光纤。在这些硬件设备基础上构建了很多软件,比如搜索引擎、分布式文件系统、分布式存储等等。在这些系统运行的过程中,面临一些问题:如何去测离网络时延,如何去判断一个故障时网络故障?如何去定位一个网络故障?如何定义和追踪网络的SLA?
基于这几点问题,微软设计开发了Pingmesh,展示了建立大规模网络延迟的测量和分析系统的可行性。
背景介绍
数据中心网络
常见的数据中心网络拓扑
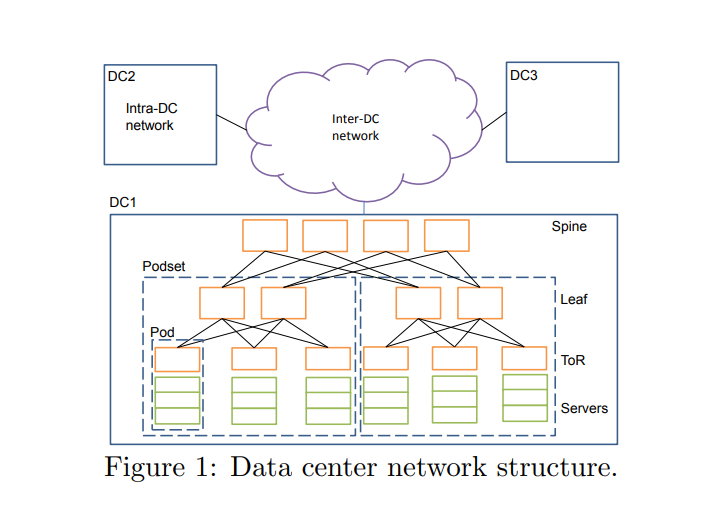
在这篇论文中,作者把网络分为两部分。
第一部分是intra data center (Intra-DC)network。
第二部分为 inter data center (Inter-DC)network
Intra—DC包含三层:
- Access Layer(接入层):有时也称为Edge Layer。接入交换机通常位于机架顶部,所以它们也被称为ToR(Top of Rack)交换机,它们物理连接服务器
- Aggregation Layer(汇聚层):有时候也称为Distribution Layer。汇聚交换机连接Access交换机,同时提供其他的服务,例如防火墙,SSL offload,入侵检测,网络分析等。
- Core Layer(核心层):核心交换机为进出数据中心的包提供高速的转发,为多个汇聚层提供连接性,核心交换机为通常为整个网络提供一个弹性的L3路由网络。
通常情况下,每组汇聚交换机管理一个POD(Point Of Delivery),每个POD内都是独立的VLAN网络。服务器在POD内迁移不必修改IP地址和默认网关,因为一个POD对应一个L2广播域。
汇聚交换机和接入交换机之间通常使用STP(Spanning Tree Protocol)。STP使得对于一个VLAN网络只有一个汇聚层交换机可用,其他的汇聚层交换机在出现故障时才被使用(上图中的虚线)。
网络延迟和数据包丢失
这里的网络延迟测离的是RTT。因为RTT测量不需要同步服务器时钟。
设计与实施
Pingmesh 是松耦合设计,每个组件都是可以独立运行的,分为三个组件,在设计的时候需要考虑几点:
- 因为要运行在所有的server上,所有不能占用太多的内存和计算资源。
- 需要时灵活配置的且高可用的
- 记录的数据需要进行合理的汇总分析
Pingmesh 构架设计
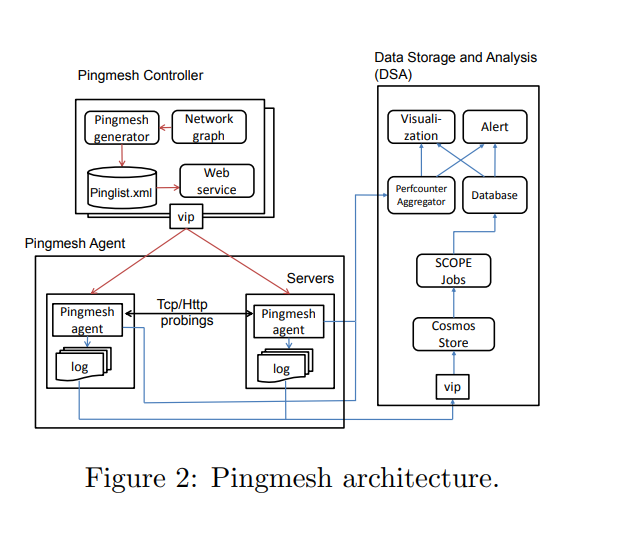
Pingmesh有三个部分组成,分别是Pingmesh Controller,Pingmesh Agent,Data Storage and Analysis.
