1、加载和检查数据
经过前几次的学习,现在简单的代码就不注释了
加载数据:
insurance_filepath = "E:data_handle/insurance.csv" insurance_data = pd.read_csv(insurance_filepath)
检查数据:
#打印数据的前五行 print(insurance_data.head())
2、散点图
散点图的创建只需要一行代码就可以解决:
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
代码解析:
我们使用sns.scatterplot()创建一个简单的散点图,首先我们要确认X轴的列名和Y轴的列名,比如这里的
x=insurance_data['bmi'], y=insurance_data['charges' ]
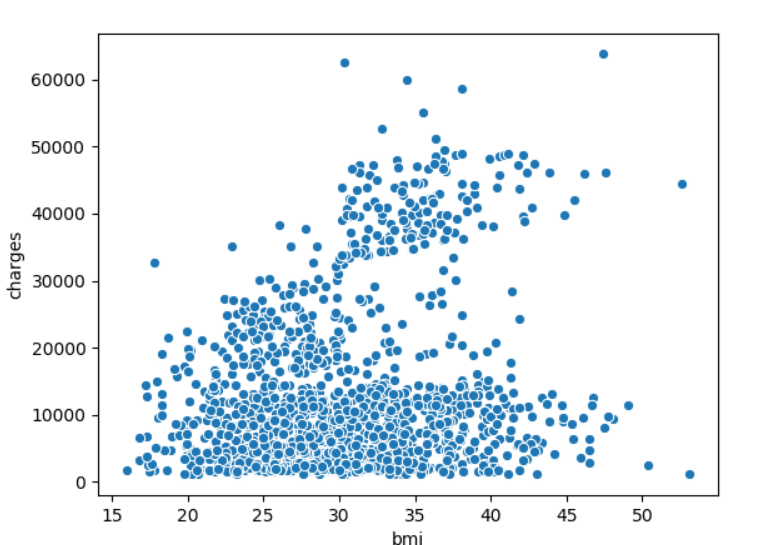
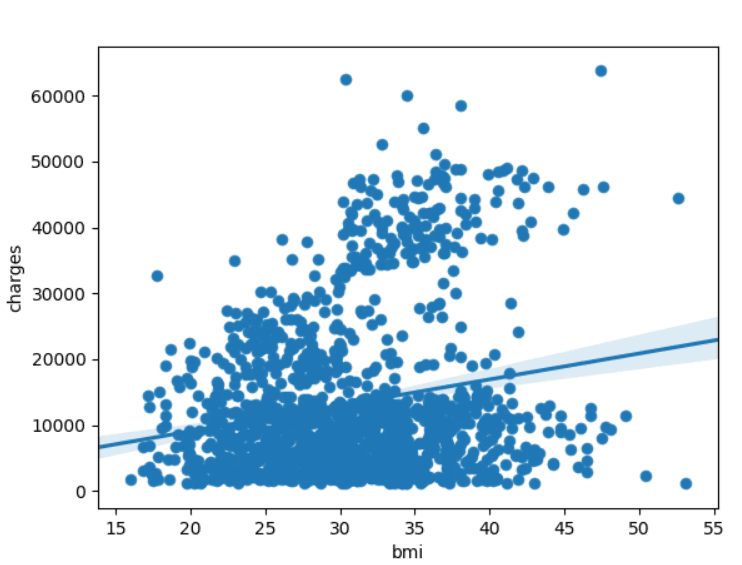
这时候我们发现散点图似乎呈现出一种正相关的关系,于是乎我们需要给它添加一条回归线,我们使用命令sns.regpolt()
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
3、颜色编码的散点图
我们可以使用散点图来显示三个变量之间的关系!一种方法是用颜色编码这些点。
例如,为了了解吸烟是如何影响BMI和保险成本之间的关系,我们可以用“吸烟者”来对这些点进行颜色编码,并在坐标轴上标出另外两列(BMI, charge)
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])

为了进一步强调这一事实,我们可以使用sns.lmplot添加两个回归线,分别对应于吸烟者和非吸烟者。
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)

代码分析:
大家有没有发现,这次我们所使用的确定列名与之前不同。
我们没有设置x=insurance_data['bmi']来选择insurance_data中的'bmi'列,而是设置x="bmi"来指定列的名称。
同样,y="charge "和hue=" smoking "也包含列的名称。
我们使用data=insurance_data指定数据集。
4、分类散点图
通常情况下,我们使用散点图来突出两个连续变量(如“bmi”和“charge”)之间的关系。
但是,我们可以调整散点图的设计,使其在一个主轴上显示一个分类变量(如“smoking”)。
我们将此图类型称为分类散点图,并使用sns.swarmplot来创建
sns.swarmplot(x=insurance_data['smoker'],y=insurance_data['charges'])
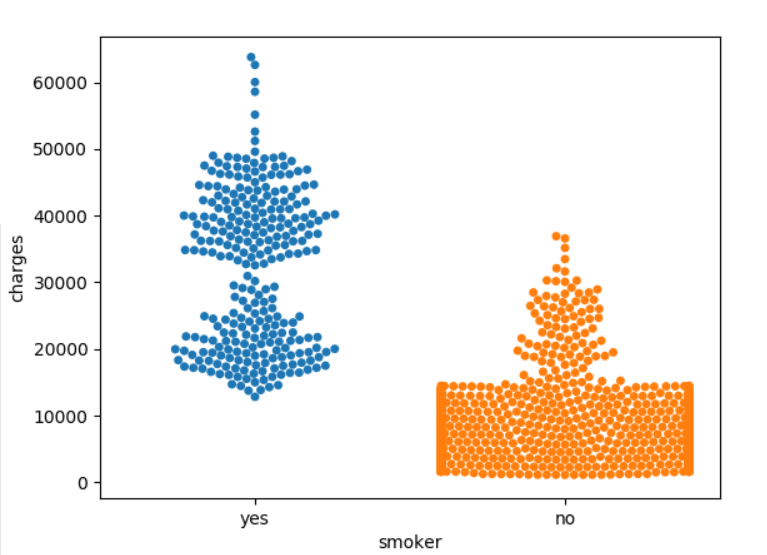
最后要告诉大家的是,图的输出语句为:
plt.show()