Pingmesh Controller
它是整个系统的大脑,因为它决定了服务器应该如何相互探测。 在Pingmesh Controller中,Pingmesh Generator为每个服务器生成一个pinglist文件。 pinglist文件包含对等服务器列表和相关参数。 pinglist文件基于网络拓扑生成。 服务器通过RESTful Web界面获取相应的pinglist。
Pingmesh 生成原则
由于Pingmesh Agent 运行在所有的server上,Controller为了避免开销,抽象了三层完全有向图。
- 在机架内部,让所有的server互相ping,每个server ping(N-1)个server
- 在机架之间,则每个机架选几个server ping其它机架的server,保证每个server所属的ToR不同
- 在数据中心之间,则选择不同的数据中心的几个不同的机架的server 来 ping。
Pingmesh Agent
Pingmesh Agent的任务很简单:从Pingmesh Controller下载pinglist; ping pinglist中的服务器; 由于Pingmesh运行在所有服务器上,为了保证获取结果的真实的服务一致,Pingmesh 没有采用ICMP ping,而是采用的TCP/HTTP ping ,所有每个Agent即使Server也是Client。每个Ping动作都要开启一个新的连接,主要是为了减少Pingmesh造成的TCP并发。
Agent要保证自己是可靠的,不会造成一些严重的后果,其次要保证自己使用的资源足够少,毕竟运行在每个Server上。两个Server ping的周期最小是10s,packet大小最大64kb。针对灵活的配置需求,Agent会定期去Controller上拉去pinglist,如果三次拉取不到,哪么就会删除本地已有的pinglist,停止ping动作。
在进行ping动作后,会将结果保存在内存中,当保存结果超过一定的阈值或者达到了超时时间,就将结果上传到Cosmos(后面会介绍)中用于分析,如果上传失败,会有重试次数则数据丢弃,保证Agent的内存使用。
Data Storage and Analysis
对于数据的存储和分析,这篇论文使用现有的系统(Cosmos/SCOPE)和Autopilot Perfcounter(PA)。
Pingmesh代理会定期将时延记录上传到Cosmos。 与Pingmesh控制器类似,Cosmos的前端使用负载均衡和VIP(虚拟地址IP)进行扩展。 同时,Pingmesh 代理对延迟数据执行本地计算,并生成一组性能计数器,包括50%至90%的丢包率和网络延迟等。所有这些性能计数器都被收集,汇总和存储在Autopilot的PA服务。当收集到数据,Pingmesh有三种粒度对数据进行分析,分别以10min,1hour,1day的粒度进行统计汇总,数据的实时性最快也就是10min,Pingmesh还借助内部的基础设施能够拿到5min级别的数据结果。算是一种时间监控。
网络状况
根据论文中提到的,不同负载的数据中心的数据是有很大差异的,在 P99.9 时延时大概在 10-20ms,在 P99.99 延时大概在100+ms 。关于丢包率的计算,因为没有用 ICMP ping 的方式,所以这里是一种新的计算方式,(一次失败 + 二次失败)次数/(成功次数)= 丢包率。这里是每次 ping 的 timeout 是 3s,windows 重传机制等待时间是 3s,下一次 ping 的 timeout 时间是 3s,加一起也就是 9s。所以这里跟 Agent 最小探测周期 10s 是有关联的。二次失败的时间就是 (2 * RTT)+ RTO 时间。
Pingmesh 的判断依据有两个,如果超过就报警:
- 延时超过 5ms
- 丢包率超过 10^(-3)
在论文中还提到了其他的网络故障场景,交换机的静默丢包。有可能是 A 可以连通 B,但是不能连通 C。还有可能是 A 的 i 端口可以连通 B 的 j 端口,但是 A 的 m 端口不能连通 B 的 j 端口,这些都属于交换机的静默丢包的范畴。Pingmesh 通过统计这种数据,然后给交换机进行打分,当超过一定阈值时就会通过 Autopilot 来自动重启交换机,恢复交换机的能力。
总结
这篇论文的不足之处:
- 尽管Pingmesh能够检测到故障网络设备所在的层,但它无法确定准确的位置。
- 网络测量RTT只能测单次的。无法测出多次往返的情况。